目录
- 01_WSGI_mini_web框架
- 00_服务器与http服务器与web框架的优化图示过程
- 01_多进程_web服务器
- 02_web服务器里边集成了解析动态请求的功能
- 03_将web服务器和逻辑处理的代码分开-简易版本,不完全
- 04_将web服务器和逻辑处理的代码分开-升级版
- 05_让web服务器支持wsgi协议
- 06_通过传递字典实现浏览器请求的资源的不同,而做出不同的响应
- 07_实现模版文件-替换数据
- 08运行web服务器时指定端口以及框架
- 09_让web服务器支持配置文件
- 02_闭包-装饰器
- 03_修饰器/装饰器
- 01_装饰器的演示
- 02_闭包修改数据
- 03_装饰器的实现过程
- 04_装饰器的作用-装饰器计算原函数test()的运行时间
- 05_对没有参数没有返回值的函数进行装饰
- 06_对有参数无返回值的函数进行装饰
- 07_同一个装饰器对多个函数进行装饰
- 08_装饰器在没有开始调用函数之前就开始装饰了
- 09_使用装饰器对不定长参数函数进行装饰
- 010_对有返回值的函数进行装饰
- 011_多个装饰器对同一个函数进行装饰
- 012_使用多个装饰器对同一个函数进行装饰-demo
- 013_使用类当做装饰器
- 04_mini_web框架添加路由和MYSQL功能
- 05_mini_web框架添加正则及log日志功能
01_WSGI_mini_web框架
00_服务器与http服务器与web框架的优化图示过程
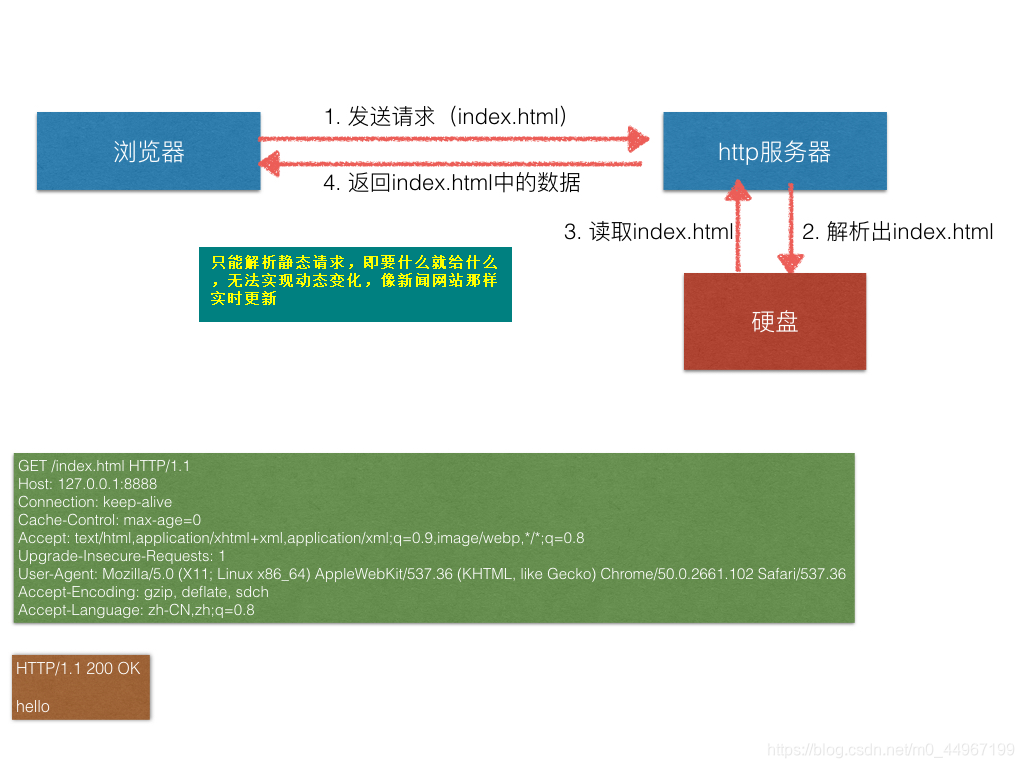
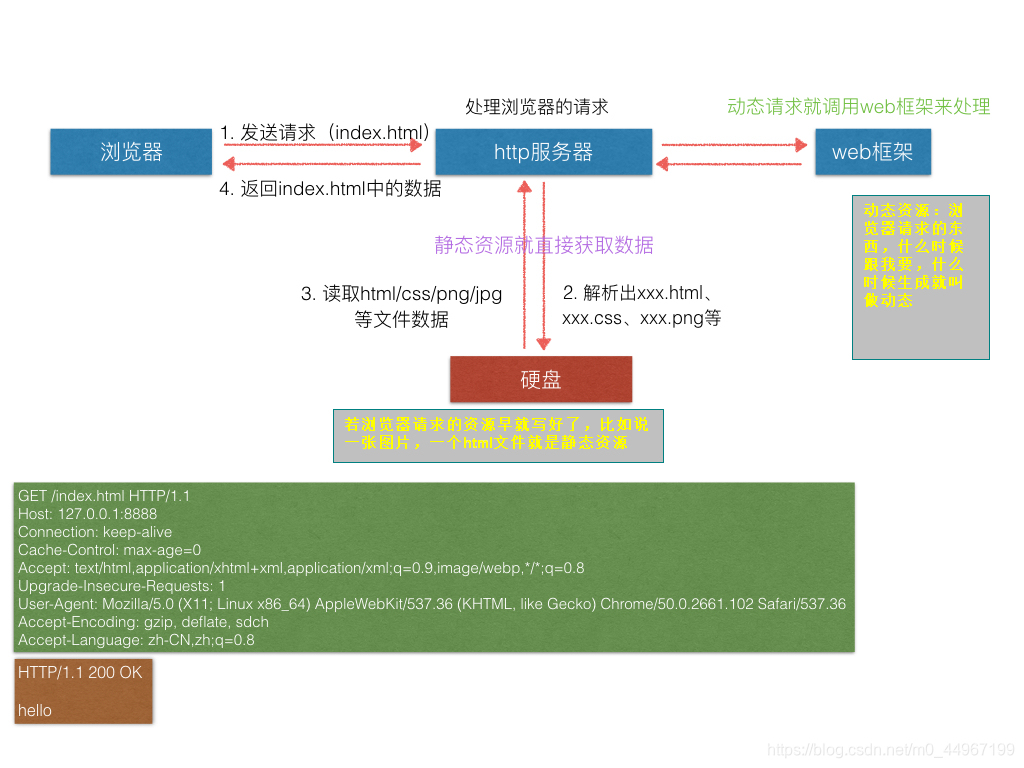
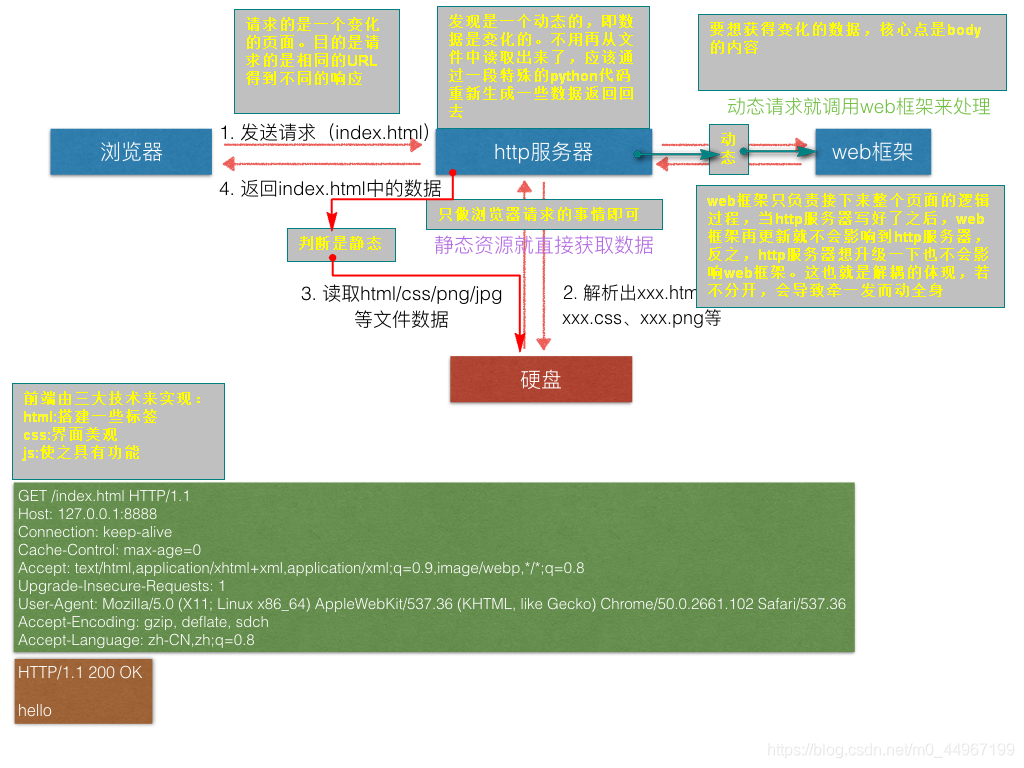
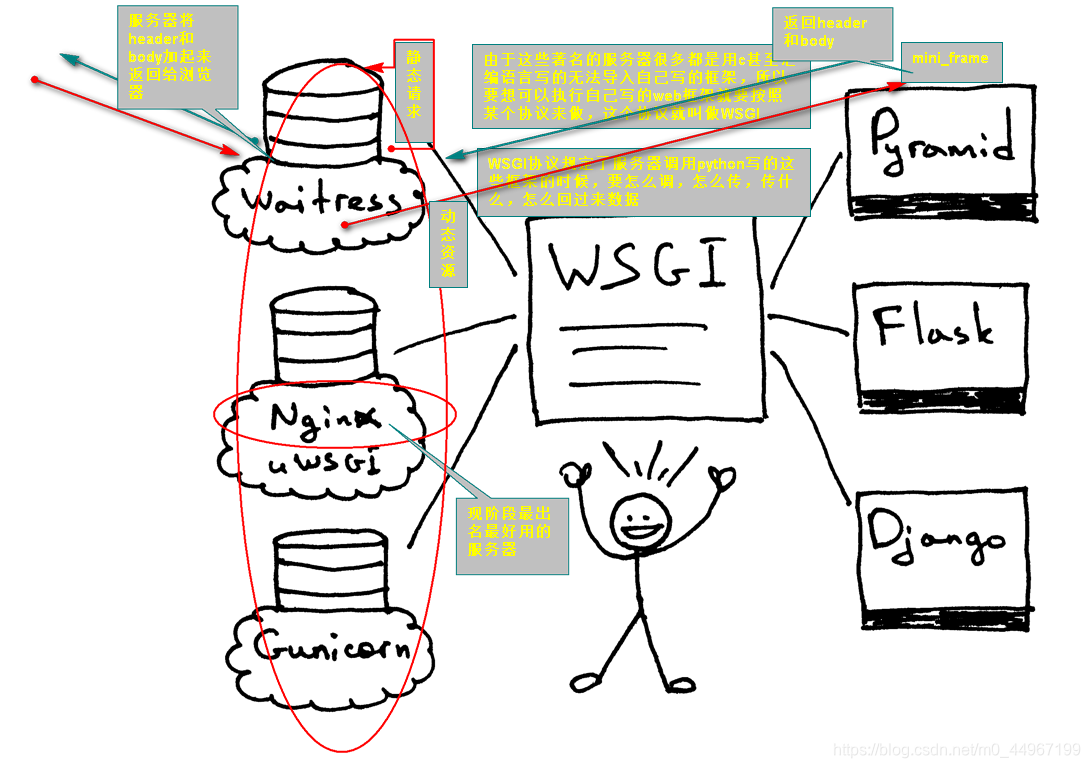
01_多进程_web服务器
import socket
import re
import multiprocessing
"""使用多进程实现多任务"""
class WSGISever(object):
def __init__(self):
"""这一部分为创建套接字,不用进行循环执行,并且是希望在创建对象的同时进行创建套接字"""
"""这个方法不用调用,创建对象的同时直接执行的"""
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",7890))
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
def send_data_to_client(self,new_client_socket):
"""类中定义实例方法,要加上self"""
"""为这个客户端返回数据"""
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print("*"*50)
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
try:
f = open("./html"+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
# 3.关闭套接字
new_client_socket.close()
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 卡在这里,等待一个用户的链接,为该用户服务,服务结束后,再为下一个用户服务,只能一个一个的执行
# 为了提高运行效率,可以这样做:每接收到一个请求干脆开一个进程,让这个进程里边的线程去为它服务
#(进程是资源分配的单位,真正在做事情的是子进程里边的主线程)
# 只要创建一个进程,让里边自带一个线程即可
# accept()依旧是一个,让它来接收,将来分配任务的时候让其他人去做
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
"""
用Process创建一个子进程的时候,子进程会复制主进程的资源,能共用就共用,不能共用就复制一份,比如代码就可以共用,叫做写实拷贝
调用Process时,所有的变量(局部,全局)都会复制一份,两者标记了同一个客户端(指向底层的同一个fd(file descriptor)文件故当子
进程调用close()时并不会关闭底层的fd文件,因为主进程中还有指向它的对象,所以要在主进程中再调用一次close(),此时四次挥手才开始
启动
在linux里边,一切设备皆文件(.py文件,压缩包,键盘,鼠标,显示屏,打印机,耳机...),把一切都抽象成文件
同理,标记客户端的套接字说到底,也是一个文件
"""
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
wsgi_sever = WSGISever()
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
02_web服务器里边集成了解析动态请求的功能
import socket
import re
import multiprocessing
import time
"""使用多进程实现多任务"""
class WSGISever(object):
def __init__(self):
"""这一部分为创建套接字,不用进行循环执行,并且是希望在创建对象的同时进行创建套接字"""
"""这个方法不用调用,创建对象的同时直接执行的"""
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",7890))
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
def send_data_to_client(self,new_client_socket):
"""类中定义实例方法,要加上self"""
"""为这个客户端返回数据"""
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print("*"*50)
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.py结尾,那么就认为请求的是静态资源(html/css/js/png/jpg等)
if not file_name.endswith(".py"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open("./html"+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
header = "HTTP/1.1 200 OK\r\n"
header = "\r\n"
body = "hahahaha %s" % time.ctime() # 浏览器里边看到的结果就是这个ctime()打印出来的东西
# 要想获得丰富的变化的数据,核心点是body的内容
# 当前整个程序就是tcp的一个web服务器,他能解析出http的请求,回应http的应答,相当于一个http的服务器
# 说的直白一点,刚刚让它能够解析出动态的资源的请求来而且给它返回了动态的数据是在http服务器里边写的
# 言外之意就是将http服务器的功能与对动态数据的请求以及对请求的处理的实现混在了一起.这就等于在一个
# 大的程序里边实现了两个功能,这是不合理的.
# 应该重新写一个py程序,然后让http服务器去调用它(这是一种解耦的体现)
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 卡在这里,等待一个用户的链接,为该用户服务,服务结束后,再为下一个用户服务,只能一个一个的执行
# 为了提高运行效率,可以这样做:每接收到一个请求干脆开一个进程,让这个进程里边的线程去为它服务
#(进程是资源分配的单位,真正在做事情的是子进程里边的主线程)
# 只要创建一个进程,让里边自带一个线程即可
# accept()依旧是一个,让它来接收,将来分配任务的时候让其他人去做
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
"""
用Process创建一个子进程的时候,子进程会复制主进程的资源,能共用就共用,不能共用就复制一份,比如代码就可以共用,叫做写实拷贝
调用Process时,所有的变量(局部,全局)都会复制一份,两者标记了同一个客户端(指向底层的同一个fd(file descriptor)文件故当子
进程调用close()时并不会关闭底层的fd文件,因为主进程中还有指向它的对象,所以要在主进程中再调用一次close(),此时四次挥手才开始
启动
在linux里边,一切设备皆文件(.py文件,压缩包,键盘,鼠标,显示屏,打印机,耳机...),把一切都抽象成文件
同理,标记客户端的套接字说到底,也是一个文件
"""
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
wsgi_sever = WSGISever()
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
03_将web服务器和逻辑处理的代码分开-简易版本,不完全
"""web_sever"""
import socket
import re
import multiprocessing
import time
import mini_frame
"""使用多进程实现多任务"""
class WSGISever(object):
def __init__(self):
"""这一部分为创建套接字,不用进行循环执行,并且是希望在创建对象的同时进行创建套接字"""
"""这个方法不用调用,创建对象的同时直接执行的"""
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",7890))
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
def send_data_to_client(self,new_client_socket):
"""类中定义实例方法,要加上self"""
"""为这个客户端返回数据"""
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print("*"*50)
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.py结尾,那么就认为请求的是静态资源(html/css/js/png/jpg等)
if not file_name.endswith(".py"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open("./html"+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
header = "HTTP/1.1 200 OK\r\n"
header = "\r\n"
# body = "hahahaha %s" % time.ctime() # 浏览器里边看到的结果就是这个ctime()打印出来的东西
body = mini_frame.login()
# 要想获得丰富的变化的数据,核心点是body的内容
# 当前整个程序就是tcp的一个web服务器,他能解析出http的请求,回应http的应答,相当于一个http的服务器
# 说的直白一点,刚刚让它能够解析出动态的资源的请求来而且给它返回了动态的数据是在http服务器里边写的
# 言外之意就是将http服务器的功能与对动态数据的请求以及对请求的处理的实现混在了一起.这就等于在一个
# 大的程序里边实现了两个功能,这是不合理的.
# 应该重新写一个py程序,然后让http服务器去调用它(这是一种解耦的体现)
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 卡在这里,等待一个用户的链接,为该用户服务,服务结束后,再为下一个用户服务,只能一个一个的执行
# 为了提高运行效率,可以这样做:每接收到一个请求干脆开一个进程,让这个进程里边的线程去为它服务
#(进程是资源分配的单位,真正在做事情的是子进程里边的主线程)
# 只要创建一个进程,让里边自带一个线程即可
# accept()依旧是一个,让它来接收,将来分配任务的时候让其他人去做
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
"""
用Process创建一个子进程的时候,子进程会复制主进程的资源,能共用就共用,不能共用就复制一份,比如代码就可以共用,叫做写实拷贝
调用Process时,所有的变量(局部,全局)都会复制一份,两者标记了同一个客户端(指向底层的同一个fd(file descriptor)文件故当子
进程调用close()时并不会关闭底层的fd文件,因为主进程中还有指向它的对象,所以要在主进程中再调用一次close(),此时四次挥手才开始
启动
在linux里边,一切设备皆文件(.py文件,压缩包,键盘,鼠标,显示屏,打印机,耳机...),把一切都抽象成文件
同理,标记客户端的套接字说到底,也是一个文件
"""
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
wsgi_sever = WSGISever()
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
"""mini_frame"""
import time
def login():
return"welcome to our website......time:%s" % time.ctime()
04_将web服务器和逻辑处理的代码分开-升级版
依旧比较低级,无法处理过大量的高并发,可以使用全球比较出名的服务器
"""web_sever"""
import socket
import re
import multiprocessing
import time
import mini_frame
"""使用多进程实现多任务"""
class WSGISever(object):
def __init__(self):
"""这一部分为创建套接字,不用进行循环执行,并且是希望在创建对象的同时进行创建套接字"""
"""这个方法不用调用,创建对象的同时直接执行的"""
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",7890))
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
def send_data_to_client(self,new_client_socket):
"""类中定义实例方法,要加上self"""
"""为这个客户端返回数据"""
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print("*"*50)
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.py结尾,那么就认为请求的是静态资源(html/css/js/png/jpg等)
if not file_name.endswith(".py"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open("./html"+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
header = "HTTP/1.1 200 OK\r\n"
header = "\r\n"
# body = "hahahaha %s" % time.ctime() # 浏览器里边看到的结果就是这个ctime()打印出来的东西
# if file_name == "/login.py":
# body = mini_frame.login()
# elif file_name == "/register.py":
# body = mini_frame.register()
# 如果这样写,解耦程度依旧不够
body = mini_frame.application(file_name) # 调用函数一定要检查是否需要传参
# 通过只调用一个函数,让这个函数再去调用其他函数实现解耦的目的
# 要想获得丰富的变化的数据,核心点是body的内容
# 当前整个程序就是tcp的一个web服务器,他能解析出http的请求,回应http的应答,相当于一个http的服务器
# 说的直白一点,刚刚让它能够解析出动态的资源的请求来而且给它返回了动态的数据是在http服务器里边写的
# 言外之意就是将http服务器的功能与对动态数据的请求以及对请求的处理的实现混在了一起.这就等于在一个
# 大的程序里边实现了两个功能,这是不合理的.
# 应该重新写一个py程序,然后让http服务器去调用它(这是一种解耦的体现)
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 卡在这里,等待一个用户的链接,为该用户服务,服务结束后,再为下一个用户服务,只能一个一个的执行
# 为了提高运行效率,可以这样做:每接收到一个请求干脆开一个进程,让这个进程里边的线程去为它服务
#(进程是资源分配的单位,真正在做事情的是子进程里边的主线程)
# 只要创建一个进程,让里边自带一个线程即可
# accept()依旧是一个,让它来接收,将来分配任务的时候让其他人去做
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
"""
用Process创建一个子进程的时候,子进程会复制主进程的资源,能共用就共用,不能共用就复制一份,比如代码就可以共用,叫做写实拷贝
调用Process时,所有的变量(局部,全局)都会复制一份,两者标记了同一个客户端(指向底层的同一个fd(file descriptor)文件故当子
进程调用close()时并不会关闭底层的fd文件,因为主进程中还有指向它的对象,所以要在主进程中再调用一次close(),此时四次挥手才开始
启动
在linux里边,一切设备皆文件(.py文件,压缩包,键盘,鼠标,显示屏,打印机,耳机...),把一切都抽象成文件
同理,标记客户端的套接字说到底,也是一个文件
"""
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
wsgi_sever = WSGISever()
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
"""mini_frame"""
import time
def login():
return"----longin----welcome to our website......time:%s" % time.ctime()
def register():
return"----register----welcome to our website......time:%s" % time.ctime()
def profile():
return"----profile-----welcome to our website......time:%s" % time.ctime()
def application(file_name): # 要想进行判断需要接收个名称
if file_name == "/login.py":
return login()
elif file_name == "/register.py":
return register()
else:
return "not find your page...."
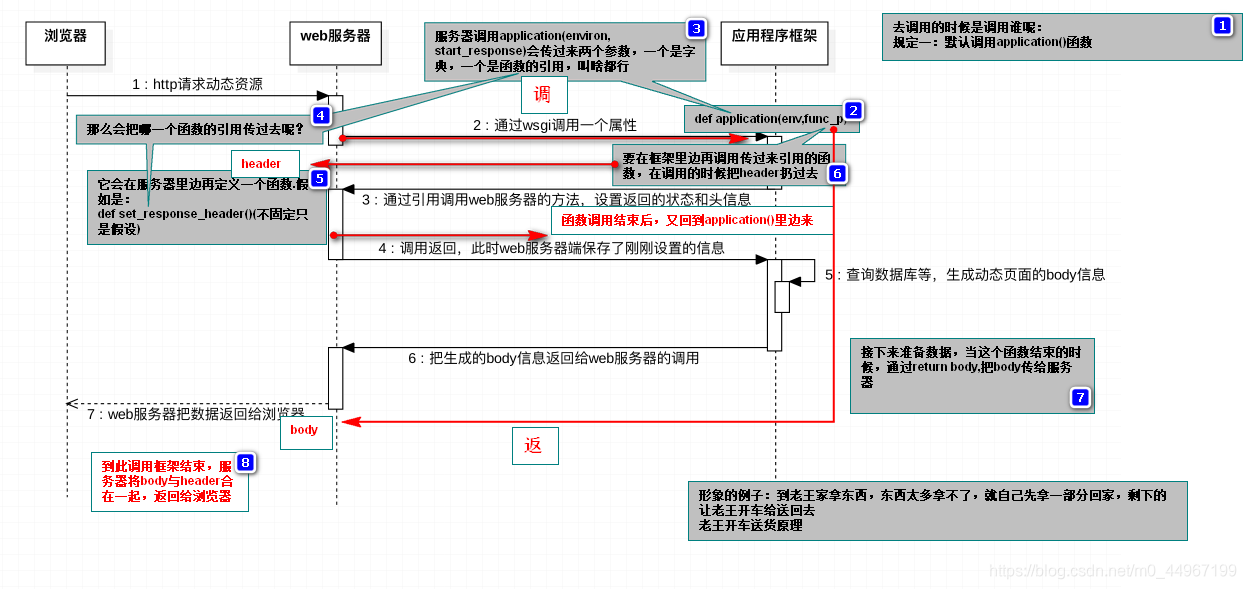
05_让web服务器支持wsgi协议
"""web_sever"""
import socket
import re
import multiprocessing
import time
import mini_frame
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self):
"""这一部分为创建套接字,不用进行循环执行,并且是希望在创建对象的同时进行创建套接字"""
"""这个方法不用调用,创建对象的同时直接执行的"""
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",7890))
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
def send_data_to_client(self,new_client_socket):
"""类中定义实例方法,要加上self"""
"""为这个客户端返回数据"""
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print("*"*50)
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.py结尾,那么就认为请求的是静态资源(html/css/js/png/jpg等)
if not file_name.endswith(".py"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open("./html"+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
body = mini_frame.application(env,self.set_response_header)
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 卡在这里,等待一个用户的链接,为该用户服务,服务结束后,再为下一个用户服务,只能一个一个的执行
# 为了提高运行效率,可以这样做:每接收到一个请求干脆开一个进程,让这个进程里边的线程去为它服务
#(进程是资源分配的单位,真正在做事情的是子进程里边的主线程)
# 只要创建一个进程,让里边自带一个线程即可
# accept()依旧是一个,让它来接收,将来分配任务的时候让其他人去做
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
"""
用Process创建一个子进程的时候,子进程会复制主进程的资源,能共用就共用,不能共用就复制一份,比如代码就可以共用,叫做写实拷贝
调用Process时,所有的变量(局部,全局)都会复制一份,两者标记了同一个客户端(指向底层的同一个fd(file descriptor)文件故当子
进程调用close()时并不会关闭底层的fd文件,因为主进程中还有指向它的对象,所以要在主进程中再调用一次close(),此时四次挥手才开始
启动
在linux里边,一切设备皆文件(.py文件,压缩包,键盘,鼠标,显示屏,打印机,耳机...),把一切都抽象成文件
同理,标记客户端的套接字说到底,也是一个文件
"""
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
wsgi_sever = WSGISever()
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
"""mini_frame"""
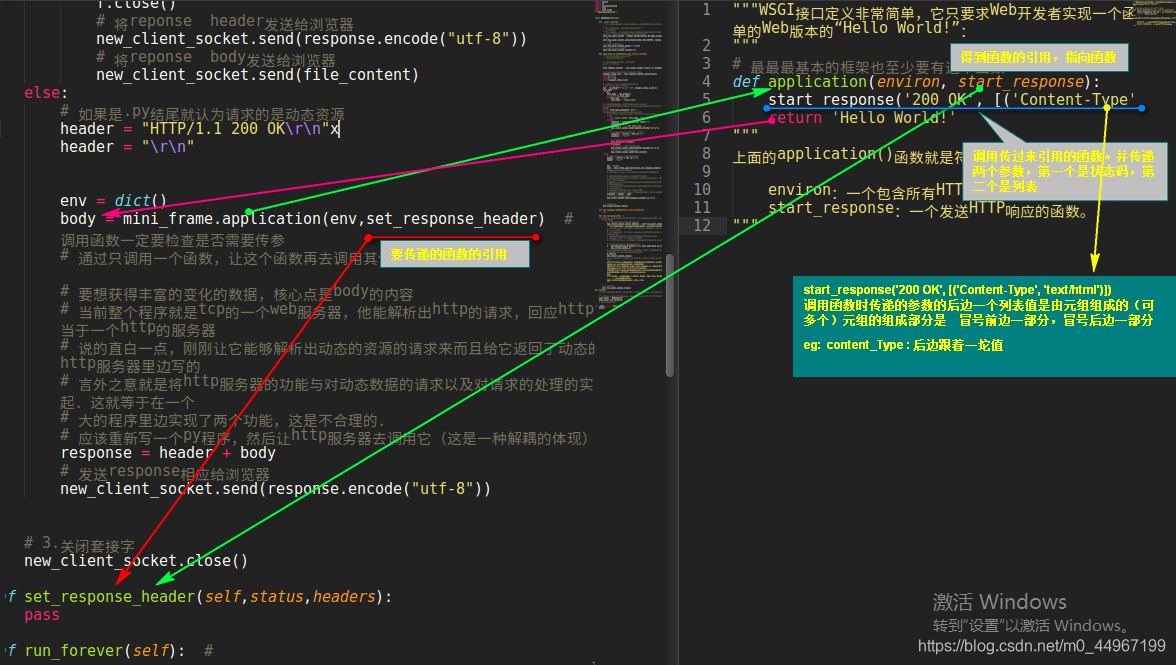
"""WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。我们来看一个最简单的Web版本的“Hello World!”:
"""
# 最最最基本的框架也至少要有这个函数
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
return 'Hello World! 我爱你,中国!'
"""
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
environ:一个包含所有HTTP请求信息的dict对象;
start_response:一个发送HTTP响应的函数。
"""
06_通过传递字典实现浏览器请求的资源的不同,而做出不同的响应
目的:验证学习传递的字典的用处
"""web_sever"""
import socket
import re
import multiprocessing
import time
import mini_frame
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self):
"""这一部分为创建套接字,不用进行循环执行,并且是希望在创建对象的同时进行创建套接字"""
"""这个方法不用调用,创建对象的同时直接执行的"""
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",7890))
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
def send_data_to_client(self,new_client_socket):
"""类中定义实例方法,要加上self"""
"""为这个客户端返回数据"""
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print("*"*50)
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.py结尾,那么就认为请求的是静态资源(html/css/js/png/jpg等)
if not file_name.endswith(".py"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open("./html"+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# {"PATH_INFO":"/index.py"}
# 这里之所以使用字典传值,因为将来服务器调用框架里边的函数的时候,有可能传递多个
#值,比如file_name,服务器版本,浏览器版本....
body = mini_frame.application(env,self.set_response_header)
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 卡在这里,等待一个用户的链接,为该用户服务,服务结束后,再为下一个用户服务,只能一个一个的执行
# 为了提高运行效率,可以这样做:每接收到一个请求干脆开一个进程,让这个进程里边的线程去为它服务
#(进程是资源分配的单位,真正在做事情的是子进程里边的主线程)
# 只要创建一个进程,让里边自带一个线程即可
# accept()依旧是一个,让它来接收,将来分配任务的时候让其他人去做
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
"""
用Process创建一个子进程的时候,子进程会复制主进程的资源,能共用就共用,不能共用就复制一份,比如代码就可以共用,叫做写实拷贝
调用Process时,所有的变量(局部,全局)都会复制一份,两者标记了同一个客户端(指向底层的同一个fd(file descriptor)文件故当子
进程调用close()时并不会关闭底层的fd文件,因为主进程中还有指向它的对象,所以要在主进程中再调用一次close(),此时四次挥手才开始
启动
在linux里边,一切设备皆文件(.py文件,压缩包,键盘,鼠标,显示屏,打印机,耳机...),把一切都抽象成文件
同理,标记客户端的套接字说到底,也是一个文件
"""
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
wsgi_sever = WSGISever()
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
"""mini_frame"""
def index():
return"欢迎进入index界面!"
def login():
return"欢迎进入login界面!"
# 最最最基本的框架也至少要有这个函数
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/login.py":
return login()
else:
return'Hello World! 我爱你,中国!'
07_实现模版文件-替换数据
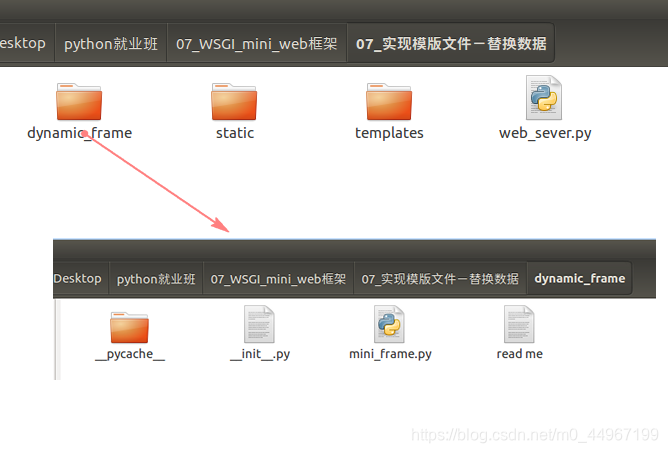
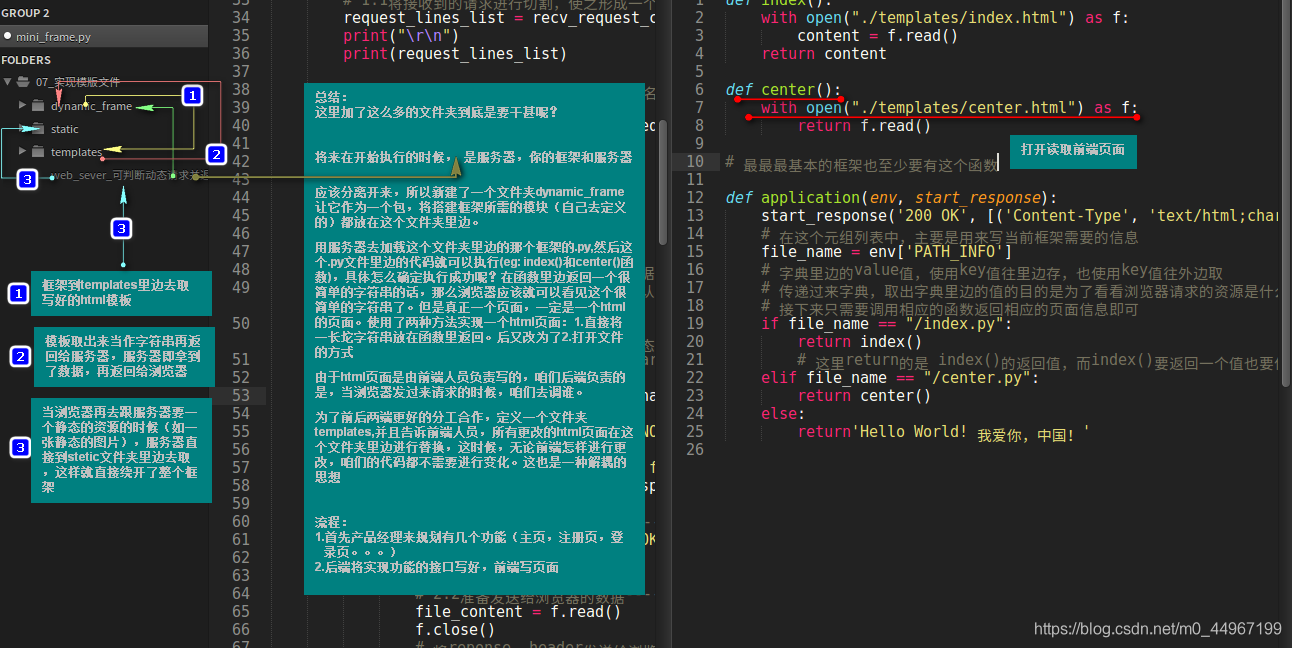
在dynamic_frame这个文件夹里边写框架,把这个文件夹看作是一个包,里边就可以存放多个模块了,因为一个框架可能有多个模块组成,即里边包含着多个.py文件.在python2中一定要写一个__init__,在python3中可以不用写
"""web_sever"""
import socket
import re
import multiprocessing
import time
import dynamic_frame.mini_frame # 包里的模块导入方式
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self):
"""这一部分为创建套接字,不用进行循环执行,并且是希望在创建对象的同时进行创建套接字"""
"""这个方法不用调用,创建对象的同时直接执行的"""
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",7890))
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
def send_data_to_client(self,new_client_socket):
"""类中定义实例方法,要加上self"""
"""为这个客户端返回数据"""
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.py结尾,那么就认为请求的是静态资源(html/css/js/png/jpg等)
if not file_name.endswith(".py"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open("./static"+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
body = dynamic_frame.mini_frame.application(env,self.set_response_header)
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 卡在这里,等待一个用户的链接,为该用户服务,服务结束后,再为下一个用户服务,只能一个一个的执行
# 为了提高运行效率,可以这样做:每接收到一个请求干脆开一个进程,让这个进程里边的线程去为它服务
#(进程是资源分配的单位,真正在做事情的是子进程里边的主线程)
# 只要创建一个进程,让里边自带一个线程即可
# accept()依旧是一个,让它来接收,将来分配任务的时候让其他人去做
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
"""
用Process创建一个子进程的时候,子进程会复制主进程的资源,能共用就共用,不能共用就复制一份,比如代码就可以共用,叫做写实拷贝
调用Process时,所有的变量(局部,全局)都会复制一份,两者标记了同一个客户端(指向底层的同一个fd(file descriptor)文件故当子
进程调用close()时并不会关闭底层的fd文件,因为主进程中还有指向它的对象,所以要在主进程中再调用一次close(),此时四次挥手才开始
启动
在linux里边,一切设备皆文件(.py文件,压缩包,键盘,鼠标,显示屏,打印机,耳机...),把一切都抽象成文件
同理,标记客户端的套接字说到底,也是一个文件
"""
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
wsgi_sever = WSGISever()
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
"""mini_frame"""
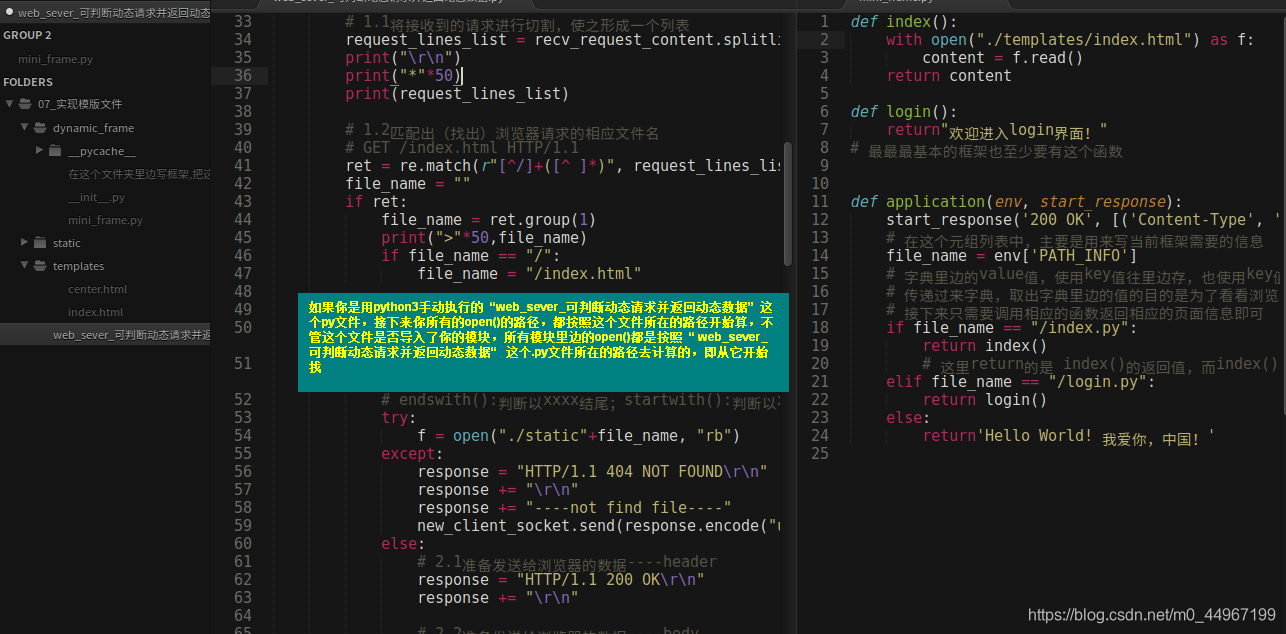
def index():
with open("./templates/index.html") as f:
content = f.read()
return content
def center():
with open("./templates/center.html") as f:
return f.read()
# 最最最基本的框架也至少要有这个函数
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
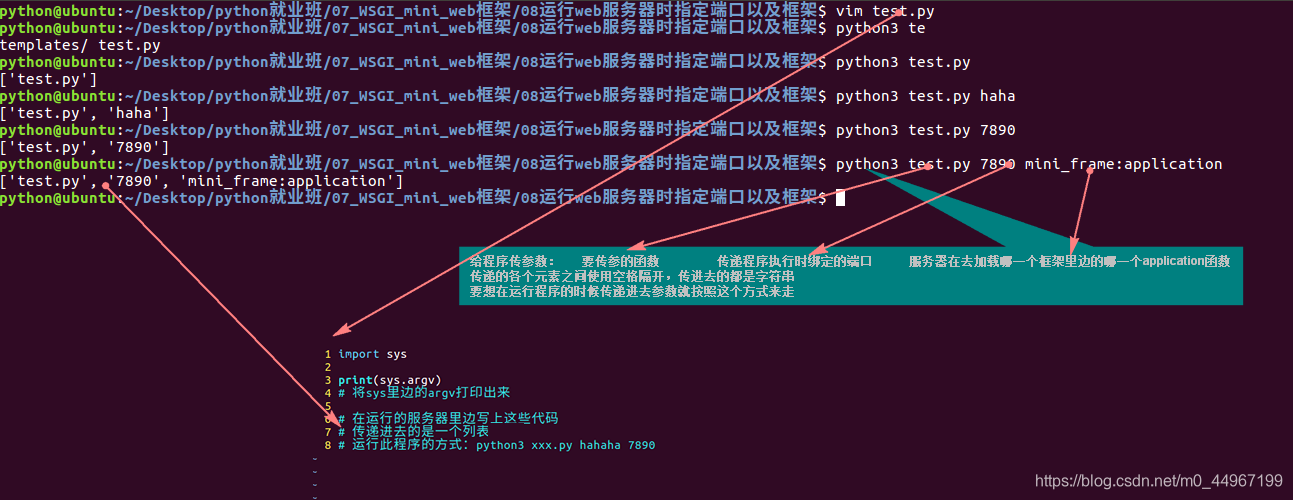
08运行web服务器时指定端口以及框架
要处理的问题:
1.能不能改端口,怎么改 如果说从网上下载下来一个服务器,里边写的端口加入被占用,服务器就无法运行
2.怎么在不修改服务器的前提下支持其他的框架
"""web_sever"""
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.py结尾,那么就认为请求的是静态资源(html/css/js/png/jpg等)
if not file_name.endswith(".py"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open("./static"+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
sys.path.append("./dynamic_frame")
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application)
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
"""mini_frame"""
def index():
with open("./templates/index.html") as f:
content = f.read()
return content
def center():
with open("./templates/center.html") as f:
return f.read()
# 最最最基本的框架也至少要有这个函数
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
09_让web服务器支持配置文件
要处理的问题:
sys.path.append("./dynamic_frame")
f = open("./static"+file_name, “rb”)
在 08运行web服务器时指定端口以及框架 这一节中,实现的不再固定的写入端口和导入模块,实现了很大程度上的解耦,但是不够彻底,
在上边的两行代码中dynamic_frame 和static,依旧是两个固定的文件名称,要找到相应的文件必须在他们里边找--故需要配置文件
"""web_sever"""
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application,static_path):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
self.static_path = static_path
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.py结尾,那么就认为请求的是静态资源(html/css/js/png/jpg等)
if not file_name.endswith(".py"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open(self.static_path+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
with open("./web_sever_conf") as f:
conf_info = eval(f.read())
# 此时conf_info是一个字典,里面的数据为:
# {
# "static_path":"./static",
# "dynamic_frame_path":"./dynamic_frame"
# }
# 此处的核心操作是:将要配置的文件(即在程序中要用到的文件夹)以字典的形式(由于不是在.py文件里边,实际上是字符串)存储在一个普通文件里,使用的时候转成字典使用,使用字典的key值去对应
# 相应的文件,这样在配置文件的时候就不用改程序了,只需要叫相应的文件写在普通文件的"value"值里边即可
# 类里边的方法要使用主函数的变量值的时候一定要进行传参,即在创建对象的时候把参数传进去
# 传进初始化方法__init__方法中,并在该方法中用self.定义成实例属性,才能由别的方法
# 通过self.的方式调用
sys.path.append(conf_info['dynamic_frame_path'])
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application,conf_info['static_path'])
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
"""mini_frame"""
def index():
with open("./templates/index.html") as f:
content = f.read()
return content
def center():
with open("./templates/center.html") as f:
return f.read()
# 最最最基本的框架也至少要有这个函数
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
02_闭包-装饰器
01_闭包
# 问题:初中学过的函数,例如 y = kx + b, y = ax^2 + bx + c
# 以y = kx + b为例,请计算出一条线上的几个点,即给出x值,求出y值
# 第一种方案:
# k = 1
# b = 2
# y = kx + b
# 缺点:如果需要多次计算,那么就需要写多次y = kx + b这样的式子
# 第二种方案:
def line_2(k,b,x):
print(k*x+b)
line_2(1,2,0)
line_2(1,2,1)
line_2(1,2,2)
# 缺点:由于直线是不变的,给定的k,b的值每次计算y值的时候都需要传递,十分麻烦
print("-"*50)
# 第三种方案:
"""定义全局变量解决方案二的问题"""
k = 1
b = 2
def line_3(x):
print(k*x+b)
line_3(0)
line_3(1)
line_3(2)
# 缺点:假如说要去计算多条线,需要去不断修改全局变量,十分麻烦
print("-"*50)
# 第四种方案
"""使用缺省参数解决"""
def line_4(x,k=1,b=2):
print(k*x+b)
line_4(0)
line_4(1)
line_4(2)
# 此时换一条线的做法
line_4(0,k=11,b=22)
line_4(1,k=11,b=22)
line_4(2,k=11,b=22)
# 缺点:如果要计算多条线的值,依旧是每一次都需要传递参数,比较麻烦,
# 优点是:比全局变量法好的地方:具有封装性,k,b是函数line_4的一部分,而不是全局变量, 因为全局变量可以任意的被其他函数修改,而封装起来之后只能在函数内部传递,其他地方无法修改
print("-"*50)
# 第五种方案
class line_5(object):
"""创建对象的时候指定k,b调用的时候就不用传递k,b的值了"""
def __init__(self,k,b):
self.k = k
self.b = b
# 如果不使用self.的方式保存k,b的值,那么它们的值会随着方法的调用的结束而结束
# 而使用self.的方式定义成属性,就不会随着调用方法的结束而结束,而是会随着创建出来的对象的存在而存在,即要想存到对象里边去,就一定要加self.
def __call__(self,x):
print(self.k * x + self.b)
line_5_1 = line_5(1,2)
line_5_1(0)
# 按照正常的调用对象里边的方法的形式应该是:对象.方法().在这里却直接使用了:对象()
# 涉及知识点:只要类(父类里边有也可以)中有__call__方法,那么这个类创建出来的对象就可以直接使用:对象()
# 调用执行__call__方法
line_5_1(1)
line_5_1(2)
line_5_2 = line_5(11,22)
line_5_2(0)
line_5_2(1)
line_5_2(2)
# 缺点:为了计算多条线上的y值,所以要保存多个k,b的值,就要创建多个对象(包含一堆魔法属性,魔法方法),每个对象都占有较多的资源.因此用了多个实例对象,浪费资源
#
#
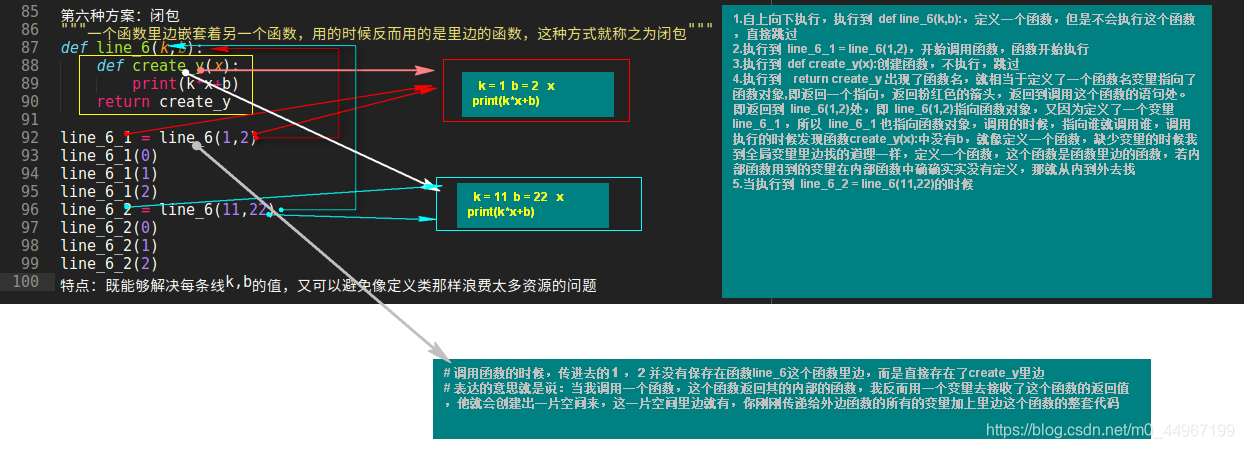
# 第六种方案:闭包
"""一个函数里边嵌套着另一个函数,用的时候反而用的是里边的函数,一般来说,内部函数会用到外部函数里边的变量,咱们就把里边这个函数的这一坨代码以及用到的外部函数的变量这个整体就称之为闭包"""
def line_6(k,b):
def create_y(x):
print(k*x+b)
return create_y # 可以当做实参传递?意思就是 传递引用?
line_6_1 = line_6(1,2)
# 调用函数的时候,传进去的1,2并没有保存在函数line_6这个函数里边,而是直接存在了create_y里边
# 表达的意思就是说:当我调用一个函数,这个函数返回其的内部的函数,我反而用一个变量去接收了这个函数的返回值,他就会创建出一片空间来,这一片空间里边就有,你刚刚传递给外边函数的所有的变量加上里边这个函数的整套代码
line_6_1(0)
line_6_1(1)
line_6_1(2)
line_6_2 = line_6(11,22)
line_6_2(0)
line_6_2(1)
line_6_2(2)
# 特点:既能够解决每条线k,b的值,创建出来的小空间里边既有数据,又有执行的代码,又可以避免像定义类那样浪费太多资源的问题.用来如果你想有一个变量以及以及想有一个对这个变量应用的东西,你想成为一个整体,你就完全可以把它封装成一个闭包
# 就像面向对象的思想一样,都有自己的独立的空间,里边存储着自己的变量和代码,比函数高级在调用函数名时,不仅可以传代码过去,还可以将一部分数据传过去
# 几个部分的特点分析:
# 1.函数:可以把一坨代码封装成一个小整体,通过调用函数名就可以调用函数.就是一坨代码,不会把用到的数据也传过去
# 2.匿名函数:也是函数,可以封装一部分代码,已经有了def定义的函数,为什么还要有匿名函数? 简单
# 可以完成小功能的实现编写,当做实参的时候相当方便
# 3.闭包:比函数要高端,高端在不仅同时可以给你代码,还可以给你这个代码需要用到的数据
# 4.对象:如果将对象的引用给了你,你拿到的是什么?
# 实例对象的引用给了你,你拿到的是一个对象,这个对象里边任何方法可以调,任何属性可以调,不管用不用,只要引用传过去了就一定都过去了,而通过闭包可以实现只传一部分小数据,即对象要比闭包功能更多更复杂
02_闭包修改数据
x = 300
def test1():
x = 200
def test2():
nonlocal x
# 就行修改全局变量要写globle一样,修改闭包内的变量要写nonlocal
print("-----1-----x = %d" % x)
x = 100
print("-----1-----x = %d" % x)
return test2
# 这里返回的时候不能加"()"因为加上之后就相当于调用函数,返回的就是函数的返回值了,
# 不加返回的才是函数的引用
t1 = test1()
t1()
03_修饰器/装饰器
当我想要调用一个函数的时候,我可以在不修改这个函数里边的原码的前提下,可以对它进行功能的修改.
01_装饰器的演示
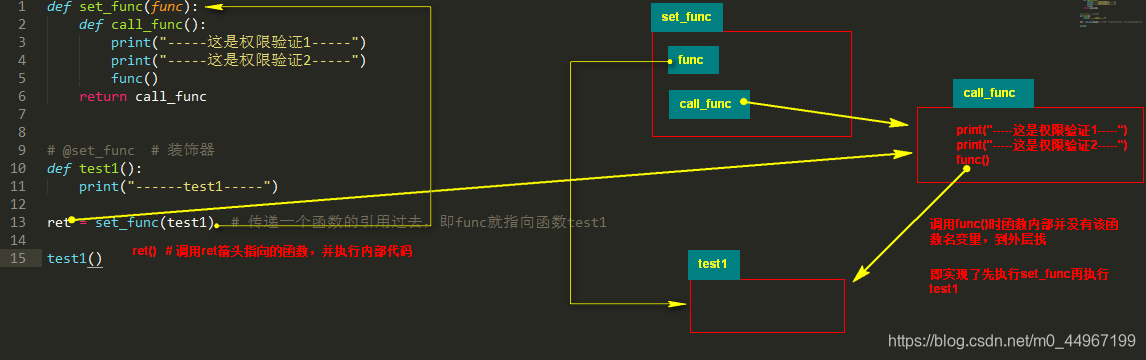
def set_func(func):
def call_func():
print("-----这是权限验证1-----")
print("-----这是权限验证2-----")
func()
return call_func
"""
什么东西叫做装饰器?
功能:
要修改函数test1的功能,即在这个函数调用之前要加一部分代码,那么有两种方案来执行:
1.在函数内部加代码
2.在函数的外边定义一个闭包,并在test1上边写上一个@闭包外层函数名,接下来程序里边该怎么调的地方就怎么调,
但唯独不一样的地方在于,它是先执行@符号后边的函数再执行test1
即装饰器的作用:能够在原来的代码不修改的前提下,给函数整体加功能(即老板分配的家权限的任务)
"""
@set_func # 装饰器
def test1():
print("------test1-----")
test1()


02_闭包修改数据
x = 300
def test1():
x = 200
def test2():
nonlocal x
# 就行修改全局变量要写globle一样,修改闭包内的变量要写nonlocal
print("-----1-----x = %d" % x)
x = 100
print("-----1-----x = %d" % x)
return test2
# 这里返回的时候不能加"()"因为加上之后就相当于调用函数,返回的就是函数的返回值了,
# 不加返回的才是函数的引用
t1 = test1()
t1()
03_装饰器的实现过程
set_func(func):
def call_func():
print("-----这是权限验证1-----")
print("-----这是权限验证2-----")
func()
return call_func
@set_func # 装饰器/修饰器 等价于:test1 = set_func(test1)
# 装饰器可以实现要么在这个函数之前做事情,要么在这个函数之后做事情,但不能在这个函数的一部分(中间)做事情
def test1():
print("------test1-----")
# ret = set_func(test1) # 传递一个函数的引用过去,即func就指向函数test1
# ret()
# test1 = set_func(test1) # 看一句代码,要先看等号右边的语句
test1()
# 装饰器的核心点是:把原来的一个函数的引用当做实参传递到另外一个闭包里边,然后这个闭包不是里边有代码还有变量吗,
# 我把这个引用传到外部函数的变量里边去,外边那个变量只要存上了,那么接下来什么时候去调用闭包里边的函数的时候
# 我什么时候去调用外部函数变量中存的函数的引用,意味着就是调用原函数
#
# 装饰器最终的表现形式是:在不改变调用的函数的情况下,能做到对原函数的功能的扩展
接下来要研究的问题:
装饰器对一个函数是可以使用多次呢?还是只能用一次呢?
装饰器可以对什么函数装呢?有参数的?无参数的?有返回值?
能不能对多个函数装?能不能对单个函数装多个?
04_装饰器的作用-装饰器计算原函数test()的运行时间
import time
# 装饰器计算原函数test1()运行时间
def set_func(func):
def call_func():
start_time = time.time()
func()
stop_time = time.time()
print("the function runs alltimes %f" % (stop_time - start_time))
return call_func
@set_func # 装饰器/修饰器 等价于:test1 = set_func(test1)
# 装饰器可以实现要么在这个函数之前做事情,要么在这个函数之后做事情,但不能在这个函数的一部分(中间)做事情
def test1():
print("------test1-----")
# ret = set_func(test1) # 传递一个函数的引用过去,即func就指向函数test1
# ret()
# test1 = set_func(test1)
test1()
05_对没有参数没有返回值的函数进行装饰
import time
# 装饰器计算原函数test1()运行时间
def set_func(func):
def call_func():
start_time = time.time()
func()
stop_time = time.time()
print("the function runs alltimes %f" % (stop_time - start_time))
return call_func
@set_func # 装饰器/修饰器
def test1():
print("------test1-----")
test1()
06_对有参数无返回值的函数进行装饰
def set_func(func):
def call_func(a):
print("-----这是权限验证1-----")
print("-----这是权限验证2-----")
func(a)
return call_func
"""
如果被装饰的函数有参数,将来调用的时候一定有参数,闭包里边也要有相应接受参数和调用参数
有参数是需要按照执行顺序层层传递下去
"""
@set_func # 装饰器/修饰器
def test1(num):
print("------test1-----%d" % num)
test1(100)
07_同一个装饰器对多个函数进行装饰
def set_func(func):
def call_func(a):
print("-----这是权限验证1-----")
print("-----这是权限验证2-----")
func(a)
return call_func
"""
使用同一个装饰器对多个函数进行装饰,每执行一次@set_func就相当于创建了一个闭包
(即开辟一个空间,里边放着,闭包内部函数的代码和外部函数的变量),闭包里边的变量指向原来的函数
装一个函数就创建一个闭包
"""
@set_func # 装饰器/修饰器 等价于:test1 = set_func(test1)
def test1(num):
print("------test1-----%d" % num)
@set_func # 装饰器/修饰器 等价于:test2 = set_func(test2)
def test2(num):
print("------test2-----%d" % num)
test1(100)
test2(200)
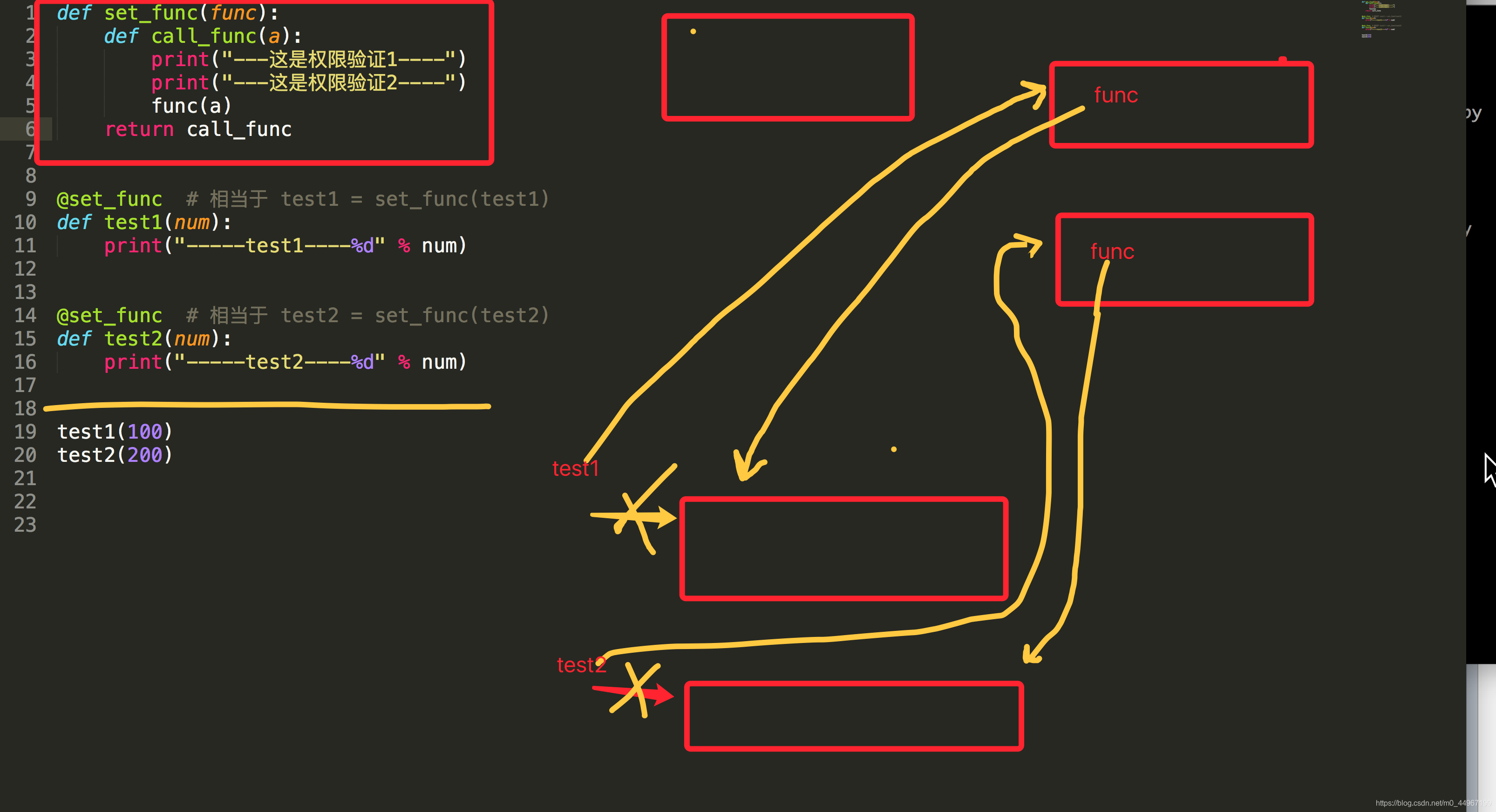
08_装饰器在没有开始调用函数之前就开始装饰了
def set_func(func):
print("----开始装饰了----")
def call_func(a):
print("-----这是权限验证1-----")
print("-----这是权限验证2-----")
func(a)
return call_func
"""
使用同一个装饰器对多个函数进行装饰,每执行一次@set_func就相当于创建了一个闭包
(即开辟一个空间,里边放着,闭包内部函数的代码和外部函数的变量),闭包里边的变量指向原来的函数
装一个函数就创建一个闭包
"""
@set_func # 装饰器/修饰器 等价于:test1 = set_func(test1)
def test1(num):
print("------test1-----%d" % num)
# 这里没有调用test1
# 装饰器是随着python解释器自上而下执行,只要遇到@就开始执行,不是随着test1的调用开始装的
# @set_func # 装饰器/修饰器 等价于:test2 = set_func(test2)
# def test2():
# print("------test2-----%d" % num)
# test1(100)
# test2(200)
09_使用装饰器对不定长参数函数进行装饰
def set_func(func):
print("----开始装饰了----")
def call_func(*args,**kwargs):
# *args,**kwargs是不定长参数,可有可没有
# *不是变量名的一部分,是告诉解释器这个args可以保存多个,100就在args里边以元组的身份保存
# *告诉解释器多余的参数都给args,**告诉解释器多余的关键字参数都给kwargs
print("-----这是权限验证1-----")
print("-----这是权限验证2-----")
func(*args,**kwargs)
# 此处的*/**告诉python解释器这是拆包,拆成一个个变量等于什么,和上边的正好相反
return call_func
"""
结论:如果想让你的装饰器对有参数的,有一个,有两个...有n个这样的参数,怎么进行装饰呢?
直白一点,直接写不定长参数(*args,**kwargs),一定可以解决问题,没有参数也可以装饰
接收到的时候以不定长参数接收,传递的时候切记拆包的传,一旦写成(args,kwargs)就完了,因为
这样就相当于传递了两个参数,一个元组(将放在元组中的一个个变量看做一个元组),一个字典(将放
在字典中的一个个关键字参数,看做一个字典)
"""
@set_func # 装饰器/修饰器 等价于:test1 = set_func(test1)
def test1(num,*args,**kwargs):
print("------test1-----%d" % num)
print("------test1-----" ,args) # 先输出引号内部的内容,在输出逗号后边的元组中的内容
print("------test1-----" ,args,kwargs)
test1(100)
test1(100, 200)
test1(100, 200, 300, mm=100)
010_对有返回值的函数进行装饰
def set_func(func):
"""通用装饰器模版"""
def call_func(*args,**kwargs):
print("-----这是权限验证1-----")
print("-----这是权限验证2-----")
return func(*args,**kwargs)
return call_func
"""
总结:
如果想要对函数进行装饰,不管它有没有参数,有没有返回值,有几个参数,你怎么写这样的装饰器一定
是一个通用的装饰器呢?
1.使用(*args,**kwargs)来接收不定长参数;
2.在去调用的时候使用(*args,**kwargs)来进行拆包;
3.在调用原函数的地方(eg:func())写上一个return
"""
@set_func # 装饰器/修饰器 等价于:test1 = set_func(test1)
def test1(num,*args,**kwargs):
print("------test1-----%d" % num)
print("------test1-----" ,args) # 先输出引号内部的内容,在输出逗号后边的元组中的内容
print("------test1-----" ,args,kwargs)
return "ok"
# return 到哪去?谁调的你,你就return到哪里去,即返回到func()处,但是由于该出没有
# 定义变量接收,即无法实现返回,打印出来的值为NONE
@set_func
def test2(num):
pass
ret = test1(100)
print(ret)
ret = test2(100)
print(ret)
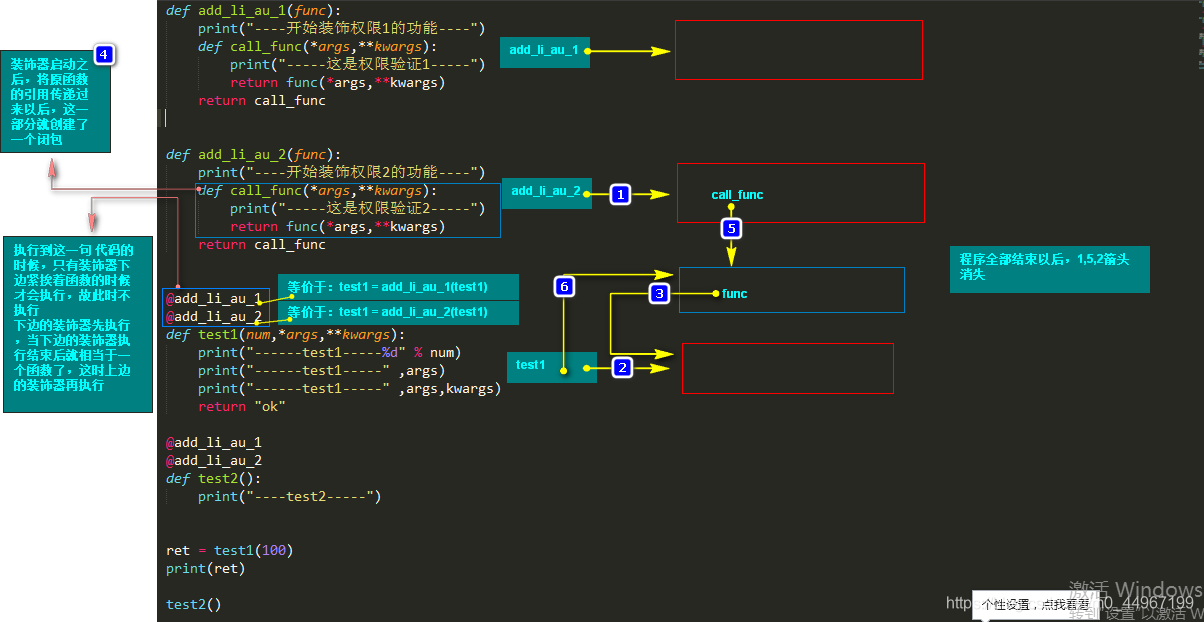
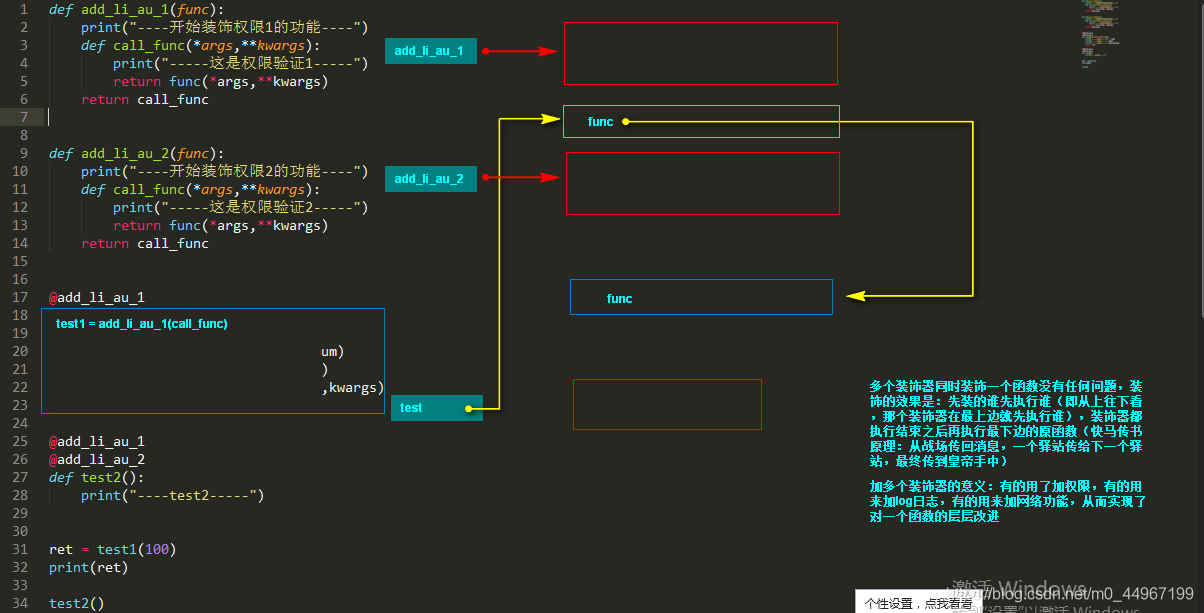
011_多个装饰器对同一个函数进行装饰
def add_li_au_1(func):
print("----开始装饰权限1的功能----")
def call_func(*args,**kwargs):
print("-----这是权限验证1-----")
return func(*args,**kwargs)
return call_func
def add_li_au_2(func):
print("----开始装饰权限2的功能----")
def call_func(*args,**kwargs):
print("-----这是权限验证2-----")
return func(*args,**kwargs)
return call_func
@add_li_au_1
@add_li_au_2
def test2():
print("----test2-----")
test2()

012_使用多个装饰器对同一个函数进行装饰-demo
# 不改变原函数进行增加功能
def add_tag_out1(content):
def add_tag_in1():
return"<td>" + content() + "</td>"
# 这里的content务必写加括号的形式,因为这里要获取函数内的内容,需要调用
return add_tag_in1
def add_tag_out2(content):
def add_tag_in2():
return"<h1>" + content() + "</h1>"
return add_tag_in2
@add_tag_out1
@add_tag_out2
def get_str():
return "hahaha"
print(get_str())

013_使用类当做装饰器
"""了解"""
# 不改变原函数进行增加功能
# def add_tag_out1(content):
# def add_tag_in1():
# return"<td>" + content() + "</td>"
# # 这里的content务必写加括号的形式,因为这里要获取函数内的内容,需要调用
# return add_tag_in1
class Test(object):
def __init__(self,func):
self.func = func
def __call__(self):
print("这里是装饰器添加的功能----")
return self.func()
@Test # 相当于get_str = Test(get_str)
# Test(get_str)类名加括号相当于创建了一个实例对象,并将get_str当做参数传给了
# 类里边的__init__方法,即由于get_str = Test(get_str),get_str不再指向函数了,而是指向了实例对象了
def get_str():
return "hahaha"
print(get_str())
# 写一个实例对象名括起来get_str()是调谁?
# 会直接调用__call__方法
04_mini_web框架添加路由和MYSQL功能
01_带有参数的装饰器
带有参数的装饰器1
def set_func(func):
def call_func(*args,**kwargs):
level = args[0]
if level == 1:
print("-----权限级别1, 验证------")
elif level == 2:
print("-----权限级别2, 验证------")
return call_func
"""
要实现不同的函数使用同一个装饰器调用不同的权限功能
方法一:(不好)
调用函数时传参并使用if语句进行判断
此方法存在的问题:装饰器一般不会影响到你将来调用函数时传递的参数的个数,即原函数没有写参数
将来调用的时候就不应该写参数,调用函数时传的参数目的是给call_func传的不是给原函数传的.
故问题一:
假设此时原函数(test1)已经被调用了100次,那么每一次都要在调用的时候写上一个1,很麻烦
问题二:
每次要调用哪个权限都是自己输入的完全失去了设置权限的意义,就相当于自己出卷自己判卷.
应该由别来设置才有效,公平
"""
@set_func
def test1():
print("-----test1-----")
return "ok"
@set_func
def test2():
print("------test2------")
return "ok"
test1(1)
test2(2)
# 此处往函数里边传值的思路就是错误的
带有参数的装饰器2-正确版
def set_level(level_num):
def set_func(func):
def call_func(*args,**kwargs):
if level_num == 10:
print("-----权限级别10, 验证------")
elif level_num == 2:
print("-----权限级别2, 验证------")
return call_func
return set_func
"""
装饰器带参数就相当于两步:
1.调用set_func,并且将1作为实参 传递,不再传递test1
2.用上一步调用的返回值,当做装饰器 对test1函数进行装饰
原来是用set_func直接装饰,(有两个函数可以装),现在使用返回的call_func装饰(@call_func)(只有一个函数无法进行装饰)
所以,对带有装饰器的函数进行装饰,先把基本的装饰器写完(两个函数的),外边再套一个函数
正确的执行方式是:
1.使用set_level进行装饰,即调用set_level,执行到def set_func(func):创建一个函数,但不会立马执行,跳转到return set_func执行
2.返回set_func之后意味着,此时变成了拿着set_func对test1进行装饰,并且此时@set_func并没有带括号(即不带参数的装饰器)
分析"真正的装饰器"外边加两层函数的目的是什么呢?
最外边这层让你保存一个数字,里边这层让你保存了一个函数的引用.最里边的函数去调用中间层的函数,去使用最外层的值
"""
@set_level(10)
def test1():
print("-----test1-----")
return "ok"
@set_level(2)
def test2():
print("------test2------")
return "ok"
test1()
test2()
"""
两种方案的区别:
这个方案只需要更改函数装饰器这一地方其他所有调用的地方都不用改,而上一个方案需要将所有调用的地方都要改一遍
并且设置什么权限应该是由函数的制定者设置的而不是使用者调用的
"""
02_实现mini_frame中的路由功能
web_server
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application,static_path):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
self.static_path = static_path
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.py结尾,那么就认为请求的是静态资源(html/css/js/png/jpg等)
if not file_name.endswith(".py"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open(self.static_path+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
with open("./web_sever_conf") as f:
conf_info = eval(f.read())
# 此时conf_info是一个字典,里面的数据为:
# {
# "static_path":"./static",
# "dynamic_frame_path":"./dynamic_frame"
# }
# 此处的核心操作是:将要配置的文件(即在程序中要用到的文件夹)以字典的形式(由于不是在.py文件里边,实际上是字符串)存储在一个普通文件里,使用的时候转成字典使用,使用字典的key值去对应
# 相应的文件,这样在配置文件的时候就不用改程序了,只需要叫相应的文件写在普通文件的"value"值里边即可
# 类里边的方法要使用主函数的变量值的时候一定要进行传参,即在创建对象的时候把参数传进去
# 传进初始化方法__init__方法中,并在该方法中用self.定义成实例属性,才能由别的方法
# 通过self.的方式调用
sys.path.append(conf_info['dynamic_frame_path'])
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application,conf_info['static_path'])
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
web_frame
def index():
with open("./templates/index.html") as f:
content = f.read()
return content
def center():
with open("./templates/center.html") as f:
return f.read()
# 最最最基本的框架也至少要有这个函数
URL_FUNC_DICT = {
"/index.py":index,
"/center.py":center
}
# 定义全局变量的时候,尽量使用大写字母或者在变量前加一个G/g,表示全局变量
# python解释器是从上到下执行的,故定义变量要在使用之前
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
"""
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
"""
"""
这里通过if语句判断,web框架需要返回什么内容,要是有n多个页面要打开,那岂不是要n个if判断???!!!
一般超过5,6个就不应该用这个解决方案
这肯定不是通用的解法
通用解法的思路:
以前在调用字典的时候,先定义一个字典,里边有很多值,你调用这个字典的时候,用一个中括号,你写不一样的key值将来的返回值就不一样
以字典中取值的思路来思考这个问题
此处问题的核心就是,不想自己写这么多恶心的if判断,想实现根据你的不同的请求,让它自动去调不同的函数
思路:
用一个字典,字典里边让请求的url(网址)这个资源文件当作key,方法名(函数的引用)当做value值,那么最终
我给你一个key值,就返回一个value,又因为value是一个函数的引用,当然可以括起来直接调用了
这种方法代码量不一定少,但是这个调用过程一定是一种优化
缺点:每次往字典里边写东西依旧比较麻烦,最好找个东西直接让字典里边含有相应的内容
"""
func = URL_FUNC_DICT[file_name] # 不管字典中有多少个值,只要传过来的file_name有与之匹配的key值就可以找到相应的函数的引用
return func() # 调用函数,因为调用的函数有返回值,所以加上一个return
03_实现mini_frame中的路由功能-装饰器实现
web_server
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application,static_path):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
self.static_path = static_path
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.py结尾,那么就认为请求的是静态资源(html/css/js/png/jpg等)
if not file_name.endswith(".py"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open(self.static_path+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
with open("./web_sever_conf") as f:
conf_info = eval(f.read())
# 此时conf_info是一个字典,里面的数据为:
# {
# "static_path":"./static",
# "dynamic_frame_path":"./dynamic_frame"
# }
# 此处的核心操作是:将要配置的文件(即在程序中要用到的文件夹)以字典的形式(由于不是在.py文件里边,实际上是字符串)存储在一个普通文件里,使用的时候转成字典使用,使用字典的key值去对应
# 相应的文件,这样在配置文件的时候就不用改程序了,只需要叫相应的文件写在普通文件的"value"值里边即可
# 类里边的方法要使用主函数的变量值的时候一定要进行传参,即在创建对象的时候把参数传进去
# 传进初始化方法__init__方法中,并在该方法中用self.定义成实例属性,才能由别的方法
# 通过self.的方式调用
sys.path.append(conf_info['dynamic_frame_path'])
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application,conf_info['static_path'])
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
实现了对dynamic_frame里边的web框架的改进
具体改进思路:
功能改进:
对于web服务器发过来的请求,使用带参数的装饰器将请求在调用函数之前就放入字典中,从而实现只要针对不同放入key值调用不同的value对应的函数即可.实现自动往字典中添加值,不用再提前手动添加
web_frame
URL_FUNC_DICT = dict()
# func_list = list()
def route(url): # route: 路由
def set_func(func):
# func_list.append(func) # 将每一个传进来的函数的引用放进列表里边 直接放在字典里边
# 就相当于URL_FUNC_DICT["/index.py"] = index
URL_FUNC_DICT[url] = func
def call_func(*args,**kwargs):
return func(*args,**kwargs)
return call_func
return set_func
"""
路由:根据你的请求不一样,调用的功能不同,实现路由的核心原因应用到了映射
只要一用装饰器,被装饰的函数的引用就会传进装饰器函数里边,定义一个列表,
将每一个传进装饰器函数的函数的引用放进列表中
得到函数的引用之后,只要再保证怎么对应每个函数的引用即可
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
"""
这个使用装饰器解决问题的思想比较重要,学会怎么用来解决问题,因为装饰器是这个模块在执行的时候他就被执行了,而不是因为
你调用这个函数它才执行的,就是利用它的这个特点,保证了只要它默认执行了字典里边就会保存想要使用的数据,就行了
"""
@route("/index.py") # 函数的引用是一坨地址,而不是这个名
def index():
with open("./templates/index.html") as f:
content = f.read()
return content
@route("/center.py")
def center():
with open("./templates/center.html") as f:
return f.read()
# 最最最基本的框架也至少要有这个函数
"""
手动组装key value
URL_FUNC_DICT = {
"/index.py":index,
"/center.py":center
}
"""
# 定义全局变量的时候,尽量使用大写字母或者在变量前加一个G/g,表示全局变量
# python解释器是从上到下执行的,故定义变量要在使用之前
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
"""
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
"""
"""
这里通过if语句判断,web框架需要返回什么内容,要是有n多个页面要打开,那岂不是要n个if判断???!!!
一般超过5,6个就不应该用这个解决方案
这肯定不是通用的解法
通用解法的思路:
以前在调用字典的时候,先定义一个字典,里边有很多值,你调用这个字典的时候,用一个中括号,你写不一样的key值将来的返回值就不一样
以字典中取值的思路来思考这个问题
此处问题的核心就是,不想自己写这么多恶心的if判断,想实现根据你的不同的请求,让它自动去调不同的函数
思路:
用一个字典,字典里边让请求的url(网址)这个资源文件当作key,方法名(函数的引用)当做value值,那么最终
我给你一个key值,就返回一个value,又因为value是一个函数的引用,当然可以括起来直接调用了
这种方法代码量不一定少,但是这个调用过程一定是一种优化
缺点:每次往字典里边写东西依旧比较麻烦,最好找个东西直接让字典里边含有相应的内容
使用装饰器来解决这个问题
思路:
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
try:
# func = URL_FUNC_DICT[file_name] # 不管字典中有多少个值,只要传过来的file_name有与之匹配的key值就可以找到相应的函数的引用
# 此处的key值要是没有,程序可能会挂掉,可以用异常解决,好处是异常具有传递性,不仅可以判断这里key值的异常,还可以处理
# 调用过程中出现的未解决的异常,保证程序不会死
# return func() # 调用函数,因为调用的函数有返回值,所以加上一个return
return URL_FUNC_DICT[file_name]()
except Exception as ret:
return "产生了异常:%s" % str(ret)
# web服务器调用的这里,出现异常会没有body返回回去了,浏览器就挂了,所以找这个return返回的东西作为body
04_实现伪静态
对服务器进行优化:实现伪静态
将.py结尾的文件伪装成.html结尾的文件
静态/动态/伪静态URL的区别与分析
目前开发的网站其实真正意义上都是动态网站,只是URL上有些区别,一般URL分为静态URL、动态URL、伪静态URL,他们的区别是什么?
SEO:搜索引擎优化,是一种方式:利用搜索引擎的规则,提高网站在有关搜索引擎内的排名
静态URL
静态URL类似 域名/news/2012-5-18/110.html 我们一般称为真静态URL,每个网页有真实的物理路径,也就是真实存在服务器里的。
优点是:
网站打开速度快,因为它不用进行运算;另外网址结构比较友好,利于记忆。
缺点是:
最大的缺点是如果是中大型网站,则产生的页面特别多,不好管理。至于有的开发者说占用硬盘空间大,我觉得这个可
以忽略不计,占用不了多少空间的,况且目前硬盘空间都比较大。还有的开发者说会伤硬盘,这点也可以忽略不计。
一句话总结:
静态网站对SEO的影响:静态URL对SEO肯定有加分的影响,因为打开速度快,这个是本质。
动态URL
动态URL类似 域名/NewsMore.asp?id=5 或者 域名/DaiKuan.php?id=17,带有?号的URL,我们一般称为动态网址,每个URL只是一个逻
辑地址,并不是真实物理存在服务器硬盘里的。
优点是:
适合中大型网站,数据存储在数据库内,修改页面很方便,因为是逻辑地址,所以占用硬盘空间要比纯静态网站小。
缺点是:
因为要进行运算,所以打开速度稍慢,不过这个可有忽略不计,目前有服务器缓存技术可以解决速度问题。最大的缺点是URL
结构稍稍复杂,不利于记忆。
一句话总结:
动态URL对SEO的影响:目前百度SE已经能够很好的理解动态URL,所以对SEO没有什么减分的影响(特别复杂的URL结构除外)。
所以你无论选择动态还是静态其实都无所谓,看你选择的程序和需求了。
伪静态URL
伪静态URL类似 域名/course/74.html 这个URL和真静态URL类似。他是通过伪静态规则把动态URL伪装成静态网址。也是逻辑地址,不存在物理地址。
优点是:
URL比较友好,利于记忆。非常适合大中型网站,是个折中方案。
缺点是:
设置麻烦,服务器要支持重写规则,小企业网站或者玩不好的就不要折腾了。另外进行了伪静态网站访问速度并没有变快,因为实质上
它会额外的进行运算解释,反正增加了服务器负担,速度反而变慢,不过现在的服务器都很强大,这种影响也可以忽略不计。还有可能
会造成动态URL和静态URL都被搜索引擎收录,不过可以用robots禁止掉动态地址。
一句话总结:
对SEO的影响:和动态URL一样,对SEO没有什么减分影响。
对服务器进行优化:实现伪静态
将.py结尾的文件伪装成.html结尾的文件
web_server
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application,static_path):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
self.static_path = static_path
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.html结尾,那么就认为请求的是静态资源(css/js/png/jpg等)(.py结尾的在实际中不会见到),直接在服务器中向下打开返回数据,要是是html请求,就进行调用,调用web框架来返回数据
if not file_name.endswith(".html"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open(self.static_path+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
with open("./web_sever_conf") as f:
conf_info = eval(f.read())
# 此时conf_info是一个字典,里面的数据为:
# {
# "static_path":"./static",
# "dynamic_frame_path":"./dynamic_frame"
# }
# 此处的核心操作是:将要配置的文件(即在程序中要用到的文件夹)以字典的形式(由于不是在.py文件里边,实际上是字符串)存储在一个普通文件里,使用的时候转成字典使用,使用字典的key值去对应
# 相应的文件,这样在配置文件的时候就不用改程序了,只需要叫相应的文件写在普通文件的"value"值里边即可
# 类里边的方法要使用主函数的变量值的时候一定要进行传参,即在创建对象的时候把参数传进去
# 传进初始化方法__init__方法中,并在该方法中用self.定义成实例属性,才能由别的方法
# 通过self.的方式调用
sys.path.append(conf_info['dynamic_frame_path'])
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application,conf_info['static_path'])
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
web_frame
URL_FUNC_DICT = dict()
# func_list = list()
def route(url): # route: 路由
def set_func(func):
# func_list.append(func) # 将每一个传进来的函数的引用放进列表里边 直接放在字典里边
# 就相当于URL_FUNC_DICT["/index.py"] = index
URL_FUNC_DICT[url] = func
def call_func(*args,**kwargs):
return func(*args,**kwargs)
return call_func
return set_func
"""
路由:根据你的请求不一样,调用的功能不同,实现路由的核心原因应用到了映射
只要一用装饰器,被装饰的函数的引用就会传进装饰器函数里边,定义一个列表,
将每一个传进装饰器函数的函数的引用放进列表中
得到函数的引用之后,只要再保证怎么对应每个函数的引用即可
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
"""
这个使用装饰器解决问题的思想比较重要,学会怎么用来解决问题,因为装饰器是这个模块在执行的时候他就被执行了,而不是因为
你调用这个函数它才执行的,就是利用它的这个特点,保证了只要它默认执行了字典里边就会保存想要使用的数据,就行了
"""
@route("/index.html") # 函数的引用是一坨地址,而不是这个名
def index():
with open("./templates/index.html") as f:
content = f.read()
return content
@route("/center.html")
def center():
with open("./templates/center.html") as f:
return f.read()
# 最最最基本的框架也至少要有这个函数
"""
手动组装key value
URL_FUNC_DICT = {
"/index.py":index,
"/center.py":center
}
"""
# 定义全局变量的时候,尽量使用大写字母或者在变量前加一个G/g,表示全局变量
# python解释器是从上到下执行的,故定义变量要在使用之前
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
"""
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
"""
"""
这里通过if语句判断,web框架需要返回什么内容,要是有n多个页面要打开,那岂不是要n个if判断???!!!
一般超过5,6个就不应该用这个解决方案
这肯定不是通用的解法
通用解法的思路:
以前在调用字典的时候,先定义一个字典,里边有很多值,你调用这个字典的时候,用一个中括号,你写不一样的key值将来的返回值就不一样
以字典中取值的思路来思考这个问题
此处问题的核心就是,不想自己写这么多恶心的if判断,想实现根据你的不同的请求,让它自动去调不同的函数
思路:
用一个字典,字典里边让请求的url(网址)这个资源文件当作key,方法名(函数的引用)当做value值,那么最终
我给你一个key值,就返回一个value,又因为value是一个函数的引用,当然可以括起来直接调用了
这种方法代码量不一定少,但是这个调用过程一定是一种优化
缺点:每次往字典里边写东西依旧比较麻烦,最好找个东西直接让字典里边含有相应的内容
使用装饰器来解决这个问题
思路:
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
try:
# func = URL_FUNC_DICT[file_name] # 不管字典中有多少个值,只要传过来的file_name有与之匹配的key值就可以找到相应的函数的引用
# 此处的key值要是没有,程序可能会挂掉,可以用异常解决,好处是异常具有传递性,不仅可以判断这里key值的异常,还可以处理
# 调用过程中出现的未解决的异常,保证程序不会死
# return func() # 调用函数,因为调用的函数有返回值,所以加上一个return
return URL_FUNC_DICT[file_name]()
except Exception as ret:
return "产生了异常:%s" % str(ret)
# web服务器调用的这里,出现异常会没有body返回回去了,浏览器就挂了,所以找这个return返回的东西作为body
05_从数据库查询数据
web_server
import socket
import re
import multiprocessing
import time
# import dynamic.mini_frame
import sys
class WSGIServer(object):
def __init__(self, port, app, static_path):
# 1. 创建套接字
self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2. 绑定
self.tcp_server_socket.bind(("", port))
# 3. 变为监听套接字
self.tcp_server_socket.listen(128)
self.application = app
self.static_path = static_path
def service_client(self, new_socket):
"""为这个客户端返回数据"""
# 1. 接收浏览器发送过来的请求 ,即http请求
# GET / HTTP/1.1
# .....
request = new_socket.recv(1024).decode("utf-8")
# print(">>>"*50)
# print(request)
request_lines = request.splitlines()
print("")
print(">"*20)
print(request_lines)
# GET /index.html HTTP/1.1
# get post put del
file_name = ""
ret = re.match(r"[^/]+(/[^ ]*)", request_lines[0])
if ret:
file_name = ret.group(1)
# print("*"*50, file_name)
if file_name == "/":
file_name = "/index.html"
# 2. 返回http格式的数据,给浏览器
# 2.1 如果请求的资源不是以.html结尾,那么就认为是静态资源(css/js/png,jpg等)
if not file_name.endswith(".html"):
try:
f = open(self.static_path + file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "------file not found-----"
new_socket.send(response.encode("utf-8"))
else:
html_content = f.read()
f.close()
# 2.1 准备发送给浏览器的数据---header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2 准备发送给浏览器的数据---boy
# response += "hahahhah"
# 将response header发送给浏览器
new_socket.send(response.encode("utf-8"))
# 将response ic.mini_frame.applicationbody发送给浏览器
new_socket.send(html_content)
else:
# 2.2 如果是以.html结尾,那么就认为是动态资源的请求
env = dict() # 这个字典中存放的是web服务器要传递给 web框架的数据信息
env['PATH_INFO'] = file_name
# {"PATH_INFO": "/index.py"}
# body = dynamic.mini_frame.application(env, self.set_response_header)
body = self.application(env, self.set_response_header)
header = "HTTP/1.1 %s\r\n" % self.status
for temp in self.headers:
header += "%s:%s\r\n" % (temp[0], temp[1])
header += "\r\n"
response = header+body
# 发送response给浏览器
new_socket.send(response.encode("utf-8"))
# 关闭套接
new_socket.close()
def set_response_header(self, status, headers):
self.status = status
self.headers = [("server", "mini_web v8.8")]
self.headers += headers
def run_forever(self):
"""用来完成整体的控制"""
while True:
# 4. 等待新客户端的链接
new_socket, client_addr = self.tcp_server_socket.accept()
# 5. 为这个客户端服务
p = multiprocessing.Process(target=self.service_client, args=(new_socket,))
p.start()
new_socket.close()
# 关闭监听套接字
self.tcp_server_socket.close()
def main():
"""控制整体,创建一个web 服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 7890
frame_app_name = sys.argv[2] # mini_frame:application
except Exception as ret:
print("端口输入错误。。。。。")
return
else:
print("请按照以下方式运行:")
print("python3 xxxx.py 7890 mini_frame:application")
return
# mini_frame:application
ret = re.match(r"([^:]+):(.*)", frame_app_name)
if ret:
frame_name = ret.group(1) # mini_frame
app_name = ret.group(2) # application
else:
print("请按照以下方式运行:")
print("python3 xxxx.py 7890 mini_frame:application")
return
with open("./web_server.conf") as f:
conf_info = eval(f.read())
# 此时 conf_info是一个字典里面的数据为:
# {
# "static_path":"./static",
# "dynamic_path":"./dynamic"
# }
sys.path.append(conf_info['dynamic_path'])
# import frame_name --->找frame_name.py
frame = __import__(frame_name) # 返回值标记这 导入的这个模板
app = getattr(frame, app_name) # 此时app就指向了 dynamic/mini_frame模块中的application这个函数
# print(app)
wsgi_server = WSGIServer(port, app, conf_info['static_path'])
wsgi_server.run_forever()
if __name__ == "__main__":
main()
web_frame
import re
from pymysql import connect
"""
URL_FUNC_DICT = {
"/index.html": index,
"/center.html": center
}
"""
URL_FUNC_DICT = dict()
def route(url):
def set_func(func):
# URL_FUNC_DICT["/index.py"] = index
URL_FUNC_DICT[url] = func
def call_func(*args, **kwargs):
return func(*args, **kwargs)
return call_func
return set_func
@route("/index.html")
def index():
with open("./templates/index.html") as f:
content = f.read()
# my_stock_info = "哈哈哈哈 这是你的本月名称....."
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select * from info;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
content = re.sub(r"\{%content%\}", str(stock_infos), content)
return content
@route("/center.html")
def center():
with open("./templates/center.html") as f:
content = f.read()
my_stock_info = "这里是从mysql查询出来的数据。。。"
content = re.sub(r"\{%content%\}", my_stock_info, content)
return content
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
file_name = env['PATH_INFO']
# file_name = "/index.py"
"""
if file_name == "/index.py":
return index()
elif file_name == "/center.py":
return center()
else:
return 'Hello World! 我爱你中国....'
"""
try:
# func = URL_FUNC_DICT[file_name]
# return func()
return URL_FUNC_DICT[file_name]()
except Exception as ret:
return "产生了异常:%s" % str(ret)
05_mini_web框架添加正则及log日志功能
01_让路由支持正则
web_server
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application,static_path):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
self.static_path = static_path
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.html结尾,那么就认为请求的是静态资源(css/js/png/jpg等)(.py结尾的在实际中不会见到),直接在服务器中向下打开返回数据,要是是html请求,就进行调用,调用web框架来返回数据
if not file_name.endswith(".html"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open(self.static_path+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
with open("./web_sever_conf") as f:
conf_info = eval(f.read())
# 此时conf_info是一个字典,里面的数据为:
# {
# "static_path":"./static",
# "dynamic_frame_path":"./dynamic_frame"
# }
# 此处的核心操作是:将要配置的文件(即在程序中要用到的文件夹)以字典的形式(由于不是在.py文件里边,实际上是字符串)存储在一个普通文件里,使用的时候转成字典使用,使用字典的key值去对应
# 相应的文件,这样在配置文件的时候就不用改程序了,只需要叫相应的文件写在普通文件的"value"值里边即可
# 类里边的方法要使用主函数的变量值的时候一定要进行传参,即在创建对象的时候把参数传进去
# 传进初始化方法__init__方法中,并在该方法中用self.定义成实例属性,才能由别的方法
# 通过self.的方式调用
sys.path.append(conf_info['dynamic_frame_path'])
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application,conf_info['static_path'])
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
web_frame
import re
from pymysql import connect
"""
到目前为止,这个web服务器已经基本上不需要动了,实在有需求再改.同样,现在的web框架也基本上定型了
web服务器首先要调用的函数application()已经基本不变了,最开始的装饰器的过程,及字典的部分也基
本不变了.
再有功能变动的话,你唯独需要在这个web框架里边写什么呢?
写一个函数用装饰器装一下,写一个函数用装饰器装一下,至于怎么调用的,谁来调用的,以及如何返回数据的
统统都不管,只需要写一个函数用装饰器装一下即可.
实际开发就是这个样子,如果把框架给了你,要加一个登录页面,即只要写一个log函数,用装饰器装一下子,
访问log.html的时候调用我的这个函数即可(字典里的key/value)
总是用装饰器装一下是因为要通过这个过程往字典中添加key/value
"""
URL_FUNC_DICT = dict()
# func_list = list()
def route(url): # route: 路由
def set_func(func):
# func_list.append(func) # 将每一个传进来的函数的引用放进列表里边 直接放在字典里边
# 就相当于URL_FUNC_DICT["/index.py"] = index
URL_FUNC_DICT[url] = func
def call_func(*args,**kwargs):
return func(*args,**kwargs)
return call_func
return set_func
"""
路由:根据你的请求不一样,调用的功能不同,实现路由的核心原因应用到了映射
只要一用装饰器,被装饰的函数的引用就会传进装饰器函数里边,定义一个列表,
将每一个传进装饰器函数的函数的引用放进列表中
得到函数的引用之后,只要再保证怎么对应每个函数的引用即可
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
"""
这个使用装饰器解决问题的思想比较重要,学会怎么用来解决问题,因为装饰器是这个模块在执行的时候他就被执行了,而不是因为
你调用这个函数它才执行的,就是利用它的这个特点,保证了只要它默认执行了字典里边就会保存想要使用的数据,就行了
"""
@route("/index.html") # 函数的引用是一坨地址,而不是这个名
def index():
with open("./templates/index.html") as f:
content = f.read()
# my_stock_info = "哈哈哈,这是你本月的名称...."
# content = re.sub(r"\{%content%\}",my_stock_info,content)
"""
在这里只要把my_stock_info的内容换成数据库的内容,那么一切问题就迎刃而解
做法:
1.在python中操作数据库的几个固定的过程:
连接数据库;获取游标;通过execute获取sql语句(python执行sql语句是默认开启事务的),
若执行的是查询语句,不用使用commit提交,若是增删改则需要使用commit提交(相当于最后事务确认)
"""
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
# 上边i这两句不要去记忆,用的时候直接拿过来使用
cs.execute("select * from info;") # 数据少,可以全部查出来.要是数据特别多的话需要使用limit来分页
stock_infos = cs.fetchall()
cs.close()
conn.close()
# 网页格式实现:行列格式
"""
整体思路:
当浏览器请求的时候,将请求发给来web服务器,web服务器去调用框架
,框架基本上做两件事情:1.从模版的路径里边找到它对应的模版;2.从数据库里边查出数据
将数据和模版进行一个替换的组装合并,最终合并成一个完美的字符串,把它返回给web服务器
web服务器返回给浏览器
"""
tr_template = """<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<input type="button" value="添加" id="toAdd" name="toAdd" systemidvaule="000007">
</td>
</tr>
"""
# 将每一个元组里边的元素替换标签里边的%s
# 如何实现多个全部替换,如何知道有多少个数据要进行格式设置?
# 从数据库里边查出来的数据是一个元组里边套着n个元组,最外边的这个元组决定了有多少行,里边的每一个元组是一行,
# 内部的小元组里边的元素个数决定了有多少列
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6],line_info[7])
# 上边这一行的写法对应的就是"上边标签里边的%s" % (....)
# 有多少行就加多少个模板,即多少个tr标签
content = re.sub(r"\{%content%\}", html, content)
return content
@route("/center.html")
def center():
with open("./templates/center.html") as f:
content = f.read()
# my_stock_info = "这里是从mysql查询出来的数据hahahaha"
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
# 上边i这两句不要去记忆,用的时候直接拿过来使用
cs.execute("select i.code,i.short,i.chg,i.turnover,i.price,i.highs,f.note_info from info as i inner join focus as f on i.id=f.info_id;")
# 从数据库获取数据的语句实现
#(实际开发过程中,先验证这个选取内容的sql语句能否正确的在mysql里边获取想要的数据,要是可以直接拿过来)
# 数据少,可以全部查出来.要是数据特别多的话需要使用limit来分页
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """
<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<a type="button" class="btn btn-default btn-xs" href="/update/300268.html"> <span class="glyphicon glyphicon-star" aria-hidden="true"></span> 修改 </a>
</td>
<td>
<input type="button" value="删除" id="toDel" name="toDel" systemidvaule="300268">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6])
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
# 最最最基本的框架也至少要有这个函数
"""
手动组装key value
URL_FUNC_DICT = {
"/index.py":index,
"/center.py":center
}
"""
# 定义全局变量的时候,尽量使用大写字母或者在变量前加一个G/g,表示全局变量
# python解释器是从上到下执行的,故定义变量要在使用之前
"""
给路由添加正则表达式的原因:在实际开发时,url中往往会有很多的参数,例如/add/000007.html中的000007就是参数,
若果没有正则的话,那么就需要编写n次@route来进行添加url对应的函数(理解为有一个不同的参数就要添加一次)
到字典中,此时的键值对有n个,浪费空间.
而要是采用了正则的话,那么只要编写一次@route就可以完成多个url.例如/add/000007.html /add/000036.html等对应同一个函数(?),
此时字典中的键值对的个数就会少很多
"""
@route("/add/\d+\.html")
# 正则中的add,只是为了增强可读性,具体叫什么无所谓,add保证了请求的是同一个函数或者是同一种处理方式,后边的值不一样,说明后面的值表示参数
# 下方的函数只返回一个Ok一点用也没有
def add_focus():
return "add ok....."
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
"""
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
"""
"""
这里通过if语句判断,web框架需要返回什么内容,要是有n多个页面要打开,那岂不是要n个if判断???!!!
一般超过5,6个就不应该用这个解决方案
这肯定不是通用的解法
通用解法的思路:
以前在调用字典的时候,先定义一个字典,里边有很多值,你调用这个字典的时候,用一个中括号,你写不一样的key值将来的返回值就不一样
以字典中取值的思路来思考这个问题
此处问题的核心就是,不想自己写这么多恶心的if判断,想实现根据你的不同的请求,让它自动去调不同的函数
思路:
用一个字典,字典里边让请求的url(网址)这个资源文件当作key,方法名(函数的引用)当做value值,那么最终
我给你一个key值,就返回一个value,又因为value是一个函数的引用,当然可以括起来直接调用了
这种方法代码量不一定少,但是这个调用过程一定是一种优化
缺点:每次往字典里边写东西依旧比较麻烦,最好找个东西直接让字典里边含有相应的内容
使用装饰器来解决这个问题
思路:
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
try:
# func = URL_FUNC_DICT[file_name] # 不管字典中有多少个值,只要传过来的file_name有与之匹配的key值就可以找到相应的函数的引用
# 此处的key值要是没有,程序可能会挂掉,可以用异常解决,好处是异常具有传递性,不仅可以判断这里key值的异常,还可以处理
# 调用过程中出现的未解决的异常,保证程序不会死
# return func() # 调用函数,因为调用的函数有返回值,所以加上一个return
for url, func in URL_FUNC_DICT.items():
# {
# r"/index.html":index,
# r"/center.html":center,
# r"/add/\d+\.html":add_focus
# }
ret = re.match(url, file_name)
if ret:
return func()
else:
return "请求的url(%s)没有对应的函数...." % file_name
except Exception as ret:
return "产生了异常:%s" % str(ret)
# web服务器调用的这里,出现异常会没有body返回回去了,浏览器就挂了,所以找这个return返回的东西作为body
02_添加关注
web_server
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application,static_path):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
self.static_path = static_path
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.html结尾,那么就认为请求的是静态资源(css/js/png/jpg等)(.py结尾的在实际中不会见到),直接在服务器中向下打开返回数据,要是是html请求,就进行调用,调用web框架来返回数据
if not file_name.endswith(".html"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open(self.static_path+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
with open("./web_server.conf") as f:
conf_info = eval(f.read())
# 此时conf_info是一个字典,里面的数据为:
# {
# "static_path":"./static",
# "dynamic_frame_path":"./dynamic_frame"
# }
# 此处的核心操作是:将要配置的文件(即在程序中要用到的文件夹)以字典的形式(由于不是在.py文件里边,实际上是字符串)存储在一个普通文件里,使用的时候转成字典使用,使用字典的key值去对应
# 相应的文件,这样在配置文件的时候就不用改程序了,只需要叫相应的文件写在普通文件的"value"值里边即可
# 类里边的方法要使用主函数的变量值的时候一定要进行传参,即在创建对象的时候把参数传进去
# 传进初始化方法__init__方法中,并在该方法中用self.定义成实例属性,才能由别的方法
# 通过self.的方式调用
sys.path.append(conf_info['dynamic_frame_path'])
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application,conf_info['static_path'])
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
web_frame
import re
from pymysql import connect
"""
到目前为止,这个web服务器已经基本上不需要动了,实在有需求再改.同样,现在的web框架也基本上定型了
web服务器首先要调用的函数application()已经基本不变了,最开始的装饰器的过程,及字典的部分也基
本不变了.
再有功能变动的话,你唯独需要在这个web框架里边写什么呢?
写一个函数用装饰器装一下,写一个函数用装饰器装一下,至于怎么调用的,谁来调用的,以及如何返回数据的
统统都不管,只需要写一个函数用装饰器装一下即可.
实际开发就是这个样子,如果把框架给了你,要加一个登录页面,即只要写一个log函数,用装饰器装一下子,
访问log.html的时候调用我的这个函数即可(字典里的key/value)
总是用装饰器装一下是因为要通过这个过程往字典中添加key/value
"""
URL_FUNC_DICT = dict()
# func_list = list()
def route(url): # route: 路由
def set_func(func):
# func_list.append(func) # 将每一个传进来的函数的引用放进列表里边 直接放在字典里边
# 就相当于URL_FUNC_DICT["/index.py"] = index
URL_FUNC_DICT[url] = func
def call_func(*args,**kwargs):
return func(*args,**kwargs)
return call_func
return set_func
"""
路由:根据你的请求不一样,调用的功能不同,实现路由的核心原因应用到了映射
只要一用装饰器,被装饰的函数的引用就会传进装饰器函数里边,定义一个列表,
将每一个传进装饰器函数的函数的引用放进列表中
得到函数的引用之后,只要再保证怎么对应每个函数的引用即可
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
"""
这个使用装饰器解决问题的思想比较重要,学会怎么用来解决问题,因为装饰器是这个模块在执行的时候他就被执行了,而不是因为
你调用这个函数它才执行的,就是利用它的这个特点,保证了只要它默认执行了字典里边就会保存想要使用的数据,就行了
"""
@route(r"/index.html")
def index(ret):
with open("./templates/index.html") as f:
content = f.read()
# my_stock_info = "哈哈哈哈 这是你的本月名称....."
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select * from info;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<input type="button" value="添加" id="toAdd" name="toAdd" systemidvaule="%s">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6],line_info[7], line_info[1])
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
@route(r"/center.html")
def center(ret):
with open("./templates/center.html") as f:
content = f.read()
# my_stock_info = "这里是从mysql查询出来的数据。。。"
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select i.code,i.short,i.chg,i.turnover,i.price,i.highs,f.note_info from info as i inner join focus as f on i.id=f.info_id;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """
<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<a type="button" class="btn btn-default btn-xs" href="/update/300268.html"> <span class="glyphicon glyphicon-star" aria-hidden="true"></span> 修改 </a>
</td>
<td>
<input type="button" value="删除" id="toDel" name="toDel" systemidvaule="300268">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6])
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
# 给路由添加正则表达式的原因:在实际开发时,url中往往会带有很多参数,例如/add/000007.html中000007就是参数,
# 如果没有正则的话,那么就需要编写N次@route来进行添加 url对应的函数 到字典中,此时字典中的键值对有N个,浪费空间
# 而采用了正则的话,那么只要编写1次@route就可以完成多个 url例如/add/00007.html /add/000036.html等对应同一个函数,此时字典中的键值对个数会少很多
@route(r"/add/(\d+)\.html")
# 正则中的add,只是为了增强可读性,具体叫什么无所谓,add保证了请求的是同一个函数或者是同一种处理方式,后边的值不一样,说明后面的值表示参数
# 下方的函数只返回一个Ok一点用也没有
def add_focus(ret):
# 怎么取\d+的值呢?
# 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
# 1.获取股票代码
stock_code = ret.group(1)
# 2.判断一下是否有这个股票代码
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
cs = conn.cursor()
sql = """select * from info where code=%s;""" # 注意结尾要加分号";",此处要防止sql注入
cs.execute(sql,(stock_code,)) # ?
# 如果要是没有这个股票代码,那么就认为是非法请求
if not cs.fetchone():
cs.close()
conn.close()
return "没有这支股票,大哥,我们是创业公司,请手下留情"
# 3.判断一下是否已经关注过
sql = """select * from info as i inner join focus as f on i.id = f.info_id where i.code = %s;"""
# 不要在程序里边测试sql语句,在mysql里边测试好了再拿过来
cs.execute(sql,(stock_code,))
# 如果查出来了就表示已经关注过了
if cs.fetchone():
cs.close()
conn.close()
return "已经关注过了,请勿重复关注"
# 4.添加关注
sql = """insert into focus (info_id) select id from info where code=%s;"""
cs.execute(sql,(stock_code,))
conn.commit() # 添加要提交
cs.close()
conn.close()
return "关注成功....."
"""
为什么要用return返回值?
当你在实际开发的时候因为浏览器先要把请求给服务器,服务器再给框架,框架再处理,处理完了再给服务器,服务器再给浏览器,这个过程
十分长,往往浏览器看不见结果,怎么才能保证我请求的这个过程再回来整个一定是个通的,是可以运行的呢?
思想:
请求一个url,不要管里边返回什么,先给我一个字符串,什么都行,先给我打回来,要是能打得回来,就说明从浏览器发出请求到服务器返回
这个过程整个都是通的,如果确定整个过程是通的只需要根据返回的信息开会一步步的调试即可
"""
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
"""
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
"""
"""
这里通过if语句判断,web框架需要返回什么内容,要是有n多个页面要打开,那岂不是要n个if判断???!!!
一般超过5,6个就不应该用这个解决方案
这肯定不是通用的解法
通用解法的思路:
以前在调用字典的时候,先定义一个字典,里边有很多值,你调用这个字典的时候,用一个中括号,你写不一样的key值将来的返回值就不一样
以字典中取值的思路来思考这个问题
此处问题的核心就是,不想自己写这么多恶心的if判断,想实现根据你的不同的请求,让它自动去调不同的函数
思路:
用一个字典,字典里边让请求的url(网址)这个资源文件当作key,方法名(函数的引用)当做value值,那么最终
我给你一个key值,就返回一个value,又因为value是一个函数的引用,当然可以括起来直接调用了
这种方法代码量不一定少,但是这个调用过程一定是一种优化
缺点:每次往字典里边写东西依旧比较麻烦,最好找个东西直接让字典里边含有相应的内容
使用装饰器来解决这个问题
思路:
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
try:
# func = URL_FUNC_DICT[file_name] # 不管字典中有多少个值,只要传过来的file_name有与之匹配的key值就可以找到相应的函数的引用
# 此处的key值要是没有,程序可能会挂掉,可以用异常解决,好处是异常具有传递性,不仅可以判断这里key值的异常,还可以处理
# 调用过程中出现的未解决的异常,保证程序不会死
# return func() # 调用函数,因为调用的函数有返回值,所以加上一个return
for url, func in URL_FUNC_DICT.items():
# {
# r"/index.html":index,
# r"/center.html":center,
# r"/add/\d+\.html":add_focus
# }
ret = re.match(url, file_name) # 正则匹配的结果存储在ret这个对象里边
if ret:
return func(ret) # 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
else:
return "请求的url(%s)没有对应的函数...." % file_name
except Exception as ret:
return "产生了异常:%s" % str(ret)
# web服务器调用的这里,出现异常会没有body返回回去了,浏览器就挂了,所以找这个return返回的东西作为body
03_取消关注
web_server
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application,static_path):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
self.static_path = static_path
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.html结尾,那么就认为请求的是静态资源(css/js/png/jpg等)(.py结尾的在实际中不会见到),直接在服务器中向下打开返回数据,要是是html请求,就进行调用,调用web框架来返回数据
if not file_name.endswith(".html"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open(self.static_path+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
with open("./web_server.conf") as f:
conf_info = eval(f.read())
# 此时conf_info是一个字典,里面的数据为:
# {
# "static_path":"./static",
# "dynamic_frame_path":"./dynamic_frame"
# }
# 此处的核心操作是:将要配置的文件(即在程序中要用到的文件夹)以字典的形式(由于不是在.py文件里边,实际上是字符串)存储在一个普通文件里,使用的时候转成字典使用,使用字典的key值去对应
# 相应的文件,这样在配置文件的时候就不用改程序了,只需要叫相应的文件写在普通文件的"value"值里边即可
# 类里边的方法要使用主函数的变量值的时候一定要进行传参,即在创建对象的时候把参数传进去
# 传进初始化方法__init__方法中,并在该方法中用self.定义成实例属性,才能由别的方法
# 通过self.的方式调用
sys.path.append(conf_info['dynamic_frame_path'])
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application,conf_info['static_path'])
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
web_frame
import re
from pymysql import connect
"""
到目前为止,这个web服务器已经基本上不需要动了,实在有需求再改.同样,现在的web框架也基本上定型了
web服务器首先要调用的函数application()已经基本不变了,最开始的装饰器的过程,及字典的部分也基
本不变了.
再有功能变动的话,你唯独需要在这个web框架里边写什么呢?
写一个函数用装饰器装一下,写一个函数用装饰器装一下,至于怎么调用的,谁来调用的,以及如何返回数据的
统统都不管,只需要写一个函数用装饰器装一下即可.
实际开发就是这个样子,如果把框架给了你,要加一个登录页面,即只要写一个log函数,用装饰器装一下子,
访问log.html的时候调用我的这个函数即可(字典里的key/value)
总是用装饰器装一下是因为要通过这个过程往字典中添加key/value
"""
URL_FUNC_DICT = dict()
# func_list = list()
def route(url): # route: 路由
def set_func(func):
# func_list.append(func) # 将每一个传进来的函数的引用放进列表里边 直接放在字典里边
# 就相当于URL_FUNC_DICT["/index.py"] = index
URL_FUNC_DICT[url] = func
def call_func(*args,**kwargs):
return func(*args,**kwargs)
return call_func
return set_func
"""
路由:根据你的请求不一样,调用的功能不同,实现路由的核心原因应用到了映射
只要一用装饰器,被装饰的函数的引用就会传进装饰器函数里边,定义一个列表,
将每一个传进装饰器函数的函数的引用放进列表中
得到函数的引用之后,只要再保证怎么对应每个函数的引用即可
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
"""
这个使用装饰器解决问题的思想比较重要,学会怎么用来解决问题,因为装饰器是这个模块在执行的时候他就被执行了,而不是因为
你调用这个函数它才执行的,就是利用它的这个特点,保证了只要它默认执行了字典里边就会保存想要使用的数据,就行了
"""
@route(r"/index.html")
def index(ret):
with open("./templates/index.html") as f:
content = f.read()
# my_stock_info = "哈哈哈哈 这是你的本月名称....."
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select * from info;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<input type="button" value="添加" id="toAdd" name="toAdd" systemidvaule="%s">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6],line_info[7], line_info[1])
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
@route(r"/center.html")
def center(ret):
with open("./templates/center.html") as f:
content = f.read()
# my_stock_info = "这里是从mysql查询出来的数据。。。"
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select i.code,i.short,i.chg,i.turnover,i.price,i.highs,f.note_info from info as i inner join focus as f on i.id=f.info_id;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """
<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<a type="button" class="btn btn-default btn-xs" href="/update/%s.html"> <span class="glyphicon glyphicon-star" aria-hidden="true"></span> 修改 </a>
</td>
<td>
<input type="button" value="删除" id="toDel" name="toDel" systemidvaule="%s">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6],line_info[0],line_info[0])
# 括号里的数据的个数,与上边%s的个数相同,因为第一个和最后一个数据相同,所以相同
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
# 给路由添加正则表达式的原因:在实际开发时,url中往往会带有很多参数,例如/add/000007.html中000007就是参数,
# 如果没有正则的话,那么就需要编写N次@route来进行添加 url对应的函数 到字典中,此时字典中的键值对有N个,浪费空间
# 而采用了正则的话,那么只要编写1次@route就可以完成多个 url例如/add/00007.html /add/000036.html等对应同一个函数,此时字典中的键值对个数会少很多
@route(r"/add/(\d+)\.html")
# 正则中的add,只是为了增强可读性,具体叫什么无所谓,add保证了请求的是同一个函数或者是同一种处理方式,后边的值不一样,说明后面的值表示参数
# 下方的函数只返回一个Ok一点用也没有
def add_focus(ret):
# 怎么取\d+的值呢?
# 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
# 1.获取股票代码
stock_code = ret.group(1)
# 2.判断一下是否有这个股票代码
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
cs = conn.cursor()
sql = """select * from info where code=%s;""" # 注意结尾要加分号";",此处要防止sql注入
cs.execute(sql,(stock_code,)) # ?
# 如果要是没有这个股票代码,那么就认为是非法请求
if not cs.fetchone():
cs.close()
conn.close()
return "没有这支股票,大哥,我们是创业公司,请手下留情"
# 3.判断一下是否已经关注过
sql = """select * from info as i inner join focus as f on i.id=f.info_id where i.code=%s;"""
# 不要在程序里边测试sql语句,在mysql里边测试好了再拿过来
cs.execute(sql,(stock_code,))
# 如果查出来了那么就表示已经关注过
if cs.fetchone():
cs.close()
conn.close()
return "已经关注了,请勿重复关注.."
# 4.添加关注
sql = """insert into focus (info_id) select id from info where code=%s;"""
cs.execute(sql,(stock_code,))
conn.commit() # 添加要提交
cs.close()
conn.close()
return "关注成功....."
"""
为什么要用return返回值?
当你在实际开发的时候因为浏览器先要把请求给服务器,服务器再给框架,框架再处理,处理完了再给服务器,服务器再给浏览器,这个过程
十分长,往往浏览器看不见结果,怎么才能保证我请求的这个过程再回来整个一定是个通的,是可以运行的呢?
思想:
请求一个url,不要管里边返回什么,先给我一个字符串,什么都行,先给我打回来,要是能打得回来,就说明从浏览器发出请求到服务器返回
这个过程整个都是通的,如果确定整个过程是通的只需要根据返回的信息开会一步步的调试即可
"""
@route(r"/del/(\d+)\.html")
# 正则中的add,只是为了增强可读性,具体叫什么无所谓,add保证了请求的是同一个函数或者是同一种处理方式,后边的值不一样,说明后面的值表示参数
# 下方的函数只返回一个Ok一点用也没有
def del_focus(ret):
# 怎么取\d+的值呢?
# 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
# 1.获取股票代码
stock_code = ret.group(1)
# 2.判断一下是否有这个股票代码
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
cs = conn.cursor()
sql = """select * from info where code=%s;""" # 注意结尾要加分号";",此处要防止sql注入
cs.execute(sql,(stock_code,)) # ?
# 如果要是没有这个股票代码,那么就认为是非法请求
if not cs.fetchone():
cs.close()
conn.close()
return "没有这支股票,大哥,我们是创业公司,请手下留情"
# 3.判断一下是否已经关注过,关注了才能删,没关你删个毛线
sql = """select * from info as i inner join focus as f on i.id = f.info_id where i.code = %s;"""
# 不要在程序里边测试sql语句,在mysql里边测试好了再拿过来
cs.execute(sql,(stock_code,))
# 如果没有关注过,那么表示非法的请求
if not cs.fetchone():
cs.close()
conn.close()
return "%s之前未曾关注,无法取消" % stock_code
# 4.取消关注
# sql = """insert into focus (info_id) select id from info where code=%s;"""
sql = """delete from focus where info_id = (select id from info where code=%s);"""
cs.execute(sql,(stock_code,))
conn.commit() # 添加要提交
cs.close()
conn.close()
return "取消关注成功....."
"""
出现问题的时候,要学会去猜问题出现在哪里,根据表现形式去猜
流程是否有问题(流程没有问题)
根据浏览器返回的现象(思考问题出在哪里?"之前未关注"是查数据没有查出来,判断是否关注过的时候将判断的数据输出来,看看有什么问题)
数据没有查出来的原因:sql语句是否有什么问题(到mysql里边去测试sql语句是否正确),给sql语句传的参数对吗(将传的参数输出,看是否正确)
"""
"""
为什么要用return返回值?
当你在实际开发的时候因为浏览器先要把请求给服务器,服务器再给框架,框架再处理,处理完了再给服务器,服务器再给浏览器,这个过程
十分长,往往浏览器看不见结果,怎么才能保证我请求的这个过程再回来整个一定是个通的,是可以运行的呢?
思想:
请求一个url,不要管里边返回什么,先给我一个字符串,什么都行,先给我打回来,要是能打得回来,就说明从浏览器发出请求到服务器返回
这个过程整个都是通的,如果确定整个过程是通的只需要根据返回的信息开会一步步的调试即可
"""
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
"""
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
"""
"""
这里通过if语句判断,web框架需要返回什么内容,要是有n多个页面要打开,那岂不是要n个if判断???!!!
一般超过5,6个就不应该用这个解决方案
这肯定不是通用的解法
通用解法的思路:
以前在调用字典的时候,先定义一个字典,里边有很多值,你调用这个字典的时候,用一个中括号,你写不一样的key值将来的返回值就不一样
以字典中取值的思路来思考这个问题
此处问题的核心就是,不想自己写这么多恶心的if判断,想实现根据你的不同的请求,让它自动去调不同的函数
思路:
用一个字典,字典里边让请求的url(网址)这个资源文件当作key,方法名(函数的引用)当做value值,那么最终
我给你一个key值,就返回一个value,又因为value是一个函数的引用,当然可以括起来直接调用了
这种方法代码量不一定少,但是这个调用过程一定是一种优化
缺点:每次往字典里边写东西依旧比较麻烦,最好找个东西直接让字典里边含有相应的内容
使用装饰器来解决这个问题
思路:
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
try:
# func = URL_FUNC_DICT[file_name] # 不管字典中有多少个值,只要传过来的file_name有与之匹配的key值就可以找到相应的函数的引用
# 此处的key值要是没有,程序可能会挂掉,可以用异常解决,好处是异常具有传递性,不仅可以判断这里key值的异常,还可以处理
# 调用过程中出现的未解决的异常,保证程序不会死
# return func() # 调用函数,因为调用的函数有返回值,所以加上一个return
for url, func in URL_FUNC_DICT.items():
# {
# r"/index.html":index,
# r"/center.html":center,
# r"/add/\d+\.html":add_focus
# }
ret = re.match(url, file_name) # 正则匹配的结果存储在ret这个对象里边
if ret:
return func(ret) # 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
else:
return "请求的url(%s)没有对应的函数...." % file_name
except Exception as ret:
return "产生了异常:%s" % str(ret)
# web服务器调用的这里,出现异常会没有body返回回去了,浏览器就挂了,所以找这个return返回的东西作为body
04_修改股票备注信息
web_server
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application,static_path):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
self.static_path = static_path
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.html结尾,那么就认为请求的是静态资源(css/js/png/jpg等)(.py结尾的在实际中不会见到),直接在服务器中向下打开返回数据,要是是html请求,就进行调用,调用web框架来返回数据
if not file_name.endswith(".html"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open(self.static_path+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
with open("./web_server.conf") as f:
conf_info = eval(f.read())
# 此时conf_info是一个字典,里面的数据为:
# {
# "static_path":"./static",
# "dynamic_frame_path":"./dynamic_frame"
# }
# 此处的核心操作是:将要配置的文件(即在程序中要用到的文件夹)以字典的形式(由于不是在.py文件里边,实际上是字符串)存储在一个普通文件里,使用的时候转成字典使用,使用字典的key值去对应
# 相应的文件,这样在配置文件的时候就不用改程序了,只需要叫相应的文件写在普通文件的"value"值里边即可
# 类里边的方法要使用主函数的变量值的时候一定要进行传参,即在创建对象的时候把参数传进去
# 传进初始化方法__init__方法中,并在该方法中用self.定义成实例属性,才能由别的方法
# 通过self.的方式调用
sys.path.append(conf_info['dynamic_frame_path'])
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application,conf_info['static_path'])
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
web_frame
import re
from pymysql import connect
"""
到目前为止,这个web服务器已经基本上不需要动了,实在有需求再改.同样,现在的web框架也基本上定型了
web服务器首先要调用的函数application()已经基本不变了,最开始的装饰器的过程,及字典的部分也基
本不变了.
再有功能变动的话,你唯独需要在这个web框架里边写什么呢?
写一个函数用装饰器装一下,写一个函数用装饰器装一下,至于怎么调用的,谁来调用的,以及如何返回数据的
统统都不管,只需要写一个函数用装饰器装一下即可.
实际开发就是这个样子,如果把框架给了你,要加一个登录页面,即只要写一个log函数,用装饰器装一下子,
访问log.html的时候调用我的这个函数即可(字典里的key/value)
总是用装饰器装一下是因为要通过这个过程往字典中添加key/value
"""
URL_FUNC_DICT = dict()
# func_list = list()
def route(url): # route: 路由
def set_func(func):
# func_list.append(func) # 将每一个传进来的函数的引用放进列表里边 直接放在字典里边
# 就相当于URL_FUNC_DICT["/index.py"] = index
URL_FUNC_DICT[url] = func
def call_func(*args,**kwargs):
return func(*args,**kwargs)
return call_func
return set_func
"""
路由:根据你的请求不一样,调用的功能不同,实现路由的核心原因应用到了映射
只要一用装饰器,被装饰的函数的引用就会传进装饰器函数里边,定义一个列表,
将每一个传进装饰器函数的函数的引用放进列表中
得到函数的引用之后,只要再保证怎么对应每个函数的引用即可
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
"""
这个使用装饰器解决问题的思想比较重要,学会怎么用来解决问题,因为装饰器是这个模块在执行的时候他就被执行了,而不是因为
你调用这个函数它才执行的,就是利用它的这个特点,保证了只要它默认执行了字典里边就会保存想要使用的数据,就行了
"""
@route(r"/index.html")
def index(ret):
with open("./templates/index.html") as f:
content = f.read()
# my_stock_info = "哈哈哈哈 这是你的本月名称....."
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select * from info;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<input type="button" value="添加" id="toAdd" name="toAdd" systemidvaule="%s">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6],line_info[7], line_info[1])
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
@route(r"/center.html")
def center(ret):
with open("./templates/center.html") as f:
content = f.read()
# my_stock_info = "这里是从mysql查询出来的数据。。。"
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select i.code,i.short,i.chg,i.turnover,i.price,i.highs,f.note_info from info as i inner join focus as f on i.id=f.info_id;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """
<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<a type="button" class="btn btn-default btn-xs" href="/update/%s.html"> <span class="glyphicon glyphicon-star" aria-hidden="true"></span> 修改 </a>
</td>
<td>
<input type="button" value="删除" id="toDel" name="toDel" systemidvaule="%s">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6],line_info[0],line_info[0])
# 括号里的数据的个数,与上边%s的个数相同,因为第一个和最后一个数据相同,所以相同
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
# 给路由添加正则表达式的原因:在实际开发时,url中往往会带有很多参数,例如/add/000007.html中000007就是参数,
# 如果没有正则的话,那么就需要编写N次@route来进行添加 url对应的函数 到字典中,此时字典中的键值对有N个,浪费空间
# 而采用了正则的话,那么只要编写1次@route就可以完成多个 url例如/add/00007.html /add/000036.html等对应同一个函数,此时字典中的键值对个数会少很多
@route(r"/add/(\d+)\.html")
# 正则中的add,只是为了增强可读性,具体叫什么无所谓,add保证了请求的是同一个函数或者是同一种处理方式,后边的值不一样,说明后面的值表示参数
# 下方的函数只返回一个Ok一点用也没有
def add_focus(ret):
# 怎么取\d+的值呢?
# 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
# 1.获取股票代码
stock_code = ret.group(1)
# 2.判断一下是否有这个股票代码
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
cs = conn.cursor()
sql = """select * from info where code=%s;""" # 注意结尾要加分号";",此处要防止sql注入
cs.execute(sql,(stock_code,)) # ?
# 如果要是没有这个股票代码,那么就认为是非法请求
if not cs.fetchone():
cs.close()
conn.close()
return "没有这支股票,大哥,我们是创业公司,请手下留情"
# 3.判断一下是否已经关注过
sql = """select * from info as i inner join focus as f on i.id=f.info_id where i.code=%s;"""
# 不要在程序里边测试sql语句,在mysql里边测试好了再拿过来
cs.execute(sql,(stock_code,))
# 如果查出来了那么就表示已经关注过
if cs.fetchone():
cs.close()
conn.close()
return "已经关注了,请勿重复关注.."
# 4.添加关注
sql = """insert into focus (info_id) select id from info where code=%s;"""
cs.execute(sql,(stock_code,))
conn.commit() # 添加要提交
cs.close()
conn.close()
return "关注成功....."
"""
为什么要用return返回值?
当你在实际开发的时候因为浏览器先要把请求给服务器,服务器再给框架,框架再处理,处理完了再给服务器,服务器再给浏览器,这个过程
十分长,往往浏览器看不见结果,怎么才能保证我请求的这个过程再回来整个一定是个通的,是可以运行的呢?
思想:
请求一个url,不要管里边返回什么,先给我一个字符串,什么都行,先给我打回来,要是能打得回来,就说明从浏览器发出请求到服务器返回
这个过程整个都是通的,如果确定整个过程是通的只需要根据返回的信息开会一步步的调试即可
"""
@route(r"/del/(\d+)\.html")
# 正则中的add,只是为了增强可读性,具体叫什么无所谓,add保证了请求的是同一个函数或者是同一种处理方式,后边的值不一样,说明后面的值表示参数
# 下方的函数只返回一个Ok一点用也没有
def del_focus(ret):
# 怎么取\d+的值呢?
# 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
# 1.获取股票代码
stock_code = ret.group(1)
# 2.判断一下是否有这个股票代码
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
cs = conn.cursor()
sql = """select * from info where code=%s;""" # 注意结尾要加分号";",此处要防止sql注入
cs.execute(sql,(stock_code,)) # ?
# 如果要是没有这个股票代码,那么就认为是非法请求
if not cs.fetchone():
cs.close()
conn.close()
return "没有这支股票,大哥,我们是创业公司,请手下留情"
# 3.判断一下是否已经关注过,关注了才能删,没关你删个毛线
sql = """select * from info as i inner join focus as f on i.id = f.info_id where i.code = %s;"""
# 不要在程序里边测试sql语句,在mysql里边测试好了再拿过来
cs.execute(sql,(stock_code,))
# 如果没有关注过,那么表示非法的请求
if not cs.fetchone():
cs.close()
conn.close()
return "%s之前未曾关注,无法取消" % stock_code
# 4.取消关注
# sql = """insert into focus (info_id) select id from info where code=%s;"""
sql = """delete from focus where info_id = (select id from info where code=%s);"""
cs.execute(sql,(stock_code,))
conn.commit() # 添加要提交
cs.close()
conn.close()
return "取消关注成功....."
"""
出现问题的时候,要学会去猜问题出现在哪里,根据表现形式去猜
流程是否有问题(流程没有问题)
根据浏览器返回的现象(思考问题出在哪里?"之前未关注"是查数据没有查出来,判断是否关注过的时候将判断的数据输出来,看看有什么问题)
数据没有查出来的原因:sql语句是否有什么问题(到mysql里边去测试sql语句是否正确),给sql语句传的参数对吗(将传的参数输出,看是否正确)
"""
"""
为什么要用return返回值?
当你在实际开发的时候因为浏览器先要把请求给服务器,服务器再给框架,框架再处理,处理完了再给服务器,服务器再给浏览器,这个过程
十分长,往往浏览器看不见结果,怎么才能保证我请求的这个过程再回来整个一定是个通的,是可以运行的呢?
思想:
请求一个url,不要管里边返回什么,先给我一个字符串,什么都行,先给我打回来,要是能打得回来,就说明从浏览器发出请求到服务器返回
这个过程整个都是通的,如果确定整个过程是通的只需要根据返回的信息开会一步步的调试即可
"""
@route(r"/update/(\d+)\.html") # 正则表达式的形式根据浏览器返回的现象语句写:请求的url(/update/000060.html)没有对应的函数....
def show_update_page(ret):
"""显示修改的那个页面"""
# 1.获取股票代码
stock_code = ret.group(1)
# 2.打开模版
with open("./templates/update.html") as f: # 打开模版,输入模版路径
content = f.read() # 将模版读取出来,最终目的是return这个模版
# 上边两行是打开一个模版的流程
"""
给它股票代码,它找到对应的id值,拿着这个id值去与focus里边的info_id对应,取出note_info
"""
# 3.根据股票代码,查询相关备注信息
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
sql = """select f.note_info from focus as f inner join info as i on i.id=f.info_id where i.code=%s;"""
cs.execute(sql,(stock_code,))
stock_infos = cs.fetchone()
note_info = stock_infos[0] # 获取这个股票对应的备注信息,备注信息在取出的元组的第几个字段
cs.close()
conn.close()
content = re.sub(r"\{%note_info%\}",note_info,content) # 替换浏览器中返回的%note_info%
content = re.sub(r"\{%code%\}",stock_code,content) # 替换浏览器中返回的%note_info%
return content
@route(r"/update/(\d+)/(\w+)\.html") # 请求的url(/update/000060/备注信息.html)没有对应的函数...
def save_update_page(ret):
"""保存修改的备注信息"""
stock_code = ret.group(1) # 取得是第一个(\d+)的值,也就是股票编号
comment = ret.group(2) # 取得是第二个(\d+)的值,也就是备注信息,comment字段也在返回的网址信息里边
# 将从浏览器获得的用户输入的信息更新保存进数据库
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
sql = """update focus set note_info = %s where info_id = (select id from info where code=%s);"""
cs.execute(sql,(comment,stock_code)) # 上边有两个%s,替换时注意顺序,显示评论即备注信息,然后是代码编号
conn.commit()
cs.close()
conn.close()
return "修改成功"
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
"""
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
"""
"""
这里通过if语句判断,web框架需要返回什么内容,要是有n多个页面要打开,那岂不是要n个if判断???!!!
一般超过5,6个就不应该用这个解决方案
这肯定不是通用的解法
通用解法的思路:
以前在调用字典的时候,先定义一个字典,里边有很多值,你调用这个字典的时候,用一个中括号,你写不一样的key值将来的返回值就不一样
以字典中取值的思路来思考这个问题
此处问题的核心就是,不想自己写这么多恶心的if判断,想实现根据你的不同的请求,让它自动去调不同的函数
思路:
用一个字典,字典里边让请求的url(网址)这个资源文件当作key,方法名(函数的引用)当做value值,那么最终
我给你一个key值,就返回一个value,又因为value是一个函数的引用,当然可以括起来直接调用了
这种方法代码量不一定少,但是这个调用过程一定是一种优化
缺点:每次往字典里边写东西依旧比较麻烦,最好找个东西直接让字典里边含有相应的内容
使用装饰器来解决这个问题
思路:
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
try:
# func = URL_FUNC_DICT[file_name] # 不管字典中有多少个值,只要传过来的file_name有与之匹配的key值就可以找到相应的函数的引用
# 此处的key值要是没有,程序可能会挂掉,可以用异常解决,好处是异常具有传递性,不仅可以判断这里key值的异常,还可以处理
# 调用过程中出现的未解决的异常,保证程序不会死
# return func() # 调用函数,因为调用的函数有返回值,所以加上一个return
for url, func in URL_FUNC_DICT.items():
# {
# r"/index.html":index,
# r"/center.html":center,
# r"/add/\d+\.html":add_focus
# }
ret = re.match(url, file_name) # 正则匹配的结果存储在ret这个对象里边
if ret:
return func(ret) # 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
else:
return "请求的url(%s)没有对应的函数...." % file_name
except Exception as ret:
return "产生了异常:%s" % str(ret)
# web服务器调用的这里,出现异常会没有body返回回去了,浏览器就挂了,所以找这个return返回的东西作为body
05_url编解码
对于用户输入的一些特定的字符,空格,/,#…计算机都会进行一定的编码,目的只有一个保证接下来服务器在去解析url的时候不会出错
这就是url的编码,编码之后排除了特殊的符号
具体流程应该是浏览器给服务器的时候,要进行编码;服务器将数据传给frame框架的时候,frame要向mysql里边保存,故要在想数据库保存之前要进行解码,
只要用框架将码解出来即可.url编码是为了防止在传输的时候出错的,不是防止在保存到数据库的时候出错的,所以框架收到数据进行解码,解出来之后就会变成原来输入的
数据,将原来的数据存储到数据库里边去
web_server
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application,static_path):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
self.static_path = static_path
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.html结尾,那么就认为请求的是静态资源(css/js/png/jpg等)(.py结尾的在实际中不会见到),直接在服务器中向下打开返回数据,要是是html请求,就进行调用,调用web框架来返回数据
if not file_name.endswith(".html"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open(self.static_path+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
with open("./web_server.conf") as f:
conf_info = eval(f.read())
# 此时conf_info是一个字典,里面的数据为:
# {
# "static_path":"./static",
# "dynamic_frame_path":"./dynamic_frame"
# }
# 此处的核心操作是:将要配置的文件(即在程序中要用到的文件夹)以字典的形式(由于不是在.py文件里边,实际上是字符串)存储在一个普通文件里,使用的时候转成字典使用,使用字典的key值去对应
# 相应的文件,这样在配置文件的时候就不用改程序了,只需要叫相应的文件写在普通文件的"value"值里边即可
# 类里边的方法要使用主函数的变量值的时候一定要进行传参,即在创建对象的时候把参数传进去
# 传进初始化方法__init__方法中,并在该方法中用self.定义成实例属性,才能由别的方法
# 通过self.的方式调用
sys.path.append(conf_info['dynamic_frame_path'])
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application,conf_info['static_path'])
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
web_frame
import re
import urllib.parse # 导入python中进行编解码的模块
from pymysql import connect
"""
到目前为止,这个web服务器已经基本上不需要动了,实在有需求再改.同样,现在的web框架也基本上定型了
web服务器首先要调用的函数application()已经基本不变了,最开始的装饰器的过程,及字典的部分也基
本不变了.
再有功能变动的话,你唯独需要在这个web框架里边写什么呢?
写一个函数用装饰器装一下,写一个函数用装饰器装一下,至于怎么调用的,谁来调用的,以及如何返回数据的
统统都不管,只需要写一个函数用装饰器装一下即可.
实际开发就是这个样子,如果把框架给了你,要加一个登录页面,即只要写一个log函数,用装饰器装一下子,
访问log.html的时候调用我的这个函数即可(字典里的key/value)
总是用装饰器装一下是因为要通过这个过程往字典中添加key/value
"""
URL_FUNC_DICT = dict()
# func_list = list()
def route(url): # route: 路由
def set_func(func):
# func_list.append(func) # 将每一个传进来的函数的引用放进列表里边 直接放在字典里边
# 就相当于URL_FUNC_DICT["/index.py"] = index
URL_FUNC_DICT[url] = func
def call_func(*args,**kwargs):
return func(*args,**kwargs)
return call_func
return set_func
"""
路由:根据你的请求不一样,调用的功能不同,实现路由的核心原因应用到了映射
只要一用装饰器,被装饰的函数的引用就会传进装饰器函数里边,定义一个列表,
将每一个传进装饰器函数的函数的引用放进列表中
得到函数的引用之后,只要再保证怎么对应每个函数的引用即可
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
"""
这个使用装饰器解决问题的思想比较重要,学会怎么用来解决问题,因为装饰器是这个模块在执行的时候他就被执行了,而不是因为
你调用这个函数它才执行的,就是利用它的这个特点,保证了只要它默认执行了字典里边就会保存想要使用的数据,就行了
"""
@route(r"/index.html")
def index(ret):
with open("./templates/index.html") as f:
content = f.read()
# my_stock_info = "哈哈哈哈 这是你的本月名称....."
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select * from info;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<input type="button" value="添加" id="toAdd" name="toAdd" systemidvaule="%s">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6],line_info[7], line_info[1])
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
@route(r"/center.html")
def center(ret):
with open("./templates/center.html") as f:
content = f.read()
# my_stock_info = "这里是从mysql查询出来的数据。。。"
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select i.code,i.short,i.chg,i.turnover,i.price,i.highs,f.note_info from info as i inner join focus as f on i.id=f.info_id;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """
<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<a type="button" class="btn btn-default btn-xs" href="/update/%s.html"> <span class="glyphicon glyphicon-star" aria-hidden="true"></span> 修改 </a>
</td>
<td>
<input type="button" value="删除" id="toDel" name="toDel" systemidvaule="%s">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6],line_info[0],line_info[0])
# 括号里的数据的个数,与上边%s的个数相同,因为第一个和最后一个数据相同,所以相同
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
# 给路由添加正则表达式的原因:在实际开发时,url中往往会带有很多参数,例如/add/000007.html中000007就是参数,
# 如果没有正则的话,那么就需要编写N次@route来进行添加 url对应的函数 到字典中,此时字典中的键值对有N个,浪费空间
# 而采用了正则的话,那么只要编写1次@route就可以完成多个 url例如/add/00007.html /add/000036.html等对应同一个函数,此时字典中的键值对个数会少很多
@route(r"/add/(\d+)\.html")
# 正则中的add,只是为了增强可读性,具体叫什么无所谓,add保证了请求的是同一个函数或者是同一种处理方式,后边的值不一样,说明后面的值表示参数
# 下方的函数只返回一个Ok一点用也没有
def add_focus(ret):
# 怎么取\d+的值呢?
# 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
# 1.获取股票代码
stock_code = ret.group(1)
# 2.判断一下是否有这个股票代码
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
cs = conn.cursor()
sql = """select * from info where code=%s;""" # 注意结尾要加分号";",此处要防止sql注入
cs.execute(sql,(stock_code,)) # ?
# 如果要是没有这个股票代码,那么就认为是非法请求
if not cs.fetchone():
cs.close()
conn.close()
return "没有这支股票,大哥,我们是创业公司,请手下留情"
# 3.判断一下是否已经关注过
sql = """select * from info as i inner join focus as f on i.id=f.info_id where i.code=%s;"""
# 不要在程序里边测试sql语句,在mysql里边测试好了再拿过来
cs.execute(sql,(stock_code,))
# 如果查出来了那么就表示已经关注过
if cs.fetchone():
cs.close()
conn.close()
return "已经关注了,请勿重复关注.."
# 4.添加关注
sql = """insert into focus (info_id) select id from info where code=%s;"""
cs.execute(sql,(stock_code,))
conn.commit() # 添加要提交
cs.close()
conn.close()
return "关注成功....."
"""
为什么要用return返回值?
当你在实际开发的时候因为浏览器先要把请求给服务器,服务器再给框架,框架再处理,处理完了再给服务器,服务器再给浏览器,这个过程
十分长,往往浏览器看不见结果,怎么才能保证我请求的这个过程再回来整个一定是个通的,是可以运行的呢?
思想:
请求一个url,不要管里边返回什么,先给我一个字符串,什么都行,先给我打回来,要是能打得回来,就说明从浏览器发出请求到服务器返回
这个过程整个都是通的,如果确定整个过程是通的只需要根据返回的信息开会一步步的调试即可
"""
@route(r"/del/(\d+)\.html")
# 正则中的add,只是为了增强可读性,具体叫什么无所谓,add保证了请求的是同一个函数或者是同一种处理方式,后边的值不一样,说明后面的值表示参数
# 下方的函数只返回一个Ok一点用也没有
def del_focus(ret):
# 怎么取\d+的值呢?
# 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
# 1.获取股票代码
stock_code = ret.group(1)
# 2.判断一下是否有这个股票代码
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
cs = conn.cursor()
sql = """select * from info where code=%s;""" # 注意结尾要加分号";",此处要防止sql注入
cs.execute(sql,(stock_code,)) # ?
# 如果要是没有这个股票代码,那么就认为是非法请求
if not cs.fetchone():
cs.close()
conn.close()
return "没有这支股票,大哥,我们是创业公司,请手下留情"
# 3.判断一下是否已经关注过,关注了才能删,没关你删个毛线
sql = """select * from info as i inner join focus as f on i.id = f.info_id where i.code = %s;"""
# 不要在程序里边测试sql语句,在mysql里边测试好了再拿过来
cs.execute(sql,(stock_code,))
# 如果没有关注过,那么表示非法的请求
if not cs.fetchone():
cs.close()
conn.close()
return "%s之前未曾关注,无法取消" % stock_code
# 4.取消关注
# sql = """insert into focus (info_id) select id from info where code=%s;"""
sql = """delete from focus where info_id = (select id from info where code=%s);"""
cs.execute(sql,(stock_code,))
conn.commit() # 添加要提交
cs.close()
conn.close()
return "取消关注成功....."
"""
出现问题的时候,要学会去猜问题出现在哪里,根据表现形式去猜
流程是否有问题(流程没有问题)
根据浏览器返回的现象(思考问题出在哪里?"之前未关注"是查数据没有查出来,判断是否关注过的时候将判断的数据输出来,看看有什么问题)
数据没有查出来的原因:sql语句是否有什么问题(到mysql里边去测试sql语句是否正确),给sql语句传的参数对吗(将传的参数输出,看是否正确)
"""
"""
为什么要用return返回值?
当你在实际开发的时候因为浏览器先要把请求给服务器,服务器再给框架,框架再处理,处理完了再给服务器,服务器再给浏览器,这个过程
十分长,往往浏览器看不见结果,怎么才能保证我请求的这个过程再回来整个一定是个通的,是可以运行的呢?
思想:
请求一个url,不要管里边返回什么,先给我一个字符串,什么都行,先给我打回来,要是能打得回来,就说明从浏览器发出请求到服务器返回
这个过程整个都是通的,如果确定整个过程是通的只需要根据返回的信息开会一步步的调试即可
"""
@route(r"/update/(\d+)\.html") # 正则表达式的形式根据浏览器返回的现象语句写:请求的url(/update/000060.html)没有对应的函数....
def show_update_page(ret):
"""显示修改的那个页面"""
# 1.获取股票代码
stock_code = ret.group(1)
# 2.打开模版
with open("./templates/update.html") as f: # 打开模版,输入模版路径
content = f.read() # 将模版读取出来,最终目的是return这个模版
# 上边两行是打开一个模版的流程
"""
给它股票代码,它找到对应的id值,拿着这个id值去与focus里边的info_id对应,取出note_info
"""
# 3.根据股票代码,查询相关备注信息
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
sql = """select f.note_info from focus as f inner join info as i on i.id=f.info_id where i.code=%s;"""
cs.execute(sql,(stock_code,))
stock_infos = cs.fetchone()
note_info = stock_infos[0] # 获取这个股票对应的备注信息,备注信息在取出的元组的第几个字段
cs.close()
conn.close()
content = re.sub(r"\{%note_info%\}",note_info,content) # 替换浏览器中返回的%note_info%
content = re.sub(r"\{%code%\}",stock_code,content) # 替换浏览器中返回的%note_info%
return content
@route(r"/update/(\d+)/(.*)\.html") # 请求的url(/update/000060/备注信息.html)没有对应的函数...
def save_update_page(ret):
"""保存修改的备注信息"""
stock_code = ret.group(1) # 取得是第一个(\d+)的值,也就是股票编号
comment = ret.group(2) # # 取得是第二个(\d+)的值,也就是备注信息,comment字段也在返回的网址信息里边
comment = urllib.parse.unquote(comment) # 对进行了url编码的数据进行解码
# 将从浏览器获得的用户输入的信息更新保存进数据库
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
sql = """update focus set note_info = %s where info_id = (select id from info where code=%s);"""
cs.execute(sql,(comment,stock_code)) # 上边有两个%s,替换时注意顺序,显示评论即备注信息,然后是代码编号
conn.commit()
cs.close()
conn.close()
return "修改成功"
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
"""
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
"""
"""
这里通过if语句判断,web框架需要返回什么内容,要是有n多个页面要打开,那岂不是要n个if判断???!!!
一般超过5,6个就不应该用这个解决方案
这肯定不是通用的解法
通用解法的思路:
以前在调用字典的时候,先定义一个字典,里边有很多值,你调用这个字典的时候,用一个中括号,你写不一样的key值将来的返回值就不一样
以字典中取值的思路来思考这个问题
此处问题的核心就是,不想自己写这么多恶心的if判断,想实现根据你的不同的请求,让它自动去调不同的函数
思路:
用一个字典,字典里边让请求的url(网址)这个资源文件当作key,方法名(函数的引用)当做value值,那么最终
我给你一个key值,就返回一个value,又因为value是一个函数的引用,当然可以括起来直接调用了
这种方法代码量不一定少,但是这个调用过程一定是一种优化
缺点:每次往字典里边写东西依旧比较麻烦,最好找个东西直接让字典里边含有相应的内容
使用装饰器来解决这个问题
思路:
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
try:
# func = URL_FUNC_DICT[file_name] # 不管字典中有多少个值,只要传过来的file_name有与之匹配的key值就可以找到相应的函数的引用
# 此处的key值要是没有,程序可能会挂掉,可以用异常解决,好处是异常具有传递性,不仅可以判断这里key值的异常,还可以处理
# 调用过程中出现的未解决的异常,保证程序不会死
# return func() # 调用函数,因为调用的函数有返回值,所以加上一个return
for url, func in URL_FUNC_DICT.items():
# {
# r"/index.html":index,
# r"/center.html":center,
# r"/add/\d+\.html":add_focus
# }
ret = re.match(url, file_name) # 正则匹配的结果存储在ret这个对象里边
if ret:
return func(ret) # 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
else:
return "请求的url(%s)没有对应的函数...." % file_name
except Exception as ret:
return "产生了异常:%s" % str(ret)
# web服务器调用的这里,出现异常会没有body返回回去了,浏览器就挂了,所以找这个return返回的东西作为body
06_添加log日志功能
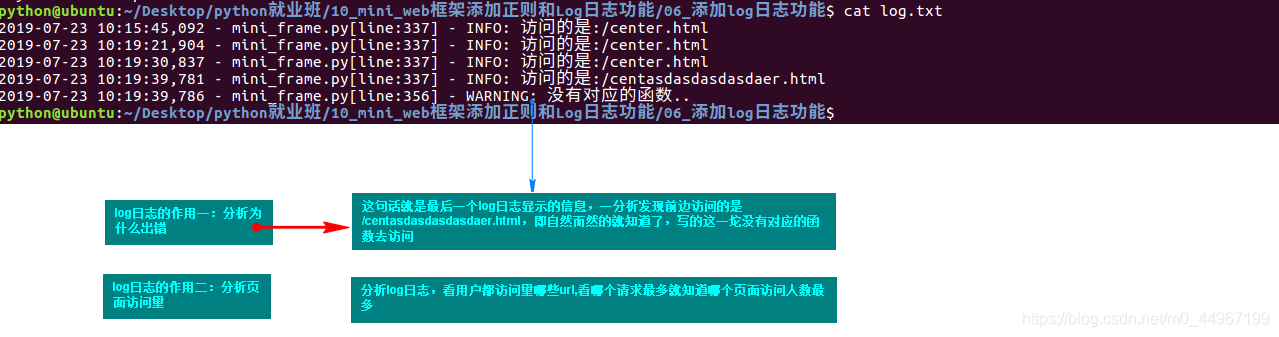
具体见讲义
web_sever
import socket
import re
import multiprocessing
import time
# import dynamic_frame.mini_frame # 包里的模块导入方式
# 原则:http的服务器应该是独立性的,即他应该做成通用的,谁都可以用,而不应该写成这样固定的形式
# 核心的目的是:不再提前导入固定要执行的模块了,框架名爱叫啥叫啥,在程序运行的时候给它指定
import sys
"""使用多进程实现多任务"""
class WSGISever(object):
"""服务器只负责转发和合并数据,它不做任何其他的事情"""
def __init__(self,port,application,static_path):
# 1.创建套接字
"""在一个类里边,一个方法所定义的属性,要想使类里边的其他方法可以使用,必须在变量名前加"self.",不加self就是局部变量,其他方法不能调用"""
self.tcp_sever_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.tcp_sever_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地服务器信息
self.tcp_sever_socket.bind(("",port)) # 由于下边不需要调用了,就不用用self.定义成实例属性了
# 3.变为监听(被动)套接字
self.tcp_sever_socket.listen(128)
self.application = application
# 下边其他函数还需要调用application,故定义成实例属性
self.static_path = static_path
def send_data_to_client(self,new_client_socket):
# 1.接收浏览器发来的请求,即http请求
# GET / HTTP/1.1
# ......
recv_request_content = new_client_socket.recv(1024).decode("utf-8")
# 1.1将接收到的请求进行切割,使之形成一个列表
request_lines_list = recv_request_content.splitlines()
print("\r\n")
print(request_lines_list)
# 1.2匹配出(找出)浏览器请求的相应文件名
# GET /index.html HTTP/1.1
ret = re.match(r"[^/]+([^ ]*)", request_lines_list[0])
file_name = ""
if ret:
file_name = ret.group(1)
print(">"*50,file_name)
if file_name == "/":
file_name = "/index.html"
# 2.回复浏览器的请求:返回http格式的数据,给浏览器
# 2.1如果请求的资源不是.html结尾,那么就认为请求的是静态资源(css/js/png/jpg等)(.py结尾的在实际中不会见到),直接在服务器中向下打开返回数据,要是是html请求,就进行调用,调用web框架来返回数据
if not file_name.endswith(".html"): # 在这里自己设定的以.py为结尾的为请求的动态数据
# endswith():判断以xxxx结尾;startwith():判断以xxx开头
try:
f = open(self.static_path+file_name, "rb")
except:
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
response += "----not find file----"
new_client_socket.send(response.encode("utf-8"))
else:
# 2.1准备发送给浏览器的数据----header
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# 2.2准备发送给浏览器的数据----body
file_content = f.read()
f.close()
# 将reponse header发送给浏览器
new_client_socket.send(response.encode("utf-8"))
# 将reponse body发送给浏览器
new_client_socket.send(file_content)
else:
# 如果是.py结尾就认为请求的是动态资源
env = dict()
env['PATH_INFO'] = file_name
# body = dynamic_frame.mini_frame.application(env,self.set_response_header)
body = self.application(env,self.set_response_header)
# 不指定固定的模块来调用application,换成其他的可以够到application即可,并在运行时指定,
# 这样就可以支持所有的框架
# body=xxx执行结束后才能获得header值,因此将header=xxx放在后边
header = "HTTP/1.1 %s\r\n" % self.status
for tem in self.headers:
header += "%s:%s\r\n" % (tem[0],tem[1])
header += "\r\n"
response = header + body
# 发送response相应给浏览器
new_client_socket.send(response.encode("utf-8"))
# 3.关闭套接字
new_client_socket.close()
def set_response_header(self,status,headers):
# 这个函数的意义就是:将框架返回的信息和服务器的信息整合(eg:输出服务器版本和框架信息)
# 要想在其他的实例方法中使用这个方法里的局部变量,即将其定义为实例属性
self.status = status
self.headers = [("sever","mini_web_v8.8")] # 服务器信息
self.headers += headers # 加上返回的框架的信息
def run_forever(self): # 一般情况来说,如果不确定是实例方法还是类方法,就先当作最常用的实例放法,先加上self
while True:
# 4.接收客户端信息:等待新客户端的链接
new_client_socket,client_address = self.tcp_sever_socket.accept()
"""这个局部变量的值,其他函数使用时是传进去的,所以不用定义成实例属性"""
# 5.为这个客户端服务:传递数据给客户端
p = multiprocessing.Process(target=self.send_data_to_client,args=(new_client_socket,))
# 单独调用函数的时候要传递参数,现在是开一个进程,让进程去做这个事情,已经指定里进程去哪里执行,故执行的时候要把参数扔进去
p.start()
new_client_socket.close()
# 为什么在函数中(子进程中)关闭了套接字,在这里(主进程)还要关闭一次才行呢?
# 6.关闭套接字
self.tcp_sever_socket.close()
def main():
"""对main函数的要求是简单:在这里就两步,创建对象,调用方法,由调用的方法再去调用其他方法"""
"""控制整体,创建一个web服务器对象,然后调用这个对象的run_forever方法运行"""
if len(sys.argv) == 3:
try:
port = int(sys.argv[1]) # 取出来是:7890
# 用int强制转换,要防止用户输的万一不是数字怎么办,使用try
frame_application_name = sys.argv[2] # 取出来是:mini_frame:application,取出来之后要将mini_frame切割出来,导入
except Exception as ret:
print("端口输入错误")
return
else:
print("请按照以下方式运行")
print("python3 xxx.py 7890 mini_frame:application")
return
# return两个功能:1.返回值,2.后边什么也不写,结束函数
# 取出来是:mini_frame:application,取出来之后要将mini_frame和application单独切割出来,
# 导入mini_frame,调用application
ret = re.match(r"([^:]+):(.*)",frame_application_name)
if ret:
frame_name = ret.group(1) # mini_frame
application_name = ret.group(2) # application
else:
return
with open("./web_server.conf") as f:
conf_info = eval(f.read())
# 此时conf_info是一个字典,里面的数据为:
# {
# "static_path":"./static",
# "dynamic_frame_path":"./dynamic_frame"
# }
# 此处的核心操作是:将要配置的文件(即在程序中要用到的文件夹)以字典的形式(由于不是在.py文件里边,实际上是字符串)存储在一个普通文件里,使用的时候转成字典使用,使用字典的key值去对应
# 相应的文件,这样在配置文件的时候就不用改程序了,只需要叫相应的文件写在普通文件的"value"值里边即可
# 类里边的方法要使用主函数的变量值的时候一定要进行传参,即在创建对象的时候把参数传进去
# 传进初始化方法__init__方法中,并在该方法中用self.定义成实例属性,才能由别的方法
# 通过self.的方式调用
sys.path.append(conf_info['dynamic_frame_path'])
# 在寻找mini_frame时,它不在当前路径下,找不到,将dynamic拿到当前路径下来就可以找到了
# import frame_name import导入的时候不会对frame_name这个变量进行解析,会直接把frame_name当做模块名,去找frame_name模块
frame = __import__(frame_name) # __import__导入的时候会对frame_name这个变量进行解析,找出对应到模块名
# __import__有返回值,这个返回值标记着要导入的模块
# 如何通过返回值找到application函数呢
application = getattr(frame, application_name) # 从哪个模块里边去找哪个函数(的名称)
# 此时application_name就指向了 dynamic/mini_frame模块中的application这个函数
# print(application)
wsgi_sever = WSGISever(port,application,conf_info['static_path'])
wsgi_sever.run_forever()
# 使程序不断循环下去
if __name__ == '__main__':
main()
web_mini_frame
import re
import urllib.parse # 导入python中进行编解码的模块
import logging # 导入log日志模块
from pymysql import connect
"""
到目前为止,这个web服务器已经基本上不需要动了,实在有需求再改.同样,现在的web框架也基本上定型了
web服务器首先要调用的函数application()已经基本不变了,最开始的装饰器的过程,及字典的部分也基
本不变了.
再有功能变动的话,你唯独需要在这个web框架里边写什么呢?
写一个函数用装饰器装一下,写一个函数用装饰器装一下,至于怎么调用的,谁来调用的,以及如何返回数据的
统统都不管,只需要写一个函数用装饰器装一下即可.
实际开发就是这个样子,如果把框架给了你,要加一个登录页面,即只要写一个log函数,用装饰器装一下子,
访问log.html的时候调用我的这个函数即可(字典里的key/value)
总是用装饰器装一下是因为要通过这个过程往字典中添加key/value
"""
URL_FUNC_DICT = dict()
# func_list = list()
def route(url): # route: 路由
def set_func(func):
# func_list.append(func) # 将每一个传进来的函数的引用放进列表里边 直接放在字典里边
# 就相当于URL_FUNC_DICT["/index.py"] = index
URL_FUNC_DICT[url] = func
def call_func(*args,**kwargs):
return func(*args,**kwargs)
return call_func
return set_func
"""
路由:根据你的请求不一样,调用的功能不同,实现路由的核心原因应用到了映射
只要一用装饰器,被装饰的函数的引用就会传进装饰器函数里边,定义一个列表,
将每一个传进装饰器函数的函数的引用放进列表中
得到函数的引用之后,只要再保证怎么对应每个函数的引用即可
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
"""
这个使用装饰器解决问题的思想比较重要,学会怎么用来解决问题,因为装饰器是这个模块在执行的时候他就被执行了,而不是因为
你调用这个函数它才执行的,就是利用它的这个特点,保证了只要它默认执行了字典里边就会保存想要使用的数据,就行了
"""
@route(r"/index.html")
def index(ret):
with open("./templates/index.html") as f:
content = f.read()
# my_stock_info = "哈哈哈哈 这是你的本月名称....."
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select * from info;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<input type="button" value="添加" id="toAdd" name="toAdd" systemidvaule="%s">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6],line_info[7], line_info[1])
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
@route(r"/center.html")
def center(ret):
with open("./templates/center.html") as f:
content = f.read()
# my_stock_info = "这里是从mysql查询出来的数据。。。"
# content = re.sub(r"\{%content%\}", my_stock_info, content)
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
cs.execute("select i.code,i.short,i.chg,i.turnover,i.price,i.highs,f.note_info from info as i inner join focus as f on i.id=f.info_id;")
stock_infos = cs.fetchall()
cs.close()
conn.close()
tr_template = """
<tr>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>
<a type="button" class="btn btn-default btn-xs" href="/update/%s.html"> <span class="glyphicon glyphicon-star" aria-hidden="true"></span> 修改 </a>
</td>
<td>
<input type="button" value="删除" id="toDel" name="toDel" systemidvaule="%s">
</td>
</tr>
"""
html = ""
for line_info in stock_infos:
html += tr_template % (line_info[0],line_info[1],line_info[2],line_info[3],line_info[4],line_info[5],line_info[6],line_info[0],line_info[0])
# 括号里的数据的个数,与上边%s的个数相同,因为第一个和最后一个数据相同,所以相同
# content = re.sub(r"\{%content%\}", str(stock_infos), content)
content = re.sub(r"\{%content%\}", html, content)
return content
# 给路由添加正则表达式的原因:在实际开发时,url中往往会带有很多参数,例如/add/000007.html中000007就是参数,
# 如果没有正则的话,那么就需要编写N次@route来进行添加 url对应的函数 到字典中,此时字典中的键值对有N个,浪费空间
# 而采用了正则的话,那么只要编写1次@route就可以完成多个 url例如/add/00007.html /add/000036.html等对应同一个函数,此时字典中的键值对个数会少很多
@route(r"/add/(\d+)\.html")
# 正则中的add,只是为了增强可读性,具体叫什么无所谓,add保证了请求的是同一个函数或者是同一种处理方式,后边的值不一样,说明后面的值表示参数
# 下方的函数只返回一个Ok一点用也没有
def add_focus(ret):
# 怎么取\d+的值呢?
# 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
# 1.获取股票代码
stock_code = ret.group(1)
# 2.判断一下是否有这个股票代码
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
cs = conn.cursor()
sql = """select * from info where code=%s;""" # 注意结尾要加分号";",此处要防止sql注入
cs.execute(sql,(stock_code,)) # ?
# 如果要是没有这个股票代码,那么就认为是非法请求
if not cs.fetchone():
cs.close()
conn.close()
return "没有这支股票,大哥,我们是创业公司,请手下留情"
# 3.判断一下是否已经关注过
sql = """select * from info as i inner join focus as f on i.id=f.info_id where i.code=%s;"""
# 不要在程序里边测试sql语句,在mysql里边测试好了再拿过来
cs.execute(sql,(stock_code,))
# 如果查出来了那么就表示已经关注过
if cs.fetchone():
cs.close()
conn.close()
return "已经关注了,请勿重复关注.."
# 4.添加关注
sql = """insert into focus (info_id) select id from info where code=%s;"""
cs.execute(sql,(stock_code,))
conn.commit() # 添加要提交
cs.close()
conn.close()
return "关注成功....."
"""
为什么要用return返回值?
当你在实际开发的时候因为浏览器先要把请求给服务器,服务器再给框架,框架再处理,处理完了再给服务器,服务器再给浏览器,这个过程
十分长,往往浏览器看不见结果,怎么才能保证我请求的这个过程再回来整个一定是个通的,是可以运行的呢?
思想:
请求一个url,不要管里边返回什么,先给我一个字符串,什么都行,先给我打回来,要是能打得回来,就说明从浏览器发出请求到服务器返回
这个过程整个都是通的,如果确定整个过程是通的只需要根据返回的信息开会一步步的调试即可
"""
@route(r"/del/(\d+)\.html")
# 正则中的add,只是为了增强可读性,具体叫什么无所谓,add保证了请求的是同一个函数或者是同一种处理方式,后边的值不一样,说明后面的值表示参数
# 下方的函数只返回一个Ok一点用也没有
def del_focus(ret):
# 怎么取\d+的值呢?
# 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
# 1.获取股票代码
stock_code = ret.group(1)
# 2.判断一下是否有这个股票代码
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
cs = conn.cursor()
sql = """select * from info where code=%s;""" # 注意结尾要加分号";",此处要防止sql注入
cs.execute(sql,(stock_code,)) # ?
# 如果要是没有这个股票代码,那么就认为是非法请求
if not cs.fetchone():
cs.close()
conn.close()
return "没有这支股票,大哥,我们是创业公司,请手下留情"
# 3.判断一下是否已经关注过,关注了才能删,没关你删个毛线
sql = """select * from info as i inner join focus as f on i.id = f.info_id where i.code = %s;"""
# 不要在程序里边测试sql语句,在mysql里边测试好了再拿过来
cs.execute(sql,(stock_code,))
# 如果没有关注过,那么表示非法的请求
if not cs.fetchone():
cs.close()
conn.close()
return "%s之前未曾关注,无法取消" % stock_code
# 4.取消关注
# sql = """insert into focus (info_id) select id from info where code=%s;"""
sql = """delete from focus where info_id = (select id from info where code=%s);"""
cs.execute(sql,(stock_code,))
conn.commit() # 添加要提交
cs.close()
conn.close()
return "取消关注成功....."
"""
出现问题的时候,要学会去猜问题出现在哪里,根据表现形式去猜
流程是否有问题(流程没有问题)
根据浏览器返回的现象(思考问题出在哪里?"之前未关注"是查数据没有查出来,判断是否关注过的时候将判断的数据输出来,看看有什么问题)
数据没有查出来的原因:sql语句是否有什么问题(到mysql里边去测试sql语句是否正确),给sql语句传的参数对吗(将传的参数输出,看是否正确)
"""
"""
为什么要用return返回值?
当你在实际开发的时候因为浏览器先要把请求给服务器,服务器再给框架,框架再处理,处理完了再给服务器,服务器再给浏览器,这个过程
十分长,往往浏览器看不见结果,怎么才能保证我请求的这个过程再回来整个一定是个通的,是可以运行的呢?
思想:
请求一个url,不要管里边返回什么,先给我一个字符串,什么都行,先给我打回来,要是能打得回来,就说明从浏览器发出请求到服务器返回
这个过程整个都是通的,如果确定整个过程是通的只需要根据返回的信息开会一步步的调试即可
"""
@route(r"/update/(\d+)\.html") # 正则表达式的形式根据浏览器返回的现象语句写:请求的url(/update/000060.html)没有对应的函数....
def show_update_page(ret):
"""显示修改的那个页面"""
# 1.获取股票代码
stock_code = ret.group(1)
# 2.打开模版
with open("./templates/update.html") as f: # 打开模版,输入模版路径
content = f.read() # 将模版读取出来,最终目的是return这个模版
# 上边两行是打开一个模版的流程
"""
给它股票代码,它找到对应的id值,拿着这个id值去与focus里边的info_id对应,取出note_info
"""
# 3.根据股票代码,查询相关备注信息
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
sql = """select f.note_info from focus as f inner join info as i on i.id=f.info_id where i.code=%s;"""
cs.execute(sql,(stock_code,))
stock_infos = cs.fetchone()
note_info = stock_infos[0] # 获取这个股票对应的备注信息,备注信息在取出的元组的第几个字段
cs.close()
conn.close()
content = re.sub(r"\{%note_info%\}",note_info,content) # 替换浏览器中返回的%note_info%
content = re.sub(r"\{%code%\}",stock_code,content) # 替换浏览器中返回的%note_info%
return content
@route(r"/update/(\d+)/(.*)\.html") # 请求的url(/update/000060/备注信息.html)没有对应的函数...
def save_update_page(ret):
"""保存修改的备注信息"""
stock_code = ret.group(1) # 取得是第一个(\d+)的值,也就是股票编号
comment = ret.group(2) # # 取得是第二个(\d+)的值,也就是备注信息,comment字段也在返回的网址信息里边
comment = urllib.parse.unquote(comment) # 对进行了url编码的数据进行解码
# 将从浏览器获得的用户输入的信息更新保存进数据库
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='stock_db',charset='utf8')
# 获得Cursor对象
cs = conn.cursor()
sql = """update focus set note_info = %s where info_id = (select id from info where code=%s);"""
cs.execute(sql,(comment,stock_code)) # 上边有两个%s,替换时注意顺序,显示评论即备注信息,然后是代码编号
conn.commit()
cs.close()
conn.close()
return "修改成功"
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
# 在这个元组列表中,主要是用来写当前框架需要的信息
file_name = env['PATH_INFO']
# 字典里边的value值,使用key值往里边存,也使用key值往外边取
# 传递过来字典,取出字典里边的值的目的是为了看看浏览器请求的资源是什么.
# 接下来只需要调用相应的函数返回相应的页面信息即可
"""
if file_name == "/index.py":
return index()
# 这里return的是 index()的返回值,而index()要返回一个值也要使用return
elif file_name == "/center.py":
return center()
else:
return'Hello World! 我爱你,中国!'
"""
"""
这里通过if语句判断,web框架需要返回什么内容,要是有n多个页面要打开,那岂不是要n个if判断???!!!
一般超过5,6个就不应该用这个解决方案
这肯定不是通用的解法
通用解法的思路:
以前在调用字典的时候,先定义一个字典,里边有很多值,你调用这个字典的时候,用一个中括号,你写不一样的key值将来的返回值就不一样
以字典中取值的思路来思考这个问题
此处问题的核心就是,不想自己写这么多恶心的if判断,想实现根据你的不同的请求,让它自动去调不同的函数
思路:
用一个字典,字典里边让请求的url(网址)这个资源文件当作key,方法名(函数的引用)当做value值,那么最终
我给你一个key值,就返回一个value,又因为value是一个函数的引用,当然可以括起来直接调用了
这种方法代码量不一定少,但是这个调用过程一定是一种优化
缺点:每次往字典里边写东西依旧比较麻烦,最好找个东西直接让字典里边含有相应的内容
使用装饰器来解决这个问题
思路:
使用带参数的装饰器,将需要匹配的url传进最外层函数里边,返回中间层函数的引用,将被装饰函数的引用传给中间层函数,
将他们分别作为key和value值传入字典之中
"""
# 把你访问的是谁?什么时候访问的?这些信息加到这里边去
logging.basicConfig(level=logging.INFO, # 级别用大写字符写,INFO作为最基本的级别,记录的是最基本的信息,如是什么时候访问的哪个页面等
filename='./log.txt',
filemode='a', # w:表示删去文件中的内容;a:表示往文件中追加内容
format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
logging.info("访问的是:%s" % file_name) # 文件里边会出现这个内容
try:
# func = URL_FUNC_DICT[file_name] # 不管字典中有多少个值,只要传过来的file_name有与之匹配的key值就可以找到相应的函数的引用
# 此处的key值要是没有,程序可能会挂掉,可以用异常解决,好处是异常具有传递性,不仅可以判断这里key值的异常,还可以处理
# 调用过程中出现的未解决的异常,保证程序不会死
# return func() # 调用函数,因为调用的函数有返回值,所以加上一个return
for url, func in URL_FUNC_DICT.items():
# {
# r"/index.html":index,
# r"/center.html":center,
# r"/add/\d+\.html":add_focus
# }
ret = re.match(url, file_name) # 正则匹配的结果存储在ret这个对象里边
if ret:
return func(ret) # 将匹配的结果ret通过func()函数返回给函数add_focus(),通过其装饰器里边的正则表达式自行判断是否需要分组
else:
logging.warning("没有对应的函数..")
return "请求的url(%s)没有对应的函数...." % file_name
except Exception as ret:
return "产生了异常:%s" % str(ret)
# web服务器调用的这里,出现异常会没有body返回回去了,浏览器就挂了,所以找这个return返回的东西作为body
