MySQL:
mysql参数:
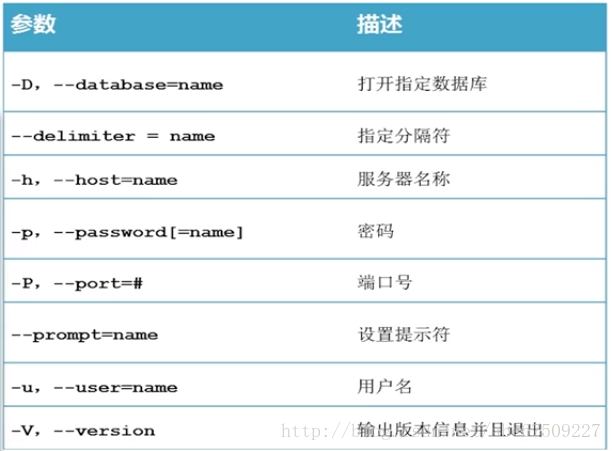
mysql登陆:-u root -p
mysql退出:exit; 、 quit; 、 \q; 都可以。
修改mysql提示符:
1、在登陆时通过参数指定:-uroot -p密码 –prompt 提示符
2、连接上客户端口用 prompt 指定:prompt 提示符
提示符(快捷设置):
\D 完整的日期
\d 当前数据库
\h 服务器名称
\u 当前用户
常用命令:
SELECT VERSION();
显示当前服务器版本
SELECT NOW();
显示当前日期时间
SELECT USER();
显示当前用户
关键字与函数名称全部大写。
数据库名称、表名称、字段名称全部小写。
SQL语句必须以分号结尾。
创建数据库:

中括号里为可选项。
IF NOT EXISTS 如果重名则不提示错误。
查看当前服务器下的数据库列表:

修改数据库:

删除数据库:

数据类型:
数据类型是指列、存储过程参数、表达式和局部变量的数据特征,它决定了数据的存储格式,代表了不同的信息类型。
整型:
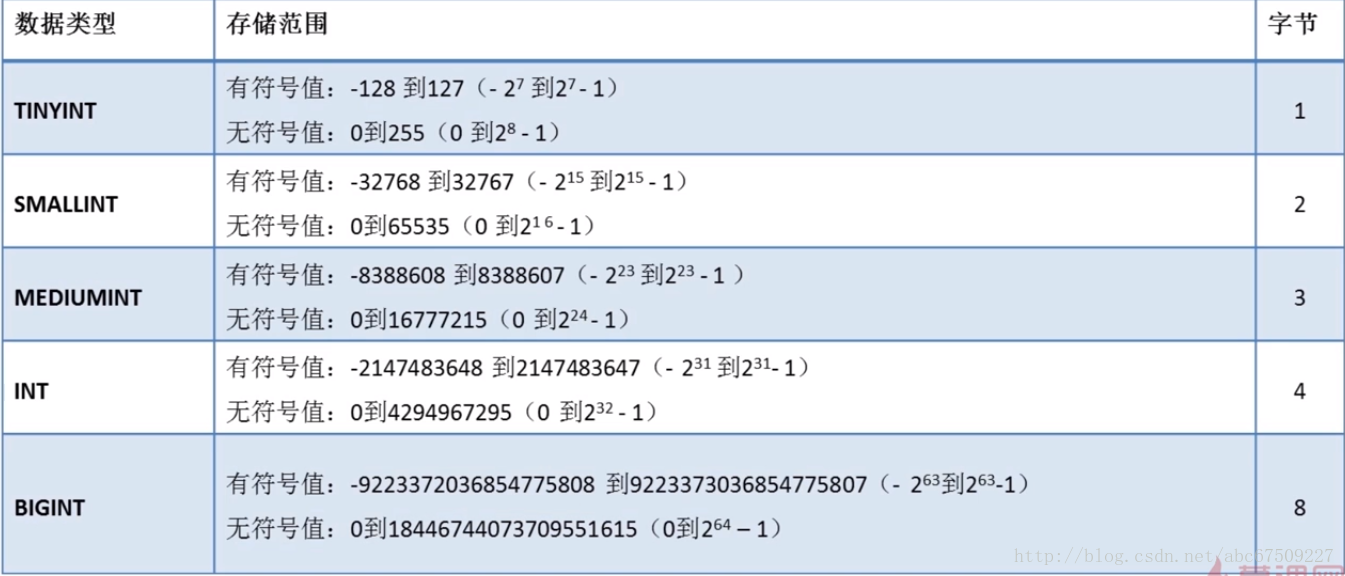
选择最合适的数据类型。
浮点型:

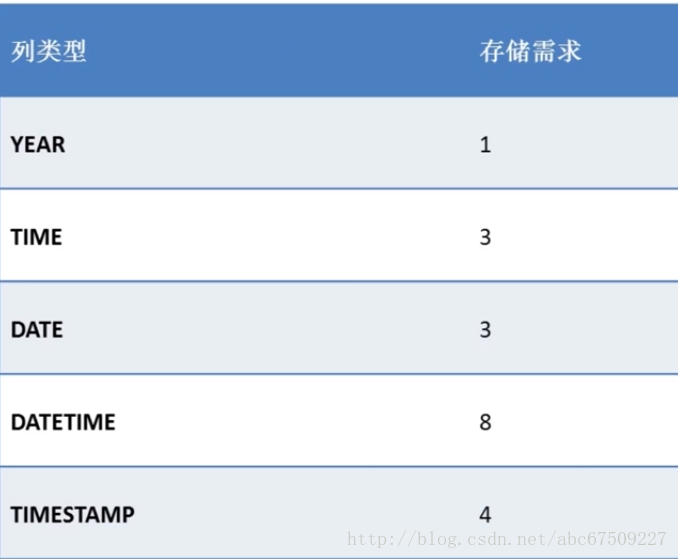
日期时间型:
字符型:
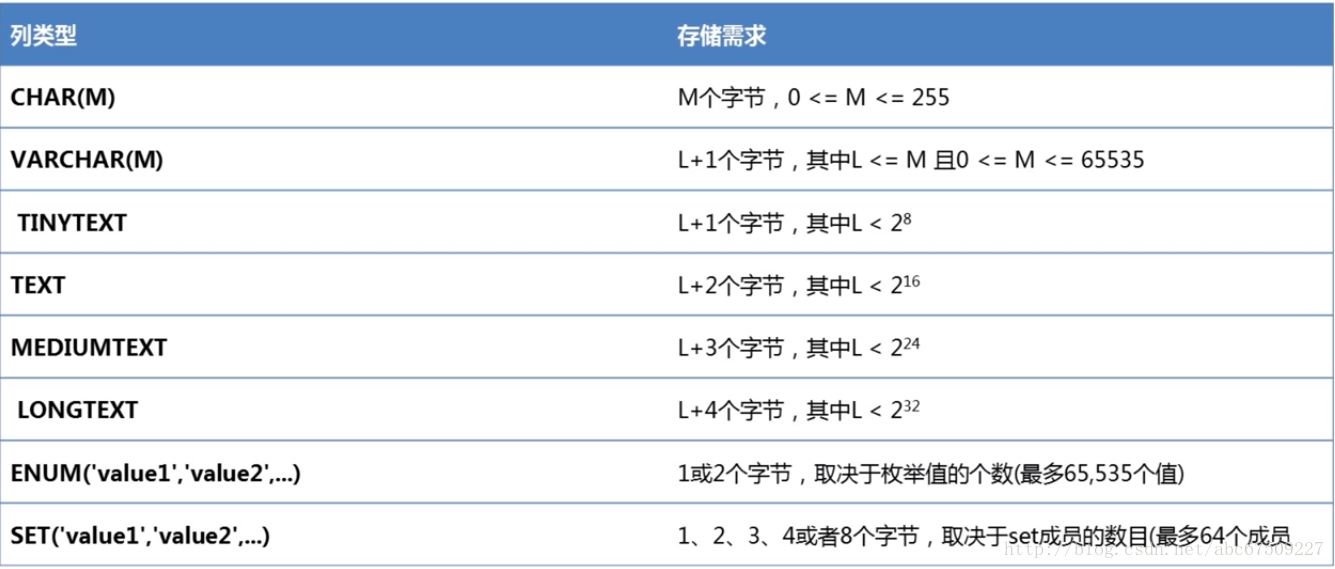
CHAR:定长的类型。没有达到指定长度则用空格补齐。
VARCHAR:变长的类型。多余的数据不会存储。
SET:集合。可以从集合中做任意的排列组合。
创建数据表:
数据表(或称表)是数据库最重要的组成部分之一,是其他对象的基础。
如果要存储数据,必然要设计数据表。
首先打开数据库: USE 数据库名称;
创建数据表:

小括号里面:数据名称和数据类型。
例如:

第三行:后面 UNSIGNED 表示无符号。
第四行: 8,2 表示一共有8位,其中小数部分有2位。
倒数第二行不需要加 逗号 。
查看数据表:

查看数据表列表:
SHOW COLUMNS FROM tbl_name;
tbl_name 为数据表名称。
INSERT:
插入记录。

如果省略 列名称,则要为所有列赋值。
记录查找:

空值与非空:
NULL,字段值可以为空。
NOT NULL,字段值禁止为空。
如:
CREATE TABLE tb2 (
username VATCHAR(20) NOT NULL
);
表明 username 必须被赋值。
AUTO_INCREMENT:
自动编号,且必须与主键组合使用。
默认情况下,起始值为1,每次增量为1。
主键约束:
PRIMARY KEY
每张数据表只能存在一个主键
主键保证记录的唯一性(不允许存在两个相同的值)
主键自动为 NOT NULL
(创建数据表的时候在后面加入 PRIMARY KEY)
如果加入 AUTO_INCREMENT ,则该字段自动赋值,不用手动。
(AUTO必须与主键使用,而主键可以不用AUTO)
唯一约束:
UNIQUE KEY
唯一约束可以保证唯一性
可以是 NULL
可以存在多个唯一约束
默认约束:
DEFAULT
默认值
当插入记录时,如果没有明确为字段赋值,则自动赋予其值
约束:
为了保证数据的完整性和一致性。
约束分为表级约束和列级约束。
约束类型包括:
NOT NULL(非空约束)
PRIMARY KEY (主键约束)
UNIQUE KEY (唯一约束)
DEFAULT (默认约束)
FOREIGN KEY(外键约束)
FOREIGN KEY:
保持数据一致性,完整性。
实现一对一或一对多关系。
要求:
父表和子表必须使用相同的存储引擎,而且禁止使用临时表。
数据表的存储引擎只能为 InnoDB
外键列和参照列必须具有相似的数据类型。其中数字的长度或是否有符号位必须相同;而字符的长度可以不同。
外键列和参照列必须创建索引。如果外键列不存在索引的话,MySQL将自动创建索引。
(具有外键列的表称为子表,子表所参照的表称为父表)
(加过 FOREIGN 的列称为外键列,外键列所参照的列称为参照列)
例如:
参照列:
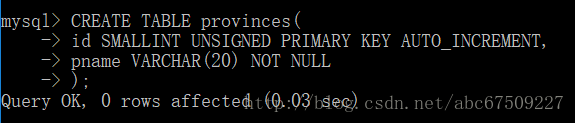
外键列:
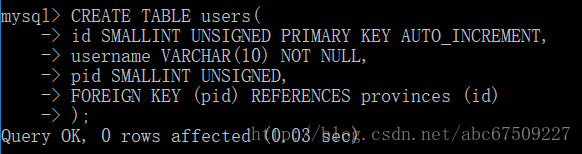
外键约束参照操作:


ON DELETE 表示可以删除。
DELETE FROM tdl_name WHERE id =3; (删除 id 3)
如果加了 CASCADE ,则父表删了子表跟着就删了。
(一般不用 FOREIGN KEY 定义外键)
表级约束和列级约束:
对一个数据列建立的约束,称为列级约束。
对多个数据列建立的约束,称为表级约束。
列级约束既可以在列定义时声明,也可以在列定义后声明。
表级约束只能在列定义后声明。
修改数据表:
添加单列:

AFTER 指定在某列的后方,如果不指定,则在所有列的最下面。
FIRST 指定在所有列的最前方。
添加多列:

删除列:

可以用逗号分隔,删除多列,或在删除的同时新增一列,如 DROP 1,DROP 2;
添加约束:
主键约束:

唯一约束:

第一个中括号可以为约束起名字。
默认约束:

添加:ALTER TABLE users2 ALTER age SET DEFAULT 15;
删除:ALTER TABLE users2 ALTER age DROP DEFAULT;
删除约束:
删除主键约束:

因为只有一个主键约束,所以不需要指定名称。
删除唯一约束:

默认 index 名字等于原本名字,如果手动更换,则需查找。
删除外键约束:

删除之前先查找约束名字,再删除。
(SHOW CREATE TABLE 表名;)
外键约束删除会留下索引,删除索引用 INDEX
修改列定义:

(添加是 ADD,修改是 MODIFY ,其余不变)
(也可以改变属性,但是大类型改成小类型可能会数据丢失)
可以用 CHANGE 修改列的名称:CHANGE pid p_id …; 将pid修改为p_id;
修改数据表名字:

(尽量少修改表名和列名)
插入记录:

为自动编号的列赋值,可以采用 NULL 或 DEFAULT,其呈现依次递增的形态。
VALUES 可以写成数学表达式的形式。
如果有 DEFAULT 的话,可以直接写 DEFAULT,赋予默认值。
可以用 逗号 分隔插入多条语句。
方法二:

与第一种方式的区别在于:此方法可以使用子查询(SubQuery)
而且不能同时插入多条记录。
方法三:

此方法可以将查询结果插入到指定数据表
单表记录更新:

如:UPDATE users SET age = age + 5;
(让所有表中记录的年龄都在原来的年龄基础上加 5)
可以更新多个字段,中间加逗号。
可以加 WHERE 控制条件。
如: UPDATE users SET age = age + 10 WHERE id % 2 = 0;
让 id 为偶数的记录 age 增 10
单表记录删除操作:

查询表达式解析:

每一个表达式表示想要的一列,必须有至少一个。
多个列之间以逗号分隔。
星号 * 表示所有列。
tbl_name.* 可以表示命名表的所有列。
查询表达式可以使用 [AS] alias_name 为其赋予别名。
别名可用于 GROUP BY , ORDRE BY 或 HAVING 子句。
(字段可以用 AS 赋予别名,将影响到结果集的名字)
(输入顺序会影响到结果集出现的顺序)
WHERE条件表达式:
对记录进行过滤,如果没有指定WHERE子句,则显示所有记录。
在WHERE表达式中,可以使用MySQL支持的函数或运算符。
查询结果分组:

ASC 升序(默认) DESC 降序。
如:
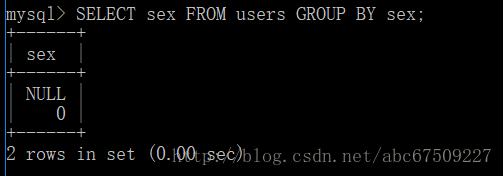
(可以跟数字,按数字所示的第几个所代表的 sex 进行分组,但一般不用)
分组条件:

条件必须在 SELECT 后面所跟字段中有出现。
比如:SELECT sex FROM users GROUP BY sex HAVING age > 35; (不行)
SELECT sex,age FROM users GROUP BY sex HAVING age > 35; (可以)
(将条件内的记录分组)
分组排序:

如:
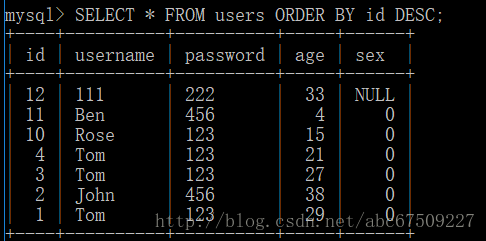
可以指定多条,比如 ORDER BY age,id DESC;
(age 升序且 id 降序排列)
限制查询返回数量:

如:

从第一条开始依次返回。
id号与结果集中的顺序没有任何联系
可以指定从第几条开始: LIMIT 3,2; 表明从第 4 条开始,显示第4、5条
(因为记录顺序是从 0 开始的,所以指定的为 第i+1条)
将一个表的记录写入到另一个表内:
用 INSERT * SELECT语句
INSERT test(username) SELECT username FROM users WHERE age >= 30;
(将 users 表中 age 大于等于30的记录的 username 写入到 test 中)
子查询:
子查询(SubQuery)是指出现在其他SQL语句内的SELECT语句。
例如:

子查询指嵌套在查询内部,且必须始终出现在圆括号内。
子查询可以包含多个关键词或条件,
如 DISTINCT、GROUP BY、ORDER BY、LIMIT,函数等。
子查询的外层查询可以是:SELECT、INSERT、UPDATE、SET或DO
子查询可以返回标量、一行、一列或子查询。
使用比较运算符的子查询:
=、>、<、>=、<=、<>、!=、<=>
语法结构:
operand comparison_operator subquery
如:
SELECT goods_id,goods_name,goods_price FROM tdb_goods WHERE goods_price >= (SELECT ROUND(AVG(goods_price),2) FROM tdb_goods);
将括号里查询结果的返回作为条件,使之进行筛选。
(ROUND函数:保留小数点后n位, AVG:求平均值)
必须限制子查询只能返回一个结果:


用 ANY、SOME、ALL 来控制子查询返回单个值。
(任意值的意思是只要其中一个符合就可以)
[NOT] IN 的子查询:

使用[NOT] EXISTS的子查询:
如果子查询返回任何行,EXISTS将返回TRUE,否则为FALSE。
(在 CREATE 时加上 IF NOT EXISTS ,则判断是否存在,不存在才创建)
多表更新:

表的参照关系:

连接类型:

如:

将 tdb_goods 和 tdb_goods_cates 连接起来,条件(ON)为:
两张表 goods_cate = cate_name 的值 (名称一样也要写(前加表名))
设置(SET)将这些值的 good_cate = cate_id
当名称一样时,还可以给表起别名(AS):
如一个 AS g,一个 AS b,则条件(ON): g.name = b.name
CREATE…SELECT:

如:

(事实的外键,另一种将两张表联系起来的方法)
(将数字保存在表中,含义保存在另一张表中,两表数字id一样)
连接:
因为事实外键的存储,而显示的时候要一起去显示,所以要连接。
在SELECT语句、多表更新、多表删除语句中支持JOIN操作。
数据表参照:

连接条件:
使用ON关键字来设置连接条件,也可以使用WHERE来代替。
通常使用ON关键字设定连接条件。
使用WHERE关键字进行结果集记录的过滤。
内连接:
显示左表及右表符合连接条件的记录(交集的部分)。
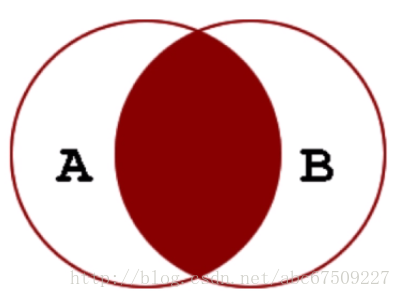
外连接:
左外连接:显示左表中的全部记录及右表中符合条件的记录。
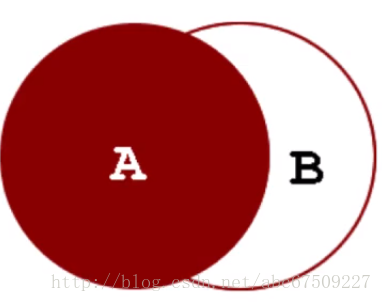
(此时左表有但右表没有的,右边显示NULL)
右外连接类似。
多表连接:
在后面加就行(不用逗号,直接空格再加一个 INNER JOIN 或外连接)
外连接说明:


无限极分类表设计:
设计语句:
CREATE TABLE tdb_goods_types(
type_id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
type_name VARCHAR(20) NOT NULL,
parent_id SMALLINT UNSIGNED NOT NULL DEFAULT 0
);
查找:自身连接
同一个数据表对其自身进行连接。
(一定要起别名)
如:
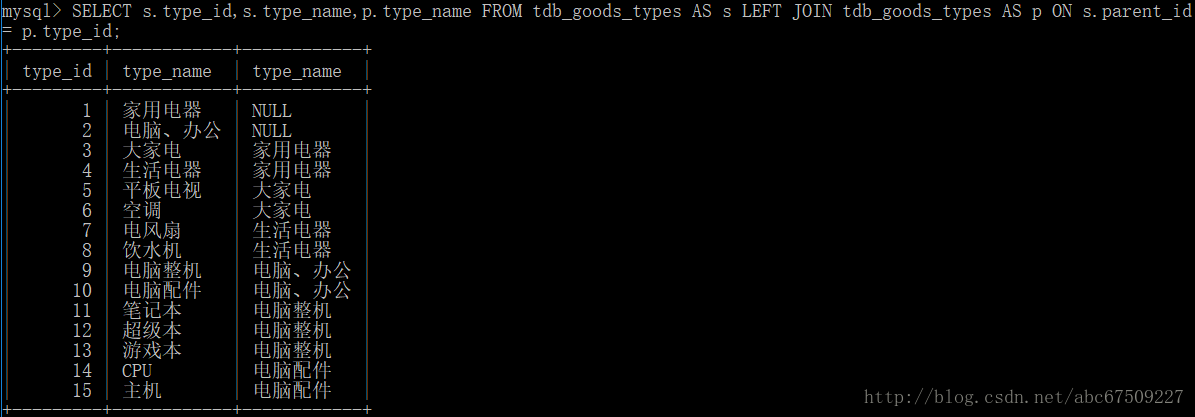
(左表显示所有子类,右表显示它们分别属于哪个类)
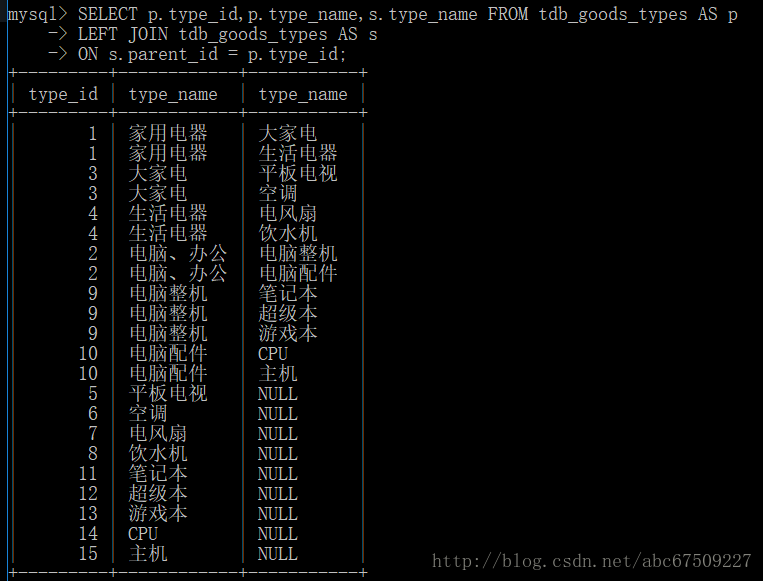
(左表显示左右父类,右表显示它们下面有哪些类)

加上分组和排序,然后用 count 函数去使其显示数字,就可显示子类数目。
多表删除:

比如:先将记录分组,然后用 HAVING 控制显示 count(NAME) >= 2 的记录。
将上述记录作为子查询的表格。
DELETE t1 FROM 第一个表 LEFT JOIN (子查询) ON 两表的NAME相等 WHERE 第一个表的NAME.ID > 第二个表的NAME.ID;
函数:
字符函数:

如:

CONCAT_WS : 第一个代表 分隔符,后面是语句。
如:SELECT CONCAT_WS(‘-‘,’A’,’B’); 显示:A-B
FORMAT:格式化
如:FORMAT(123456.12222,2); 表示保留两位小数,四舍五入。
LOWER:里面的字符串转换成小写。
UPPER转换为大写。
LEFT:从左取前n位
如:LEFT(‘MySQL’,2); 从左取两位,得到 My
可以嵌套
如:LOWER(LEFT(‘MySQL’,2)); 将左边两位返回再将这个字符串变为小写。
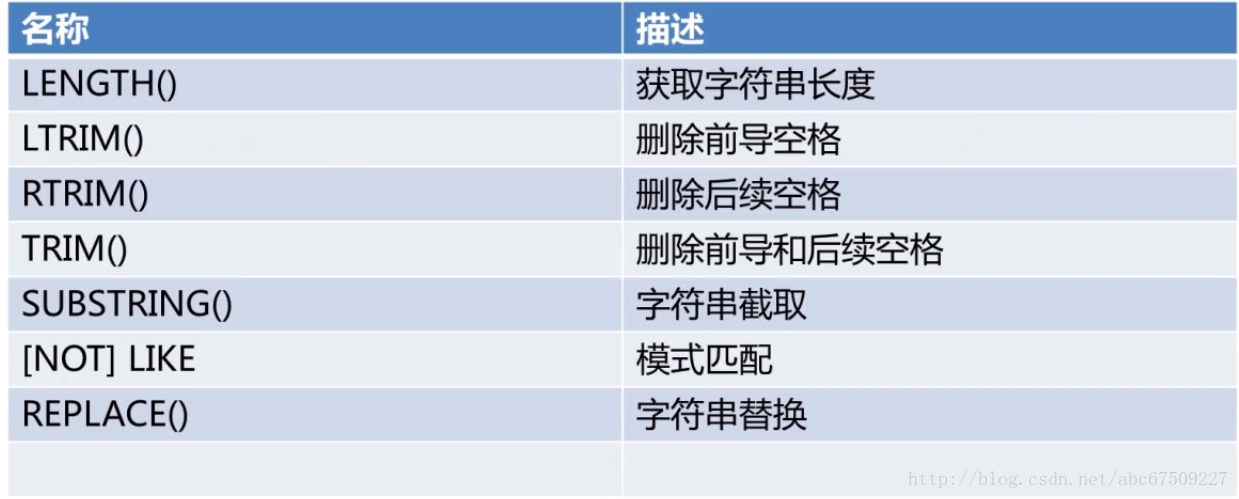
LENGTH:如果中间有空格,空格也包含在长度之内。
LIRIM:去除字符串前面的所有空格。
TRIM:也可删除特定字符
如:TRIM(LEADING ‘?’ FROM ‘??MYSQL’);
将前面的 ?? 删除。
删除后续的:TRAILING
前面和后面都删掉:BOTH
REPLACE:替换
如:REPLACE(‘???MY???SQL???’,’?’,”); 显示:MYSQL
将第一个字符串中所含有的第二个字符串都替换成第三个字符串(可以为空)。
SUBSTRING:截取
三个参数,第一个是字符串,第二个从第几位截,第三个为截几个。
没写截几个的话,就一直到结尾。
也可以从负值开始截取(正值从左起,负值从右起)
LIKE:模式匹配
如:’MYSQL’ LIKE ‘M%’; 得到的是 1(在这里认为是 true)
百分号:零个或多个任意字符。
表中如:
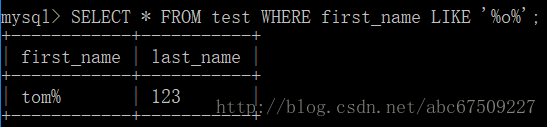
控制条件,只找其中含有 o 的记录。(百分号代表任意字符串)

将 1 以后的百分号被看做是普通的百分号。(用ESCAPE控制)
百分号:任意个字符(包含0个)
下划线:任意 一个 字符(不包含0个,至少1个)
数值运算符与函数:

CEIL:向上取整,CEIL(3.01) = 4
FLOOR相反。
DIV:整数取余。 3/4 = 0.75, 3 DIV 4 = 0
MOD: 取余,可以是小数 5.2 MOD 3 = 2.2
ROUND: 可以有两个参数(保留小数位数)
如: ROUND(3.652,2) = 3.65
TRUNCATE: 不做四舍五入,直接截取
(可以是负数,如:TRUNCATE(125,-1) = 120)
比较运算符和函数:

BETWEEN…AND…: 20 BETWEEN 15 AND 22 —— 结果得到 1(true)
也可以在前面加 NOT (不在)
IN:在不在点集之间,如:10 IN(5,15,20) —– 结果得到 0(fault)
IS NULL: 是否为空,如: NULL IS NULL —– 1
SELECT * FROM test WHERE name IS NULL; 将 name 为空的记录显示
日期时间函数:

DATE_ADD:可以在时间上加时间。
如:SELECT DATE_ADD(‘2014-3-12’, INTERVAL 1 YEAR) 在所输入时间上加一年
(可以加 WEEK , 也可以直接 365(加天))
DATEDIFF:计算日期差值。
SELECT DATEDIFF(‘2013-2-14’,’2014-2-14’);
得到 -365
DATE_FORMAT:格式化
SELECT DATE_FORMAT(‘2014-3-12’,’%m/%d/%Y’)
(带着前导0的月份 %m,带着前导0的日子 %d,年份 %Y)
信息函数:

LAST_INSERT_ID:在一个记录表中要保证有自动编号的主键。
返回最后写入语句的ID号
(如果最后一次写入同时写入了多条ID,则只返回第一条的ID号)
聚合函数:
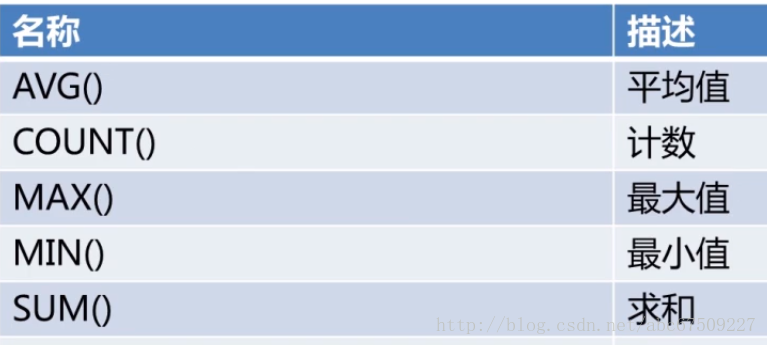
COUNT: 可以计算一共有多少个记录。(或者别的各种记录)
加密函数:

尽量使用MD5。
PASSWORD 在MYSQL主要为改掉用户和其他用户的密码。
如:SET PASSWORD = PASSWORD(‘xxxxx’); 改掉登陆MYSQL的密码。
自定义函数:
对MYSQL扩展的途径,其用法与内置函数相同。
创建自定义函数:

函数体由合法的SQL语句构成。
函数体可以是简单的SELECT或INSERT语句。
函数体如果为复合结构则使用BEGIN…END语句。
复合结构可以包含声明,循环,控制结构。
如:

带参数:

可以用 DELIMITER // 来用 // 代替 ; 作为结束符
(对于某些时候你要键入 ;而不是要语句结束的时候)
复合结构函数声明:

创建函数的语句中想要穿插 插入记录 的语句
(相当于函数内容:插入一条记录,并返回最后插入记录的ID号)
函数内容用 BEGIN…END 实现,内容每条语句以分号 ; 结束
(要提前用 DELIMITER 来改变结束符)
删除函数:
DROP FUNCTION [IF EXISTS] function_name;
存储过程:

存储过程是SQL语句和控制语句的预编译集合,以一个名称存储并作为一个单元处理。
(预编译:第一次进行语法分析和编译,并存储在内存当中,第二次调用的时候直接执行,不用再分析和编译)
优点:
增强了SQL语句的功能和灵活性。
实现了较快的执行速度。
减少了网络流量。
创建存储过程:

user:当前登录到客户端的用户。
IN,表示该参数的值必须在调用存储过程时指定。
(在存储过程当众这个值是不能被返回的,只能进,不能出)
OUT,表示该参数的值可以被存储过程改变,并且可以返回。
INOUT,表示该参数的调用时指定,并且可以被改变和返回。
特性:与自定义函数完全相同


过程体:
过程体由合法的SQL语句构成;
过程体可以是任意SQL语句;
(对于记录的增删改查以及多表的连接)(数据表等的创建是不行的)
过程体如果为复合结构则使用BEGIN…END语句;(包含两个以上语句)
复合结构可以包含声明,循环,控制结构;
(IF,WHEN,WHILE等等)
如:

将 SELECT VERSION(); 作为存储过程存储。
(第一次调用要处理编译,第二次则直接执行,速度快且流量少)
调用存储过程:

没有参数的话可以不带小括号。
(CREATE必须带,CALL可以不带)
修改存储过程:

(只能做简单修改)
删除:
DROP PROCEDURE [IF EXISTS] sp_name;
IN类型创建:
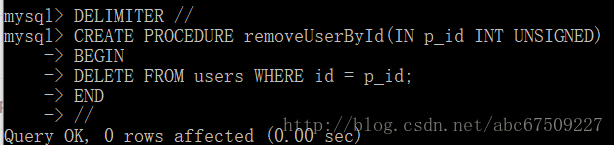
BEGIN…END 语句中声明的变量为局部变量,只在BEGIN…END语句块之间起作用。
可以 SET @i = 7; 这是用户变量。
只对当前用户所使用的客户端生效。
(一般带有 @ 符号)
IN-OUT类型创建:


INTO:将查找值赋予 INTO 后的变量。
IN-调用时必须被指定,如27
而OUT-调用时可以传个变量进去,作为承载,中途可以被改变与返回。
ROW_COUNT():得到插入、删除以及更新的被影响到记录总数。
(上一条命令必须是插入、删除或更新,总数也是上一次操作的总数)
(如果你INSERT,然后SELECT,再ROW就不行了)
(可以作为存储过程去调用查看)
(调用的时候如果过程体中的一条语句错了,只会那一条及之后的不执行,之前的还是会执行的)
多返回值创建:

存储过程与自定义函数的区别:
存储过程实现的功能要复杂一些,而函数的针对性更强。
存储过程可以返回多个值,函数只能有一个返回值。
存储过程一般独立的来执行,而函数可以作为其他SQL语句的组成部分来实现。
存储引擎:
可以查看数据表的创建命令:SHOW CREATE TABLE tb_name;
(查看当前数据表是什么样子,当前的样子而不是最初)
里面有一条语句:ENGINE=InnoDB,这就是存储引擎。
MySQL可以将数据以不同的技术存储在文件(内存)中,这种技术就称为存储引擎。
每一种的存储引擎使用了不同的存储机制、索引技巧、锁定水平,最终提供广泛且不同的功能。
MySQL支持的存储引擎:
MyISAM
InnoDB
Memory
CSV
Archive
并发控制:
当多个连接对记录进行修改时保证数据的一致性和完整性。
(如果有两个用户,一个正在删除id=1的记录,而另一个同时在获取id=1的记录)
(可能会出现错误,而解决这类问题的方法就是使用并发控制)
锁:
共享锁(读锁):在同一时间段内,多个用户可以读取同一个资源,读取过程中数据不会发生任何变化。
排他锁(写锁):在任何时候只能有一个用户写入资源,当进行写锁时会阻塞其他的读锁或者写锁操作。
(加锁只是加最对的,比如用户修改个人信息,那么只对用户表甚至用户表中的某条记录加锁)
锁颗粒:
表锁,是一种开销最小的锁策略。
行锁,是一种开销最大的锁策略。(有多少行就可能有多少条锁)
(开销是系统的开销)
事务处理:
事物用于保证数据库的完整性。
(做一个操作,如果出了问题,应该恢复到数据库的原始状态)
事物的特性:
原子性、一致性、隔离性、持久性
外键:
是保证数据一致性的策略。
索引:
是对数据表中的一列或多列的值进行排序的一种结构。
各种存储引擎的特点:
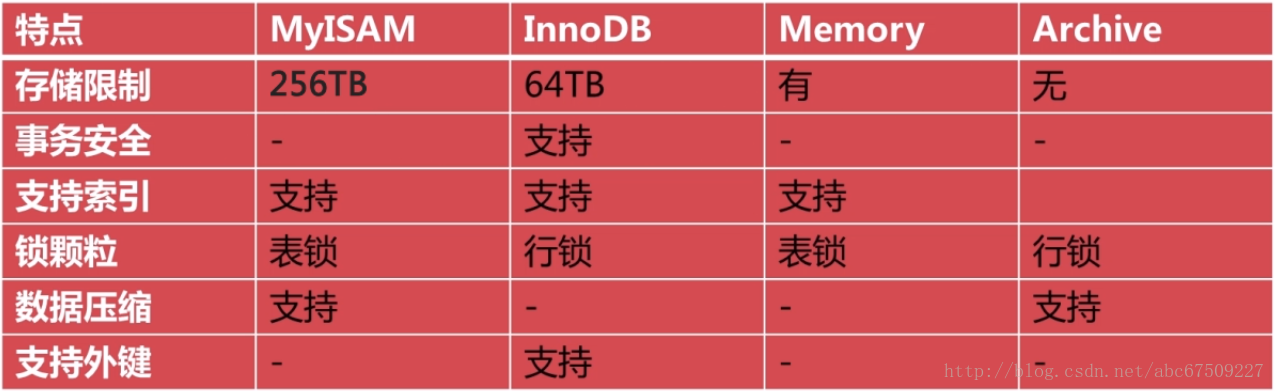
一般采用 MyISAM 和 InnoDB 引擎。
MyISAM:适用于事物的处理不多的情况。
InnoDB:适用于事物处理比较多,需要有外键支持的情况。
修改存储引擎的方法:
1.

2.通过创建数据表命令实现:
CREATE TABLE table_name(
…
…
) ENGINE = engine;
或者也可以通过修改数据表的命令来实现:
ALTER TABLE table_name ENGINE [=] engine_name;