pandas如何去除重复值
在我们做数据分析时,我们所要处理的数据中难免会出现重复的数据,有些是我们需要的,有些是我们不需要的,甚至还会影响我们接下来数据分析的准确度。接下来,给大家介绍去除重复值的方法。
planets = pd.read_csv('planets.csv')
print(planets.head(10))
planets.drop_duplicates(subset=['method','year'],keep='first',inplace=True)
print(planets.head(10))
咱们先看一下结果:
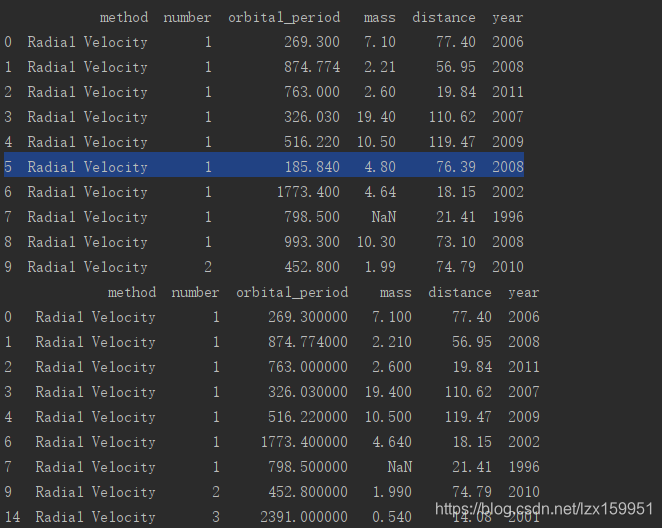
接下来我们解释一下:
- 首先read_csv读取数据
- head(10)获取数据的前十条
- planets.drop_duplicates(subset=[‘method’,‘year’],keep=‘first’,inplace=True)这个是最关键的语句了。
首先subset参数是一个列表,这个列表是需要你填进行相同数据判断的条件。就比如我选的条件是method和year,即 method值和year的值相同就可被判定为一样的数据。keep的取值有三个 分别是 first、last、false
keep=first时,保留相同数据的第一条。keep=last时,保存相同数据的最后一条。keep=false时,所有相同的数据都不保留。inplace=True时,会对原数据进行修改。否则,只返回视图,不对原数据修改。 - 咱们从数据结果图中可以看到,与数据1相同的有数据5和数据8,在第二个结果中只保留了数据0 因为我们keep=first。
