kafka由LinkedIn公司研发开源,现已是apache基金会的顶级项目。
一、消息队列设计
1、消息队列的两个重要设计:
消息设计:消息设计通常采用结构化的方式进行设计,结构化信息格式例如XML,JSON
传输协议设计:狭义角度:AMQP、WebService +SOAP/MSMQ等,广义角度:RPC框架如PB、Dubbo。
2、消息队列模型
点对点模型:特点:
① 生产者将消息发送到指定队列,消费者从指定队列获取消息
② 每条消息有一个发送者生产出来,且只能被一个消费者获取(消费者获取消息后删除消息)。
③ 生产者消费者是严格的一对一模型

发布/订阅模型:发布/订阅模型还可细分为两类,
① 消费者是被动的接受消息,由消息队列推送给消费者。
② 消费者主动获取消息。消息由消费者主动获取,
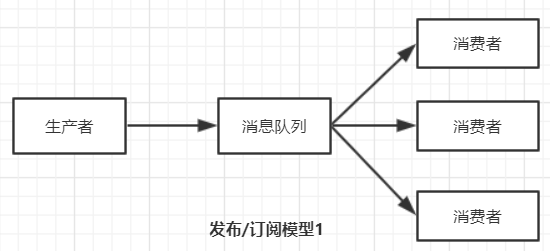
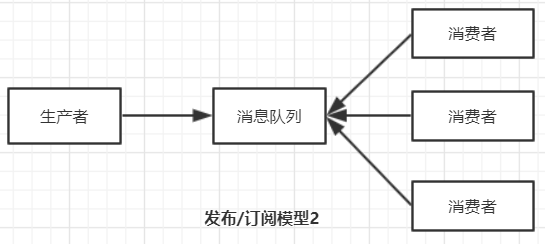
特点:
① 多了一个topic概念,生产者将消息发送个消息队列中的topic中,所有订阅了该topic的消费者都可以接受到该topic下的所有消息(主动或被动)。
② 每条消息由一个生产者生产出来,可由多个消费者消费,实现消息复用。(消费者获取消息后不删除,kafka会持久化消息到配置文件中log路径......)
③ 由于消息不删除,所以需要记录消费者消费消息的位置offset,模型一由消息队列记录,模型二由消费者记录。
④ 生产消费者是一对多模型。
⑤ 只要控制offset位置,虽然不删除消息,但可以实现点对点模型。
二、Kafka设计
Kafka是一种高吞吐量的分布式发布/订阅消息系统。设计目标:
1、吞吐量/延时
kafka的吞吐量:单位时间内处理的消息请求数
kafka的延时:单次处理消息请求的总时长,发送到接受响应
① 批处理思想
② kafka消息写入速度非常快,kafka将消息写入到内存的页缓存中,然后由操作系统异步写回磁盘。实际情况kafka大量使用页缓存,利用缓存时间局部性原理,消费者读取消息时,消息很有可能依然保存在页缓存中,直接命中缓存,无需读取磁盘节省一次I/O操作时间。
③ kafka不必直接与底层文件系统打交道,繁琐的I/O操作都交由操作系统来处理
④ kafka写入操作采用追加写入(顺序写入)的方式,避免磁盘随机写操作。ROM顺序存储速度丝毫不逊色DRAM的随机存储
⑤ 使用sendfile为代表的零拷贝技术加强网络间的数据传输效率
2、消息持久化
kafka持久化:所有数据都会立即被写入文件系统的持久化日志中,之后kafka服务器才会响应客户端成功写入
kafka持久化可很方便的实现消息重演。
3、负载均衡和故障转移
kafka实现负载均衡实际上是通过分区(partition)leader选择来实现的。
kafka故障转移使用会话机制。以会话形式注册到ZooKeeper服务器上,由ZooKeeper管理服务器状态
4、伸缩性
由于kafka每台服务器状态统一交由ZooKeeper保管,所以扩展kafka集群,仅需要将新kafka服务器注册到ZooKeeper中就行了。
二、Kafka术语
Message:kafka中的消息使用紧凑二进制字节数组,保存消,无多余比特位浪费,例如Java对象有额外开销对象头
topic和partition:主题与分区,kafka使用主题topic来分类消息,使用topic更小的分区概念partition实现负载均衡
replica:分区partition的副本,一个partition可以有多个replica,多个replica也是采用leader-follower模型建立关系。
offset:由于消息不删除,所以需要标识每条消息在分区(partition)的偏移量,
leader和follower:leader-follower模型
ISR:全称in-sync replica:指的是与leader replica保持同步的replica集合。kafka的分区partition有众多replica,follower replica在不断同步leader replica状态,只有与leader replica状态一致的replica才能加入到ISR中。kafka保证ISR至少存在一个replica,哪些已提交的消息就不会丢失。
参考《kafka实战》