1.查看版本
import sys
print(sys.version)
# 3.7.5 (default, Oct 31 2019, 15:18:51) [MSC v.1916 64 bit (AMD64)]
print(sys.version_info)
# sys.version_info(major=3, minor=7, micro=5, releaselevel='final', serial=0)
2.PEP8风格
- 【空格】文件的函数和类之间使用两个空格
- 【空格】同一个类,不同方法之间一个空格
- 【命名】函数、变量、属性使用小写字母和下划线
- 【命名】受保护的实例属性,使用单下划线开头;私有的双下划线
- 【命名】类与异常的每个单词开头均大写
- 【表达式和语句】使用内联形式的否定词,而不要把否定词放前面。
推荐:if a is not b
不推荐:if not a is b
- 【表达式和语句】不要通过检测长度来判断空。
推荐:if not somelist
不推荐:if len(somelist)==0
- 【表达式和语句】import语句顺序
import 标准库模块(首字母顺序)
import 第三方模块
import 自用模块
3.bytes、str与unicode
Python3 有两种表示字符序列的类型:bytes 和 str
print(type(b'hello')) # <class 'bytes'>
print(type('hello')) # <class 'str'>
print(type(u'hello')) # <class 'str'>
编码:Unicode字符 ⇒ Bytes
解码:Bytes ⇒ Unicode字符
rint('hello'.encode('utf8')) # b'hello'
print(b'hello'.decode('utf8')) # 'hello'
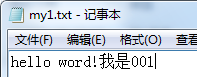
文件操作:str内容
with open("my1.txt",'w') as f: # 默认会采用UTF-8编码格式,encoding="utf-8"
f.write("hello word!我是001")
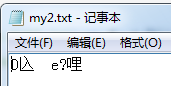
文件操作:bytes内容
import os
with open("my2.txt",'wb') as f:
f.write(os.urandom(10)) # Return a string of n random bytes
5. 切割序列
使用切片赋值时,长度可以不一致。
a=[1,2,3,4,5]
a[1:3] = [0,0,0,0]
print(a)
结果:[1, 0, 0, 0, 0, 4, 5]
但是使用索引赋值,则只能元素赋值,或者把一个列表作为一个元素
b=[1,2,3,4,5]
b[0] = [0,0,0,0]
print(b)
结果:[[0, 0, 0, 0], 2, 3, 4, 5]
7.使用列表推导取代map和filter-更简洁
a = [1,2,3,4,5,6,7]
even_squares = [x**2 for x in a if x%2==0] # for循环,if判断
print(even_squares) # [4, 16, 36]
alt = list(map(lambda x:x**2,filter(lambda x:x%2==0,a))) # 先使用filter筛选,再使用map处理,再转为list
print(alt) # [4, 16, 36]
8.多级列表推导
列表推导支持多级循环,每级循环也支持多项条件,但是更推荐拆开写。
matirx = [[1,],[4,5],[7,8,9]]
filtered= [x for row in matirx if len(row)>1 for x in row if x >7]
print(filtered)
9.使用生成器表达式来改写数据量较大的列表推导
例如读取一份文件并返回其中每行的字符数,若采用列表推导,就需要把每行的长度都保存在内存中,但是文件特别大就会出现问题。如果把列表的中括号换成圆括号,返回的就是生成器,这样每次只计算当前行的字符数,避免了内存不足的问题。
文件内容:
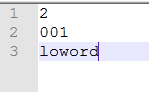
val = [len(x) for x in open('my1.txt')]
print(val) # [2, 4, 6]
gen = (len(x) for x in open('my1.txt'))
print(next(gen))
print(next(gen))
print(next(gen))
# 2
# 4
# 6
10.尽量用enumerate取代range
enumerate(list,start_id)可以指定起点索引,一般为0。但是只能访问整个列表,其实用到不多。
list = [1,2,3,4,5,6]
for i,val in enumerate(list,1):
print('%d:%s'%(i,val))
# 1:1
# 2:2
# 3:3
# 4:4
# 5:5
# 6:6
11.使用zip同时访问两个迭代器
a_list = [1,2,3]
b_list = [1,2,3,4,5]
for a,b in zip(a_list,b_list):
print(a,b)
# 1 1
# 2 2
# 3 3
使用itertools.zip_longest可以按照更长的输出
import itertools
for a,b in itertools.zip_longest(a_list,b_list):
print(a,b)
# 1 1
# 2 2
# 3 3
# None 4
# None 5
13.合理使用try/except/else/final
try:
normal excute block 正常执行的程序
except A:
Except A handle 出现异常A
except B:
Except B handle 出现异常B
except:
other exception handle 出现其他异常
else:
if no exception,get here 无异常时执行
finally:
print(hello world) 最后总会执行
