1>视图
视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】,
用户使用时只需使用【名称】即可获取结果集,可以将该结果集当做表来使用。
视图存储在硬盘上跟其他表不同,它值存放数据结构,而不存储数据,很显然,视图是一个
类似‘快捷键’的东西,每次执行视图查询,其实也就是重新执行一遍视图(语句),从真正的
表中获取数据,所以,它本身并不存放数据。
实际当中用的很少,因为若过分依赖视图这种强耦合关系(要根据视图sql查看其它表的数据),
会增加扩展数据库的难度。
增:CREATE VIEW 视图名称 AS SQL语句
改:我们不应该修改视图中的记录,而且在涉及多个表的情况下是根本无法修改视图中的记录的
删:DROP VIEW 视图名称
查:查询语法类似sql语句的查询语法,如 select * from 视图名称

2>触发器
使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询
增:如下, 在每次插入数据之前触发这段sql的执行
CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW
BEGIN
...
END
创建触发器实例
delimiter //
CREATE TRIGGER tri_after_insert_cmd AFTER INSERT ON cmd FOR EACH ROW
BEGIN
IF NEW.success = 'no' THEN #等值判断只有一个等号
INSERT INTO errlog(err_cmd, err_time) VALUES(NEW.cmd, NEW.sub_time) ; #必须加分号
END IF ; #必须加分号
END//
delimiter ;
因语句里面有多行带分号,分号是sql的结束符号,所以再实体触发器的首尾加上delimiter标识,后面可以用
//或者其他符号作为开始和结束符号,结尾必须用 delimiter ;收尾,
NEW表示即将插入的数据行,OLD表示即将删除的数据行。
删:drop trigger tri_after_insert_cmd;
查:触发器是被动触发的,无法直接查询。
3>事物
事务用于将某些操作的多个SQL作为原子性操作,即一旦有某一个出现错误,即刻回滚
到原来的状态,从而保证数据库数据完整性。
设想银行转账的例子:1>账户转出1000,2>对端账户收取1000,这两步就应该作为原子性操作,
若有任何1步失败,则所有步骤均失败(回滚操作或者不执行),就不会出现类似“若有网络延迟问题,
导致A账户转出了1000,即DB.A减了1000,而DB.B账户未增加1000”的问题。
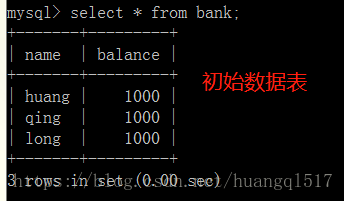
start transaction;
update bank set balance=500 where name='huang'; # 支付500元
update bank set balance=1200 where name='qing'; # 平台收取200元
update bank set balance=1300 where name='long'; # 卖家收取300元
rollback;
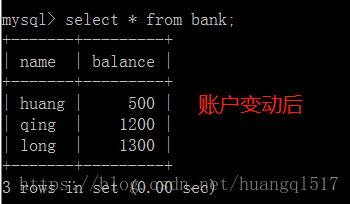
注意这个commit,在commit之前,有个回滚机制,即当sql语句执行出现问题,可以rollback;回滚到
事物内所有sql执行之前的状态,一旦commit之后,数据就不能回滚了,
事物跟触发器结合使用,如下,触发器中加入回滚和提交机制,让程序根据sql执行结果自动调取。

4>存储过程
存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql
先说下程序与数据库结合的三种方式

方式一:MYsql这边负责写存储过程,应用程序开发这边只需调接口(存储过程),对于应用程序开发来说,
很方便,开发效率高,但是后期若要改动,可能需要跟DBA做大量的沟通,数据库专职管理人员才会做修改,
所以,扩展难,若部门之间沟通协调做的极好,可以用这种方式,
方式二:鉴于方式一有一种部门“依赖关系”,很明显,跟我们现在的‘敏捷’是不太匹配的,所以,应用
开发这边自己编写sql语句,长长的一大串的sql语句,缺点很明显,这种sql执行肯定没存储过程快,而且
应用程序编写sql肯定没专业的DBA这么专精,导致会耗费一部分SQL编写时间,
方式三:鉴于方式二的缺点,又优化了下,成了方式三,应用程序这边依然自己写SQL,不过是根据ORM模型
自己编写类去实现,简单来说就是比方式二在写SQL方面更加‘轻松’,但是执行效率是最慢的,因为,基于这
个ORM模型写的‘类’或者‘对象’还得转换成真正的,可以用于执行的sql,中间还多了一部‘转换’过程,
所以执行速度最慢,但是,但是,方式三恰恰就是现今使用最广的方法。
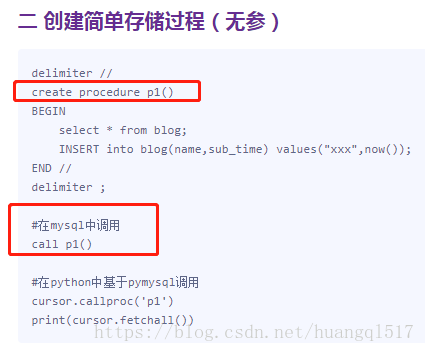
删:drop procedure proc_name;
5>函数



