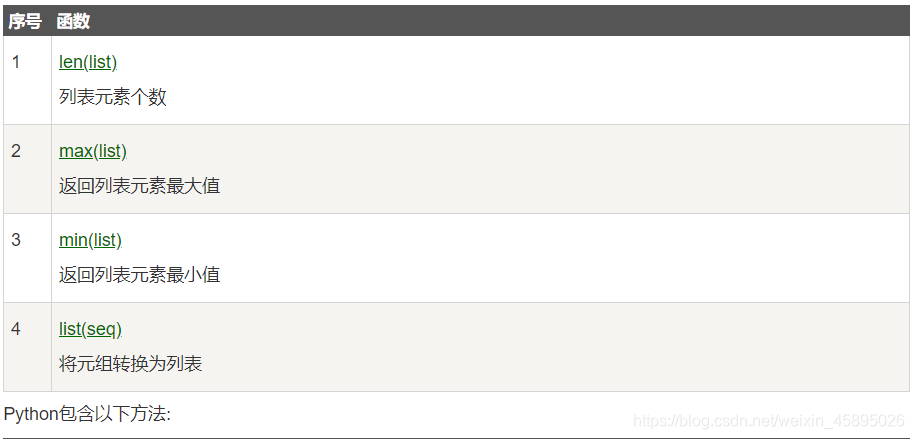
列表函数&方法
函数:
实例演示:
#len(list)
list1=['kkk','ddd','zzz']
print(len(list1))
list2=list(range(5))#创建一个0-4列表
print(len(list2))
#max(list)&min(list)
print(max(list1))
print(min(list1))
#list(seq)
atuple=(123,'Google','Taobao')
list3=list(atuple)
print(list3)
str="Hello Python"
list4=list(str)
print(list4)

方法:
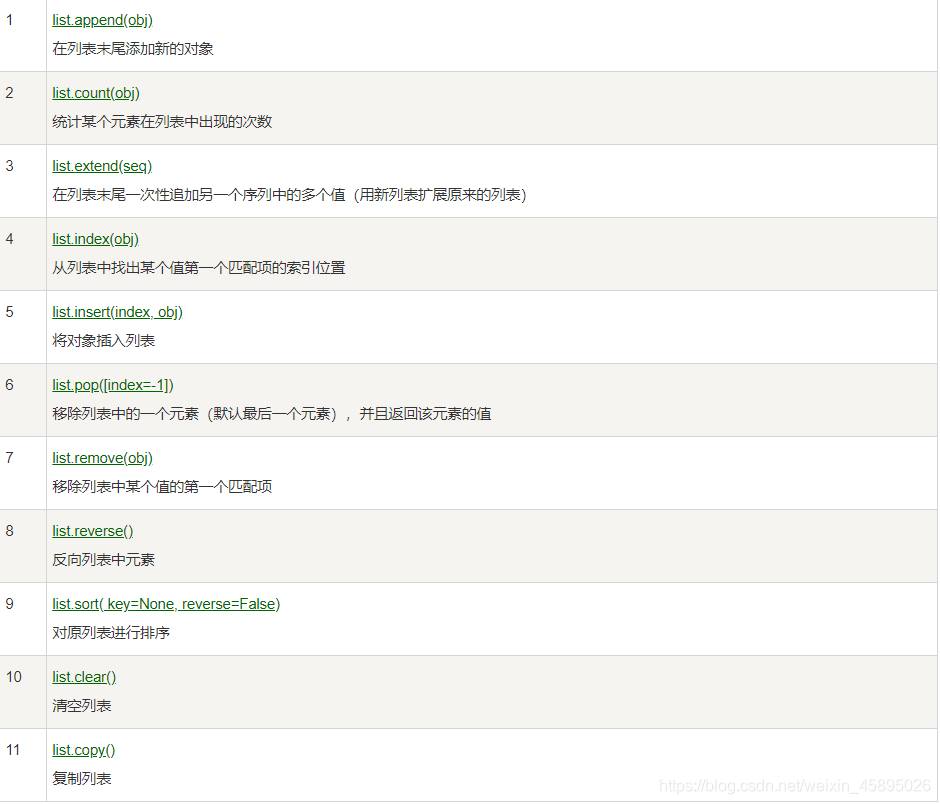
注意:其中很多函数都没有返回值,不能直接print
实例演示:
#list.append
list1=['kkk','ddd','zzz']
list1.append("kdz")
print(list1)
#list.count
print(list1.count('kkk'))
#list.extend
list1.extend(list2)#扩展列表
print(list1)
#list.index
print(list1.index('zzz'))
print(list1.index('zzz',2))#大于2再找会抛出异常
#list.insert
list1.insert(0,"武汉加油!")
print(list1)
#list.pop
list1.pop()
print(list1)#默认最后一个,跟栈很像
list1.pop(2)
print(list1)#指定位置弹出
#list.remove
list1.remove('kkk')
print(list1)
#list.reverse
list1.reverse()
print(list1)#颠倒
#list.sort
list2=['a','o','e','u','i']
list2.sort()
print(list2)#升序
list2.sort(reverse=True)
print(list2)#降序
# 获取列表的第二个元素
def takeSecond(elem):
return elem[1]
# 列表
random = [(2, 2), (3, 4), (4, 1), (1, 3)]
# 指定第二个元素排序
random.sort(key=takeSecond,reverse=False)
# 输出类别
print('排序列表:', random)
#list.copy
list4=list1.copy()
print(list4)
#list.clear
list1.clear()
print(list1)

元组内置函数

实例演示:

关于元组是不可变的
所谓元组的不可变指定是元组所指向的内存中的内容不可变
>>> tup = ('r', 'u', 'n', 'o', 'o', 'b')
>>> tup[0] = 'g' # 不支持修改元素
>Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> id(tup) # 查看内存地址
4440687904
>>> tup = (1,2,3)
>>> id(tup)
4441088800 # 内存地址不一样了
从以上实例可以看出,重新赋值的元组 tup,绑定到新的对象了,不是修改了原来的对象。
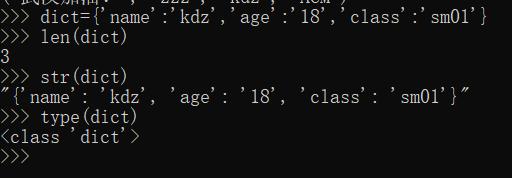
字典内置函数&方法
内置函数:

实例演示:
内置方法:

实例演示:
#radiansdict.clear()
dict ={'name': 'kdz', 'age': '18', 'class': 'sm01'}
dict.clear()#无返回值
print(dict)
#radiansdict.copy浅拷贝只拷贝父
dict1={'name': 'kdz', 'age': '18', 'class': 'sm01'}
dict2=dict1.copy()
print(dict2)
#直接赋值:其实就是对象的引用(别名)。
#浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
#深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
#radiansdict.fromkeys()
#seq -- 字典键值列表。
#value -- 可选参数, 设置键序列(seq)对应的值,默认为 None。
seq=('name','age','sex')
dict3=dict.fromkeys(seq)
print(dict3)
#不指定值
thisdict=dict.fromkeys(seq)
print(thisdict)
#radiansdict.get(key, default=None)
#key -- 字典中要查找的键。
#default -- 如果指定键的值不存在时,返回该默认值值。
print(dict1.get('name'))
print(dict1.get('name','kkk'))
#key in dict判断键
if'name'in dict1:
print('True')
else:
print('False')
if 'age' not in dict1:
print('True')
else:
print('False')
#radiansdict.items()以列表返回可遍历的(键, 值) 元组数组
print(dict1.items())
#字典 keys() 返回一个可迭代对象,可以使用 list() 来转换为列表。
print(dict1.keys())
print(list(dict1.keys()))
#setdefault() 方法和 get()方法 类似, 如果键不已经存在于字典中,将会添加键并将值设为默认值。
print(dict1.setdefault('name'))
print(dict1.setdefault('age',None))
#radiansdict.update(dict2)
dict4={'爱好':'basketball','身高':'186cm'}
dict1.update(dict4)
print(dict1)
#dict.values()
print(list(dict1.values()))
#pop()删除字典给定键 key 所对应的值
sc=dict1.pop('name','kdz')
print(sc)
# popitem() 方法随机返回并删除字典中的最后一对键和值。
k=dict1.popitem()
print(k)
print(dict1)

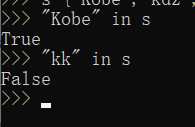
集合的基本操作
#s.add
s={"Kobe","kdz",'china','chinese'}
print(s)
s.add('James')
print(s)
#updata
s.update(['kkk','ddd','zzz'])
print(s)
#s.remove
s.remove('kkk')
print(s)
#s.discard
s.discard('kdkdkd')#不存在的不会报错
s.discard('ddd')
print(s)
#s.pop
s.pop()#set集合的pop方法会对集合进行无序的排列,然后删除左一
print(s)
#len(s)
print(len(s))
#s.clear
s.clear()
print(s)

x in set
集合内置方法完整列表
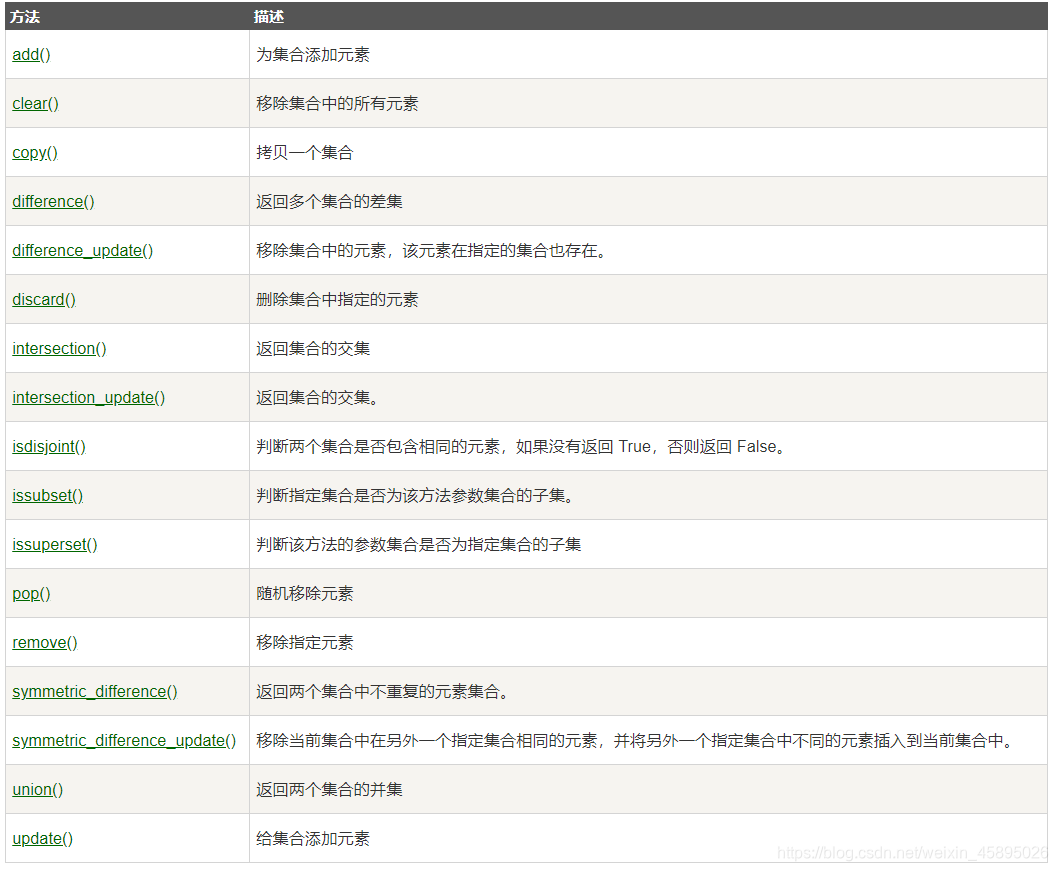
有部分函数已经在上述基本操作中提到,不再陈述
其余的,实例演示:
#difference返回一个集合,元素包含在集合 x ,但不在集合 y :
s1={"Kobe","kdz",'china','chinese'}
s2={"Kobe",'kdz',"chinese","English"}
z=s1.difference(s2)
print(z)
#difference_update()
#difference() 方法返回一个移除相同元素的新集合
# 而 difference_update() 方法是直接在原来的集合中移除元素,没有返回值。
s1.difference_update(s2)
print(s1)
#intersection()返回集合的交集
s3={"apple", "banana", "cherry","kkk"}
s4={"google", "runoob", "apple","kkk"}
s5={"banana","google","kkk"}
k=s3.intersection(s4)
print(k)
#多个集合的交集
i=s3.intersection(s4,s5)
print(i)
#intersection_update()
# intersection_update() 方法是在原始的集合上移除不重叠的元素。
s3.intersection_update(s4)
print(s3)#不共同拥有的元素被删除
#isdisjoint()
#判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False
print(s3.isdisjoint(s4))
#issubset()
# 用于判断集合的所有元素是否都包含在指定集合中,如果是则返回 True,否则返回 False。
print(s1.issubset(s4))
#issuperset()
# 判断指定集合的所有元素是否都包含在原始的集合中,如果是则返回 True,否则返回 False。
print(s5.issuperset(s3))#判断集合s3的所有元素是否都包含在s5中
#symmetric_difference()
# 返回两个集合中不重复的元素集合,即会移除两个集合中都存在的元素。
x = {"apple", "banana", "cherry"}
y = {"google", "runoob", "apple"}
print(x.symmetric_difference(y))
#symmetric_difference_update()
# 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
x.symmetric_difference_update(y)
print(x)
#union()
# 返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次。
print(x.union(y))

函数的相关到这里就结束了。
知识补充
迭代:
for x in []:,返回的是列表或元组形式
for x in ():,返回的是单组元素
例如:
list=['kkk','ddd','zzz']
tuple=('fedef','efef','kdz')
for x in(list):
print(x)
for x in [tuple]:
print(x)

几种删除操作的不同
- 在数字中,通过使用del语句删除单个或多个对象的引用
- 在列表中,使用 del 语句来删除列表的的元素
- 在元组中,元素值是不允许删除的,但我们可以使用del语句来删除整个元组,且删除后输出变量会有异常信息
- 在字典中,能删单(del)一的元素也能清空(clear)字典,清空只需一项操作。
