这是上午的那个问题---商品上架信息取供应商最后(最近)发布的价格,避免商品重复
创建表

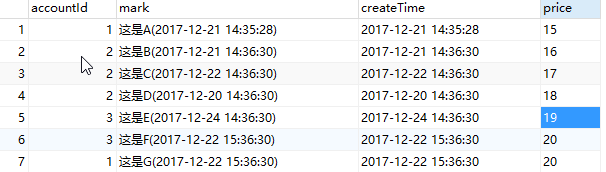
sql查询步骤(入坑过程)
group by分组后,MAX()函数可以作用于数字类型或者能够转化为数字的varchar(自己总结),当其用于datetime类型时就出很奇怪的问题了。如下
sql:
SELECT id,accountId,mark,MAX(createTime),price FROM `accountMark` GROUP BY accountId;
结果:

结果完全乱了
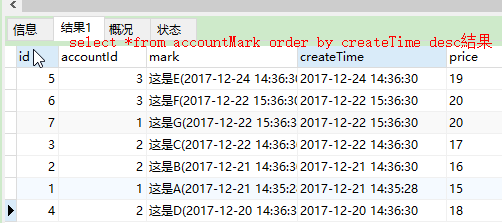
然后用下面的sql:先查询出所有数据并根据createTime排序,得到一个临时表。然后在这个临时表中查询数据,通过accountId分组,createTime排序就行了
sql:
SELECT *,COUNT(accountId) as Num FROM (SELECT * FROM accountMark ORDER BY createTime desc) `temp` GROUP BY accountId ORDER BY createTime desc
子查询结果:
但是整个sql执行又不行了
这回几乎要崩溃了...
万万没想到
下面的sql
select * from accountMark as b where not exists(select 1 from accountMark where accountId= b.accountId
and b.createTime<createTime )
运行结果:

结合上面的子查询可以发现完全正确
成功解决!
整个过程从查各种资料到慢慢实践操作花了差不多一个下午...
后来参考大神的博客发现还有其他方法
sql如下:
SELECT
id,
accountId,
mark,
createTime,
price
FROM
accountmark t
WHERE
(
createTime = (
SELECT
MAX(createTime)
FROM
accountmark
WHERE
accountId = t.accountId
)
)
运行结果完全一样,太赞了[/强]
笔记
不相关子查询:子查询的查询条件不依赖于父查询的称为不相关子查询。
相关子查询:子查询的查询条件依赖于外层父查询的某个属性值的称为相关子查询,带EXISTS 的子查询就是相关子查询
EXISTS表示存在量词:带有EXISTS的子查询不返回任何记录的数据,只返回逻辑值“True”或“False”
相关子查询执行过程:先在外层查询中取“学生表(这里是accountMark)”的第一行记录,用该记录的相关的属性值(在内层WHERE子句中给定的)处理内层查询,若外层的WHERE子句返回“TRUE”值,则这条记录放入结果表中。然后再取下一行记录;重复上述过程直到外层表的记录全部遍历一次为止。
EXISTS语句不关心子查询的具体内容,因此用“SELECT *”,“Exists + 子查询”用来判断该子查询是否返回记录。
Exists:若子查询的结果集非空时,返回“True”;若子查询的结果集为空时,返回“False” 。
NOT EXISTS :若子查询结果为空,返回“TRUE”值;若子查询的结果集非空时,返回 “FALSE。
distinct和group by得不到相关结果
group by 必须放在 order by 和 limit之前,不然会报错
mysql有 group_concat函数,4.1以后才支持(以后碰到可以使用,这次groupby已解决)
因为distinct关键字需要对结果集进行去重,如果天然无重复,是不需要加上去重关键字的,若结果集有将近百万,去重字段又多,在tmp_table_size以及sort_buffer_size中排序已经不够用,所以将结果集复制到磁盘,严重影响速度
order by m,n 不要轻易写这种语句,一般的order by前面的m才是order by的重点,后面的n为配角,如果没有必要,尽量去掉
