本文为德国卡尔斯鲁厄理工学院(作者:Micha Wetzel)的学士论文,共57页。
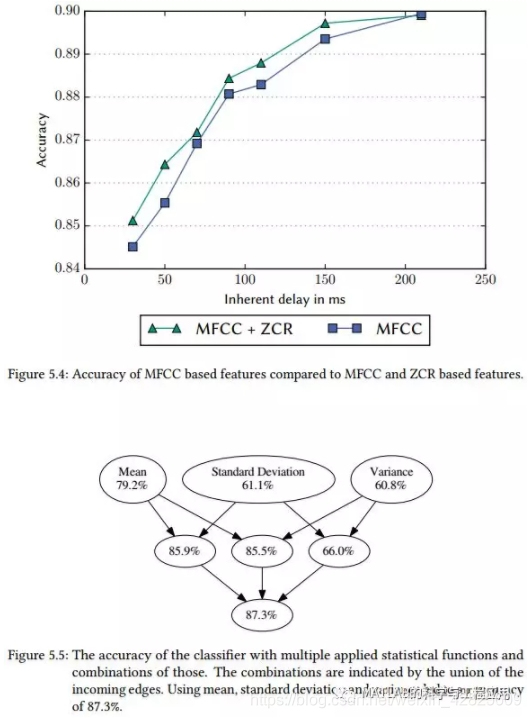
多媒体内容损害了自动语音识别(ASR)系统的识别精度和速度。本学士学位论文介绍了一种分段器,通过检测音频源中的音乐和噪声片段并用静音代替,来提高实时ASR系统的性能。提出了一种由帧分类和平滑两步组成的方法。大小为10毫秒的音频帧用分类模型分类为语音、音乐或噪声。以神经网络和支持向量机为模型,对多种设置进行了比较,分类精度达到87%。在第二步中,平滑算法考虑时间上下文以防止分类的快速波动。所提出的分段器能够产生与手动移除音乐片段相同的ASR系统的转录质量,同时保持270毫秒的实时可用延迟。
Multimedia content hurts the recognition accuracy and speed of automatic speech recognition (ASR) systems. This bachelor thesis introduces a segmenter to increase the performance of an real-rime ASR system by detecting music and noise segments in an audio source and replacing it with silence. A two step approach is proposed, consisting of frame classification and smoothing. Audio frames of size 10 milliseconds are classified as speech, music or noise with a classification model. Multiple settings with neural nets and support vector machines as model are compared, resulting in an classification accuracy of 87%. In the second step the smoothing algorithm considers the temporal context to prevent rapid class fluctuations. The proposed segmenter yields a transcript quality of an ASR system en-par with manual removal of the music segments, while maintaining a real-time applicable delay of 270 milliseconds.
- 引言
- 项目背景
- 以有的工作
- 研究方法
- 实验
- 结论
更多精彩文章请关注公众号:
