目录:
- 什么是索引
- B-Tree索引
- Hash索引
- 聚簇索引
- 补充
什么是索引
索引是存储引擎用于快速找到记录的一种数据结构,这是索引的基本功能。
索引对于性能来说非常关键,好的索引能在大量数据中快速检索出结果;但不恰当的索引还可能会降低检索数据的性能。
B-Tree索引
B-Tree索引其实是一个数据,每个存储引擎的实现各不相同,如InnoDB使用的B-Tree其实使用的是B+Tree。
B-Tree索引适用于全键值、键值范围或键前缀查找,其中键前缀查找只适用于根据最左前缀的查找。
———————————————————————————————————————————————————————
示例:
DROP TABLE IF EXISTS t_customers; CREATE TABLE t_customers ( `id` BIGINT (20) UNSIGNED PRIMARY KEY NOT NULL AUTO_INCREMENT COMMENT 'id', `user_name` VARCHAR (10) NOT NULL DEFAULT '' COMMENT '客户姓名', `age` TINYINT NOT NULL DEFAULT 0 COMMENT '年龄', `email` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '邮箱', `nick_name` VARCHAR (20) NOT NULL DEFAULT '' COMMENT '用户昵称', `create_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' ) ENGINE = INNODB DEFAULT CHARSET = utf8mb4 COMMENT '协议支付记录表'; ALTER TABLE t_customers ADD INDEX IDX_CUSTOMERS_AGE(age), ADD INDEX IDX_CUSTOMERS_USER_NAME_AGE_EMAIL(user_name, age, email); INSERT INTO t_customers ( user_name, age, email, nick_name ) VALUES ( '张三', 10, '[email protected]', 'zhangsan' ), ( '李四', 14, '[email protected]', 'lisi' ), ( '王五', 30, '[email protected]', 'wangwu' ), ( '孙七', 10, '[email protected]', 'sunqi' ), ( '周八', 20, '[email protected]', 'zhouba' ), ( '吴九', 55, '[email protected]', 'wujiu' ), ( '郑十', 47, '[email protected]', 'zhengshi' );
索引生效的情况(针对组合索引):
- 匹配最左前缀
- 全值匹配
- 匹配列前缀
- 匹配范围值
- 精确匹配某一列并范围匹配另外一列
-- 【匹配最左前缀(对于组合索引来说,组合的顺序是非常重要的,根据顺序查询才能够使用索引)】 -- 索引级别:ref,生效 EXPLAIN SELECT * FROM t_customers WHERE user_name = '王五'; -- 索引级别:ref,生效 EXPLAIN SELECT * FROM t_customers WHERE user_name = '王五' AND age = '30' AND email = '[email protected]'; -- 【全值匹配】 EXPLAIN SELECT * FROM t_customers WHERE user_name = '周八'; -- 索引级别:ref,生效 -- 【匹配列前缀(LIKE 'xx%'可以生效,LIKE '%xx'不走索引)】 -- 索引级别:range,生效 EXPLAIN SELECT * FROM t_customers WHERE user_name LIKE '王%'; -- 索引级别:all,生效 EXPLAIN SELECT * FROM t_customers WHERE user_name LIKE '%五'; -- 【匹配范围值(但范围超过MySQL阀值也会全表扫描)】 -- 索引级别:range,生效 EXPLAIN SELECT * FROM t_customers WHERE age > 30; -- 索引级别:all,超过阀值,全表扫描,不生效 EXPLAIN SELECT * FROM t_customers WHERE age > 20; -- 【精确匹配某一列并范围匹配另外一列】 EXPLAIN SELECT * FROM t_customers WHERE user_name = '王五' AND age > '30';
B-Tree索引的限制(针对组合索引,注意此处需要将age索引注释调重执行DDL):
- 如果不是按照索引的最左列开始查找,则无法使用索引
- 不能跳过索引中的列
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找
-- 【如果不是按照索引的最左列开始查找,则无法使用索引】 -- 索引级别:ALL,不生效 EXPLAIN SELECT * FROM t_customers WHERE email = '[email protected]'; -- 【不能跳过索引中的列】 -- 索引级别:ref,生效(但通过执行计划可以看出,key_len=42;use_name长度为10,一个中文占4个字节,所以是40多,而key_len=42,所以email未使用索引) EXPLAIN SELECT * FROM t_customers WHERE user_name = '王五' AND email > '[email protected]'; -- 这样不跳过索引中的列,key_len=245,三个索引都用了 EXPLAIN SELECT * FROM t_customers WHERE user_name = '王五' AND age = 30 AND email = 'wangwu@qq/com'; -- 【如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找(key_len=43,email未使用索引,对比SQL见上面那条)】 EXPLAIN SELECT * FROM t_customers WHERE user_name = '王五' AND age > '30' AND email = 'wangwu@qq/com';
Hash索引
Hash索引基于Hash表实现,需要精确匹配所有的列方能生效。
同时对于每行数据来说,存储引擎会计算所有索引列的Hash码。(如索引为:name,age,则其Hash码为name+age)
Hash索引将Hash码存储在索引中,同时在Hash表中保存所有数据的指针。
注意:MySQL中Hash索引只在Memory引擎中实现了。当然InnoDB也有一个类似的,自适应Hash索引。
———————————————————————————————————————————————————————
优点:因为Hash表只存储对应的Hash值,所以索引得结构十分紧凑。这也是为什么Hash索引的查找速度那么快的原因了。
缺点:
- 因为Hash索引只存储了Hash值和行指针,所以在读取数据的时候不能够通过索引来避免全行数据的读取。
- Hash索引值不是按照顺序排序的,所以对数据排序时无法用到索引。
- 不支持部分索引查找,必须精确匹配所有的索引列。
- 索引只支持等值比较,如=、in、<=>,不支持任何范围查找。
- 当Hash冲突较多时,不仅速度不会快,还会增加索引维护成本。
聚簇索引
聚簇索引由存储引擎实现,故并非所有的存储引擎都支持聚簇索引,MySQL中InnoDB的聚簇索引其实就是主键索引。
InnoDB通过主键聚集数据,如果没有定义主键则会选择一个非空的所有代替,如果没有这样的索引则会隐式的定义一个主键作为聚簇索引。
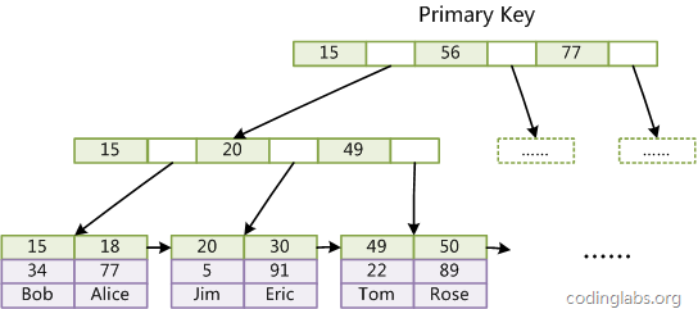
如图,聚簇索引通过以主键为key,将其一列数据聚集起来,这样查询的时候只要找到主键所在的位置,然后根据指针就能非常迅速的定位到其所有的数据。
例:id=15,便能够轻松得到这一列数据,15,34,Bob。
图中15、18为一页数据,20、30为另一页数据,InnoDB中一页数据大小为16KB。
———————————————————————————————————————————————————————
优点:
- 我们知道,InnoDB会预读,每次读一页数据;而聚簇索引可以将相关的数据保存在一起,减少磁盘IO次数。
- 它将索引和数据存储在同一个BTree中,所以性能要比非聚簇索引好。
缺点:
- 它极大的提高了IO密集型应用的性能,但数据都在内存中时聚簇索引也就没啥优势了(但你内存能有多大呢,所以聚簇索引利大于弊)。
- 插入数据的速度严重依赖于插入数据的顺序、更新聚簇索引列的代价比较高,为了保证每页数据都是有序的,在更新和插入数据的时候可能会出现页分裂的问题。页分裂会导致表占用更多的磁盘空间,且分裂的页数据不满,需要重建索引(当然如果你的主键列是自增的话,那么这个问题也是不存在的)。
-
聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候。(同样可以通过主键自增来解决)
- 聚簇索引的二级索引可能比想象的要更大,因为在二级索引的叶子节点包含了引用行的主键列值。
-
二级索引访问需要两次索引查找,而不是一次( 二级索引保存的不是指向物理行的位置,而是行的主键值)
———————————————————————————————————————————————————————
二级索引:
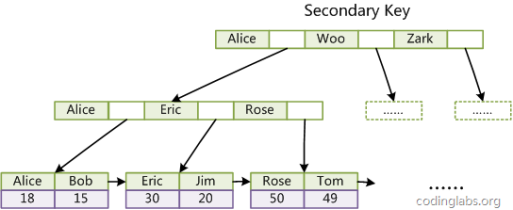
可以通过这样的SQL来解决聚簇索引中二级索引访问时查找两次的问题:SELECT id,name FROM tablename WHERE name = ’Rose’;
补充
1、多条件查询时,是否充分利用了组合索引的特性。
———————————————————————————————————————————————————————
2、索引中的数据顺序和查找中的排列顺序一致:如name是索引,根据name查询,但是按照了email排序,那这也不是最优的;order by后面跟的最好是索引列。
SELECT id, name, email FROM t_table_name WHERE name = 'xxx' ORDER BY name;
SELECT id, name, email FROM t_table_name WHERE name = 'xxx' ORDER BY email;
———————————————————————————————————————————————————————
3、索引中的列包含了查询中需要的全部列:如查询了id,name,age三个列,索引只有id,name的话,那这就不是最优的。
SELECT id, name, age FROM t_table_name;