PS:看这篇文章之前,要把上一篇文章看完哦,这样更好理解~~
上一篇文章链接:一篇比较全的HTTP协议详解(1)
文章目录
1.HTTP是一种无状态协议
1.1 概念
无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。即我们给服务器发送 HTTP 请求之后,服务器根据请求,会给我们发送数据过来,但是,发送完,不会记录任何信息。服务器无法知道两个请求是否来自同一个浏览器,即服务器不知道用户上一次做了什么,每次请求都是完全相互独立。
1.2 无状态的优缺点
缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。例如:当我们登录一个网站时,我们设置了自己的喜好,当我们关闭这个网页时,下次再登录,就又得重新设置。这是不是显得很麻烦?
客户端与服务器进行动态交互的 Web 应用程序出现之后,HTTP 无状态的特性严重阻碍了这些应用程序的实现,毕竟交互是需要承前启后的,简单的购物车程序也要知道用户到底在之前选择了什么商品。于是,两种用于保持 HTTP 状态的技术就应运而生了,一个是 Cookie,而另一个则是 Session。
2. 解决HTTP无状态的问题
2.1 cookies
Cookie是由服务器发给客户端的特殊信息,而这些信息以文本文件的方式存放在客户端,然后客户端每次向服务器发送请求的时候都会带上这些特殊的信息,用于服务器记录客户端的状态。
Cookie可以保持登录信息到用户下次与服务器的会话,换句话说,下次访问同一网站时,用户会发现不必输入用户名和密码就已经登录了(当然,不排除用户手工删除Cookie)。而还有一些Cookie在用户退出会话的时候就被删除了,这样可以有效保护个人隐私。
Cookie主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
这里再举一个用户登录的例子,方便大家理解:用户在输入用户名和密码之后,浏览器将用户名和密码发送给服务器,服务器进行验证,验证通过之后将用户信息加密后封装成Cookie放在响应头中返回给浏览器。
HTTP/1.1 200 OK
Content-type: text/html
Set-Cookie: user_cookie=Rg3vHJZnehYLjVg7qi3bZjzg; Expires=Tue, 8 Feb 2020 21:47:38 GMT; Path=/; Domain=.169it.com; HttpOnly
[响应体]
浏览器收到服务器返回数据,发现响应头中有一个:Set-Cookie,然后它就把这个Cookie保存起来,下次浏览器再请求服务器的时候,会把Cookie也放在请求头中传给服务器:
GET /sample_page.html HTTP/1.1
Host: www.example.org
Cookie: user_cookie=Rg3vHJZnehYLjVg7qi3bZjzg
[请求体]
服务器收到请求后从请求头中拿到cookie,然后解析并到用户信息,说明此用户已登录,Cookie是将数据保存在客户端的。
这里我们可以看到,用户信息是保存在Cookie中,也就相当于是保存在浏览器中,那就说用户可以随意修改用户信息,这是一种不安全的策略!
Cookie是有期限的,过了期限之后,Cookie就会失效。或者人为的也可以删掉。
PS:上面的报文段只是简略的(便于理解Cookies工作),详细的可以自己尝试登录,然后用Chorm开发人员分工具——右键,检查,network,Headers,去看看具体流程。
2.2 session
Session翻译为会话,服务器为每个浏览器创建的一个会话对象,浏览器在第一次请求服务器,服务器便会为这个浏览器生成一个Session对象,保存在服务端,并且把Session的ID发送给客户端浏览器,而以用户显式结束或session超时为结束。
- 当一个用户向服务器发送第一个请求时,服务器为其建立一个session,并为此session创建一个标识号(sessionID)。
- 这个用户随后的所有请求都应包括这个标识号(sessionID)。服务器会校对这个标识号以判断请求属于哪个session。
对于session标识号(sessionID),有两种方式实现:Cookie和URL重写。
Cookie:读者应该想到了,对,服务端只要设置Set-cookie头就可以将session的标识符传送到客户端,而客户端此后的每一次请求都会带上这个标识符,由于cookie可以设置失效时间,所以一般包含session信息的cookie会设置失效时间为0,即浏览器进程有效时间。至于浏览器怎么处理这个0,每个浏览器都有自己的方案,但差别都不会太大(一般体现在新建浏览器窗口的时候);
URL重写:所谓URL重写,顾名思义就是重写URL。试想,在返回用户请求的页面之前,将页面内所有的URL后面全部以get参数的方式加上session标识符(或者加在path info部分等等),这样用户在收到响应之后,无论点击哪个链接或提交表单,都会在再带上session的标识符,从而就实现了会话的保持。读者可能会觉得这种做法比较麻烦,确实是这样,但是,如果客户端禁用了cookie的话,URL重写将会是首选。
3.URL详解

- Scheme:协议名称,是用来指定使用的传输协议,其中最常见的就是HTTP协议。其他常用的协议还有:
| file: | 用于访问资源位于本地计算机上的文件 |
|---|---|
| ftp: | 用于访问FTP服务器上的资源 |
| https: | 通过SSL协议的HTTP访问Web服务器资源 |
| mailto: | 访问资源属于电子邮件地址,通过SMTP协议访问 |
- //:层级URL的标记符号,根据RFC 1738规定的语法,在授权信息之前,每个层级结构的URL中都会包括固定的”//“符号。
非层级结构URL:mailto: - login:password:访问资源的身份验证。在URL中,身份认证属于可选项,在向服务器申请资源时,在某些情况下,需要指定一个用户民和密码。如果没有身份验证字段,浏览器默认以匿名方式访问资源。(这个基本不会用到)
PS:有些需要登录的页面,需要输入用户名和密码才能登录。你也可以选择把用户名和密码放在URL中传过去 - address:域名部分(或者IP地址)。就是你要访问的服务器的地址,一般来说我们用的是域名。
port:服务器端口,是可选内容,在没有指定端口时,会默认去访问协议的标准端口。例如:HTTP的端口是80,HTTPs的标准端口是443,FTP的标准端口是21 - /path/resource:层级文件路径,就是你要访问服务器上面的什么资源。类似于我们访问自己电脑里面的文件时,就会有一个路径,例如:D:\qycache\download。而这里的路径定义是来源于UNIX,所以保留了对 “/”的支持。
- ?query_string :查询字符串,非必要字段,主要负责将一系列非层级格式的任意参数传递给指定的服务器。格式为:
?参数名=值
当想要传递的参数不止一个时,用“&”连接。
例如:search?q=淘宝&oq=淘宝&sourceid=chrome&ie=UTF-8
- #fragment:非必要字段,他应用于客户端,片段ID的值是不会传至服务器的。在实际场景下,片段ID一般用于指向页面中某个锚点,将片段ID与预先设置的锚点名称匹配,并滚动到相应位置。就是说,#fragment会实际指向页面的某一处,但只在客户端显示。
PS:我们实际在浏览器中填写的,大部分是直接填写域名或者想要搜索的内容即可,其他的部分,聪明的浏览器会自动为我们加上。
4.HTTP是无连接的
无连接:服务器处理完客户的请求,并收到客户的应答后,即断开连接。
还记得我们之前我们提过的三次握手建立TCP连接么?当建立TCP连接、服务端给客户端传递完消息、服务端收到客户端应答后(也有可能因为某种原因服务端主动断开连接),服务器就会关闭这个连接。下次如果再想通信,就得重新建立TCP连接。
现如今,html页面变得很复杂,里面可能嵌入了很多图片、文本、视频之类,这时候每次访问这些资源都需要建立一次TCP连接就显得低效了,而且效果会很差。
4.1 解决无连接的问题
为了解决这个无连接的问题,在HTTP请求报文首部中,设置了一个字段:Connection:。
Connection: keep-alive ,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。HTTP 1.1默认进行持久连接。利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。当然,这个连接不是一直存在,超过 Keep-Alive 规定的时间、意外断电等情况下,连接会断开。
Connection: close 代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭,当客户端再次发送Request,需要重新建立TCP连接。
5.HTTP缓存
在请求一个静态文件的时候(图片,css,js)等,这些文件的特点是文件不经常变化,将这些不经常变化的文件存储起来,对客户端来说是一个优化用户浏览体验的方法。那么这个就是客户端缓存的意义了。
PS:关于HTTP的缓存机制,内容很多,这里就不多讲了。做前端开发的同学可能需要深入了解下HTTP缓存。
5.1 为什么要使用HTTP缓存
- 减少了冗余的数据传输,节省了网费。
- 缓解了服务器的压力, 大大提高了网站的性能
- 加快了客户端加载网页的速度
5.2 浏览器里一些常见的HTTP缓存字段(都是HTTP报文首部的内容)
5.2.1 Cache-Control属性
- public:在HTTP请求返回的过程当中,返回所经过的任何路径,包括一些HTTP代理服务器以及客户端浏览器都可以对返回内容进行缓存。
- private:只有发起请求的客户端可以对内容进行缓存。
- no-cache:本地客户端可以进行缓存,但是,每次都要经过服务端的验证才可以使用缓存
- no-store:什么地方都不能进行缓存,只能每次向服务端请求资源。
- max-age=< seconds>:缓存时长,可以缓存的最长时间,过了这个时间缓存就会过期。
- s-max-age=< seconds>:专门用在代理服务器上,代替max-age。
- must-revalidate:当缓存过期后,客户端必须向源服务端发送请求,重新获取数据,验证这缓存是否已经发生变化。
5.2.2 Pragma属性
- no-cache:本地客户端可以进行缓存,但是,每次都要经过服务端的验证才可以使用缓存。(常用于HTTP/1.0)
5.2.3 Expires属性
- GMT时间:表示存在时间,允许客户端在这个时间之前不去向服务器发送检查,而直接使用缓存。等同于Cache-Control的max-age。如果在Cache-Control响应头设置了 “max-age” 或者 “s-max-age” 指令,那么 Expires 头会被忽略。
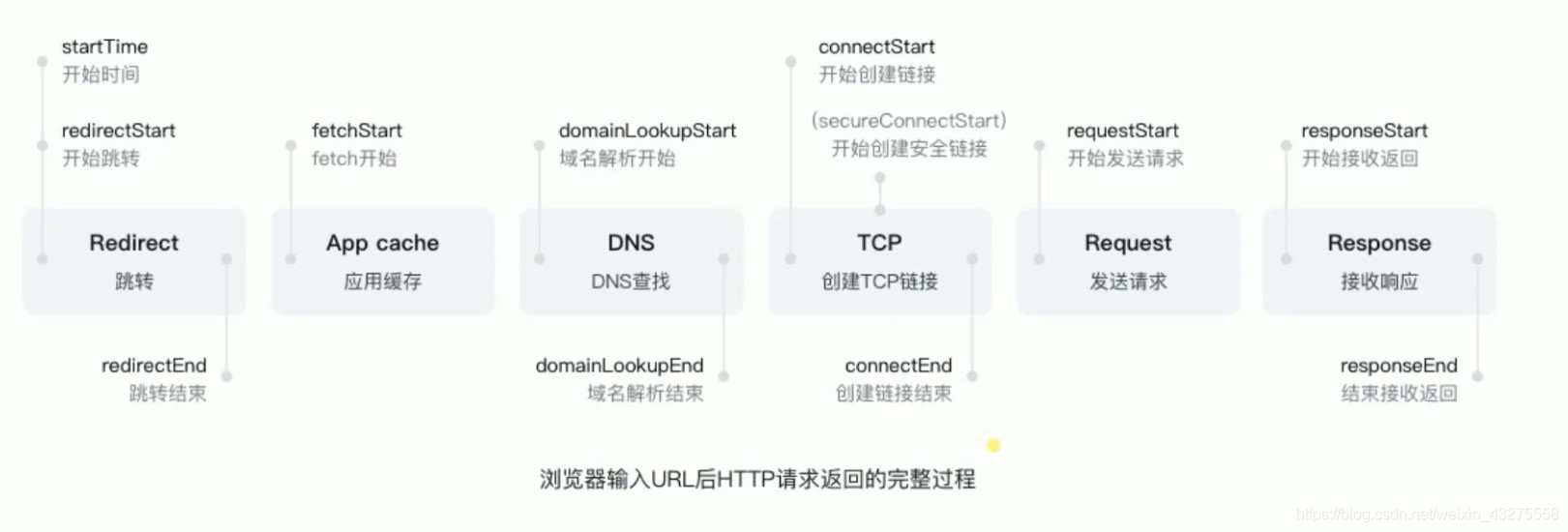
Redirect是跳转的意思,有可能你输入的URL中的域名已经永久的改变地址了。转到了另一个地址。
6.总结
文章总结了HTTP协议的一些重要特性以及URL,作为HTTP协议的第二章讲解,相对于第一章,有了更进一步的深入。
因为HTTP协议中任一部分拿出来讲,都可以讲很久,所以文章只是为了HTTP协议入门,方便大家更容易理解。如果想深入了解的话,读完文章有了框架后,再去一点一点的填充。
文章如有不当之处,还请多多指教~如有疑问,可以留言区讨论鸭!
