1.摘要
如果要将企业应用系统按照技术或数据按时间进行划分的话,那么可以以2008年Google推出的分布式文件系统DFS为一个划分标准,2008年之前,由于通信信息技术的弊端,还属于PC互联网时代,整个互联网产生的数据和现在相比只是量级分之一,所以基本上是传统的企业应用系统,将数据存储在RDBMS数据库中,再通过诸如J2EE的软件技术架构去操作这些数据。2008年之后,随着通信技术4G的诞生,迎来了在PC互联网时代基础上叠加的移动互联网时代,这个时候产生的数据是巨大的,从最开始的PB级到EB级,甚至对于很多如Google,Alibaba,Tencent等巨头企业,他们的数据可以达到ZB级。随着2019年5G被逐渐商用,未来可能会迎来万物互联的下一个互联网时代,数据的量可能还会出现量级的增长,甚至很多专家或学者将移动互联网和万物互联合称为大数据时代。但不管是2008年前的PC互联网时代,还是之后的移动互联网时代,甚至已经到来或即将到来的万物互联时代,或者说大数据时代,对数据的操作的要求都是很高,这里的操作具体体现在数据的读(查询本质上也是读,只是带计算的读)和写,以及计算,那么对数据操作的优化是非常有必要的。就目前而言,应用任何一个软件系统或产品,除网络状态以外,如果操作一个系统,需要5到10秒才能响应。那么这个软件系统基本上失败的,甚至是垃圾产品。而一个系统的响应速度,很大部分是数据操作的速度决定的。而对于大数据,对数据的操作的响应会要求更高,因为大数据时代在数据的存储,操作上和传统的有所不同。对于传统的系统而言,数据量少,在RDBMS中是直接存储原始数据,在系统中通过编程进行一些特定的出来就能达到系统的使用效果。而对于大数据时代,数据量的巨大,如果将原始数据直接存储在数据库中显然会带来很多问题,所在在大数据领域中,往往是先对数据预处理,所以有了ETL,数据治理,数据仓库,数据湖,数据集市等等一些概念和方案的诞生。不管是RDBMS,还是大数据或者大数据组件,优化是开发一个企业应用系统必不可少的工作。本篇博文主要讲述大数据的综合优化的一些思想,包括宏观的优化思想,从哪些方面优化及基于目前常用的大数据生态组件某些组件的具体优化方案和手段。
2.宏观的优化思想
宏观的优化思想是每个大数据工程师必须具备的常识。例如更高计算性能的服务器资源,分而治之等,接下来会从每个方面具体介绍
2.1.高性能的算力芯片
在现行的对于字符的计算一般服务器都是采用CPU计算,而不同代的CPU的算力是不一样的,CPU的性能越好,意味着对同一计算的时间更短,而优化本身就是在计算过程中让耗时达到极限的少。当然对于某些领域如图计算而言(这里补充一点,万物皆可量化为数据,图自然也是数据的一种),会采用CPU+GPU组合作计算
2.2.更充裕的内存
在很多大数据开发场景中,开发者会遇到集群中的某些机器内存被耗光或者内存空间不足导致计算数据的性能变慢,从而导致系统的响应时间不尽人意。想要弄清楚为什么会出现这种情况就必须明白内存,CPU,磁盘(也被称作外存)之间的关系了。内存是CPU与磁盘的沟通桥梁,计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大,内存的作用是将要把磁盘的数据给CPU计算的缓存之地,同时内存的读写效率远远高于磁盘。那么就意味着在CPU的算力固定下,内存越大,一次算的数据就越大,而内存的读写又高,可以整体将计算数据提升。相信很多开发者明白,很多数据库或者计算引擎会将内存作为数据的暂存之地,如Redis,Spark以提高数据的查询和计算性能。
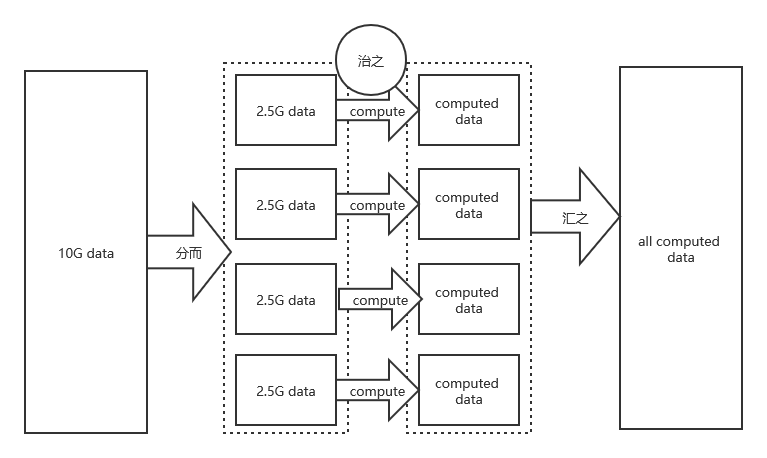
2.3.分而治之,治之汇之
个人觉得分而治之的思想是一个大数据开发者入门的必要思想,如果不能悟出分而治之的思想,或者在开发过程中不能很好的将分而治之的思想应用业务以提高产品性能,是一个不合格的大数据开发工程师。下面来举两个通俗的示例来解释分而治之:
a.第一个示例
现在假设你要把200斤的玉米从地里(A地)搬到家里(B地),两百斤你可以勉强搬得起,但是因为太重你就走得慢,假设需要一个小时。现在假设你搬20斤很轻松五分钟就可以从A地搬到B地了,那么分五次搬只需要50分钟了,这个时候就节省了10分钟,这就叫分而治之。同时因为劳累,你不确定自己搬了几次,你只能将已搬了的数一下,然后汇聚在一起,才能确定真的搬了200斤全部的。这就叫治之汇之。
b.第二个示例
现在假设有600斤玉米,你一个人从A搬到B,你为了能全部搬完,一次只能搬100斤,所以你要搬六次,假设搬100斤的时间是40分钟,你一个人搬需要需要6次,总共需要240分钟。你嫌太累太废时间,就叫了其他五个你的小伙伴帮你一起搬,这也叫分而治之,很轻松而且耗时很短的就搬完了,但你要确定每个小伙伴是不是真的搬了100斤,有没有只搬了90斤,所以需要将每个小伙伴的掂量一下确定总数,这就叫治之汇之。
上面两个示例中把搬运当成一种大数据开发中的一种计算就可以明白,分而治之是有不同的场景的,但对于大数据开发而言,一般都是基于实体(数据),时间的分而治之及汇之。参照下面示例图:
2.4.空间换时间
不管是上面的高性能的计算芯片,充裕的内存,分而治之还是更大的磁盘空间,本质上都是以空间换时间。众所周知,一个高性能的系统或产品,带来的经济效益是巨大的。而高性能的计算芯片,内存和磁盘在巨大的经济效益下是微不足道的。目前大数据开发实践上,本质上也遵循了空间换时间的标准。但是空间不是越大越好,比如一个小的大数据系统,采用了过多的磁盘空间,过多的内存空间等等,是有些浪费的。所以空间换时间更多的应该结合业务,如数据量大小,数据的计算的复杂度等等因素而定的,并不是盲目的增大。
2.5.数据结构的特性
在算力,内存,磁盘约定下,同时遵循了分而治之的思路,另一个方面就是数据结构也能对性能有很好的作用。目前大数据存储组件常用的大约有十几种,大数据计算引擎也有四五种,这些组件和计算引擎在很大程度上都是有独特的数据结构从而在特定的业务上提高性能。比如Hbase在key-value上针对数据量庞大的效果是很好的,那么在业务场景上,就可以应用在比如通过唯一标识找出数据信息,在比如说Clickhouse,将数据按照每一列存储,也称为列式存储。那么一般在数据字段多,但实际应用中不会全查,而是大部分只查部分字段的场景上,应用效果和性能都是很好的。再比如计算引擎Flink,特有的流式数据集就可以很好的提供计算引擎的计算效率。针对于这些事例很多,就不一一计算了,下面以两张图展现列式存储和行式存储的比较及流行的计算引擎的比较。
列式存储和行式存储:

计算引擎的比较:

关于计算引擎之间的原理及对比,个人觉得这篇博文(https://www.cnblogs.com/zdz8207/p/hadoop-spark-flink.html) 写得很好可以参考

2.6.总结
上述所说的一些宏观的优化思想,在理论上是很容易理解的。但日常的业务开发可能不仅仅是这么简单,需要受到实际的情况而定。在实践业务开发的过程中,往往是对应用的组件,计算引擎,数据库等各方面,再遵循这些宏观的思想,之后根据各个组件,计算引擎和数据库底层设计原理具体的去优化,当然这部分工作是很细致化的。当然,有过大数据开发实践经验的开发者都知道,基本上所有的大数据应用组件,在算力,内存,磁盘约定的情况下,都是遵循分而治之和空间换时间的标准的,只是每个组件在数据结构,底层的设计原理上有自己的设计思想和架构从而达到应有的特性及效果。
3.大数据中影响性能的某些关键点
3.1.数据倾斜
数据倾斜是很常见的现象,著名的二八理论本质上也是数据倾斜,80%的财富集中在20%的人手中, 80%的用户只使用20%的功能 , 20%的用户贡献了80%的访问量。数据倾斜简而言之是不同唯一标识值key的数据分布不均匀,一个key有十万条数据记录,而另一个key只有几百条数据记录。在实际的大数据业务开发中,针对数据的处理计算是并行计算的,为了简化理解,假设以一个key为一个任务,很多key组成了多个并行任务,那么数据记录多的key自然比数据少的key处理计算的时间要长,数据记录少的key处理完毕后要等待数据记录多的key,但是在开始任务时申请的资源又是大致相同的。那么会造成两个问题,第一个问题是数据记录多的key会拖累整体的性能,第二个问题是数据资源少的key的任务在一定程度上浪费了资源。这两个问题都是开发者不愿看到的。
对于数据倾斜的解决方案就是对每个任务的数据进行均衡,对key比较多的数据记录进行打散,这依然是分而治之的思想。当然这里是给了初略的方案思路,在后面会针对大数据每个组件解决数据倾斜的具体方案细节。3.2.一批次数据量过大
一批次数据量过大时非常常见的问题,而在实际的实践中可以知道,在资源一定的情况下,对数据的处理和计算数据量和计算时间并不是成正比的,假设计算处理1G的数据需要时间是1min,那么处理10G的数据消耗的时间大多情况下不可能是10min,可能是20分钟甚至更多。这就意味着数据量大会整体影响性能。针对一批数据量过大的问题,现在目前采用的对数据按时间或其他的业务含义进行分区处理,当然最常用的是时间分区,因为时间可以具体的细化,那么久可以很好的将数据量大分为多个小数据的分区。当然数据小不是绝对的,如果小数据太多会产生很多任务,所以数据量应当通过测试评估出来,比如HDFS建议一批的数据接近128M,过多的超过这个数据量过大或过小都会带来性能问题。3.3.数据字段过多
数据字段过多,这是针对于格式化的数据格式或数据表。数据字段意味着复杂的计算,那么复杂的计算必然带来资源的消耗和时间的花费。当然数据字段过多意味着数据架构设计不合理,对于数据字段过多应该依据业务的角度进行表的拆分。3.4.过多的复杂关联查询
在大数据开发中,查询是必不可少的。而站在业务的角度,复杂的查询是必然的,复杂的查询同样意味着复杂的计算。当然查询主要以SQL为主,比如在SQL中常用的复杂的关联查询,子查询,去重汇总查询都会一定程度上影响性能。在这一方面,,没有具体的方案。具体指导是针对业务对数据表结构和数据优化建模。关于这一点,后面会以某些组件为例,详细介绍具体的方案。3.5.数据表设计不合理
在大数据中,数据建模,数据表设计不合理不但会影响性能,同时会对业务系统的正常运行,开发效率带来很多问题。在这方面,大数据采用的方案是建立合理的数据仓库。而在数据仓库中,对数据根据业务进行维度和事实划分,就产生了维表和事实表,这样就产生了星型模型的设计理念。星型模型一定上能够对性能,开发效率,系统的正常运行有很好的提升。如果采用雪花模型就会带来很多问题了。下面是星型模型和雪花模型的概念a.星型模型
星座模型,是对星型模型的扩展延伸,多张事实表共享维度表。数仓模型建设后期,当一个星型模型为一个实体,又有多个是实体,实体间又共用维表(这个是很常见的),就自然成了星座模型了。大部分维度建模都是星座模型。
b.雪花模型
雪花模型,在星型模型的基础上,维度表上又关联了其他维度表。这种模型使用过程中会造成大量的join,维护成本高,性能方面也较差,所以一般不建议使用。尤其是基于hadoop体系构建数仓,减少join就是减少shuffle,性能差距会很大。
4.Hive优化
4.1.Hive造成性能低下下的根源
Hive是hadoop生态下的组件,HiveQL本质上是格式化数据的MapReduce,即从MapReduce的运行角度来考虑优化性能,从更底层思考如何优化运算性能,而不仅仅局限于逻辑代码层面。所以利用Hive处理数据有以下几个显著特征:
1>.数据的大规模并不是负载重点,造成运行压力过大是因为运行数据的倾斜。
2>.jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联对此汇总,产生几十个jobs,将会很多时间且大部分时间被用于作业分配,初始化和数据输出。MapReduce作业初始化的时间是比较耗时间资源的一个部分。
3>.在使用SUM,COUNT,MAX,MIN等UDAF函数时,不怕数据倾斜问题,Hadoop在Map端的汇总合并优化过,使数据倾斜不成问题。
4>.COUNT(DISTINCT)在数据量大的情况下,效率较低,如果多COUNT(DISTINCT)效率更低,因为COUNT(DISTINCT)是按GROUP BY字段分组,按DISTINCT字段排序,一般这种分布式方式是很倾斜的;比如:男UV,女UV,淘宝一天30亿的PV,如果按性别分组,分配2个reduce,每个reduce处理15亿数据。
5>.数据倾斜是导致效率大幅降低的主要原因,可以采用多一次 Map/Reduce 的方法, 避免倾斜。
4.2.配置角度优化
Hive作为一个成熟的组件,在配置上自然提供了一些优化参数。Hive系统内部已针对不同的查询预设定了优化方法,用户可以通过调整配置进行控制,以下举例介绍部分优化的策略以及优化控制选项。
1>.列裁剪
Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其它列。例如,若有以下查询:
SELECT a,b FROM q WHERE e<10;在实施此项查询中,Q 表有 5 列(a,b,c,d,e),Hive 只读取查询逻辑中真实需要 的 3 列 a、b、e,而忽略列 c,d;这样做节省了读取开销,中间表存储开销和数据整合开销。
裁剪所对应的参数项为:hive.optimize.cp=true(默认值为真)
2>.分区裁剪
可以在查询的过程中减少不必要的分区。例如,若有以下查询:
SELECT * FROM (SELECTT a1,COUNT(1) FROM T GROUP BY a1) subq WHERE subq.prtn=100; #(多余分区)
SELECT * FROM T1 JOIN (SELECT * FROM T2) subq ON (T1.a1=subq.a2) WHERE subq.prtn=100;查询语句若将“subq.prtn=100”条件放入子查询中更为高效,可以减少读入的分区 数目。Hive自动执行这种裁剪优化。
分区参数为:hive.optimize.pruner=true(默认值为真)
3>Join操作
a.Join操作原则:
在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在 Join 操作符的左边。原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率。对于一条语句中有多个 Join 的情况,如果 Join 的条件相同,比如查询:
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x ON (u.userid = x.userid);如果Join的key相同,不管有多少个表,都会则会合并为一个Map-Reduce,一个Map-Reduce任务,而不是n个,在做OUTER JOIN的时候也是一样
如果 Join 的条件不相同,比如:
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x on (u.age = x.age);Map-Reduce的任务数目和Join操作的数目是对应的,上述查询和以下查询是等价的:
INSERT OVERWRITE TABLE tmptable
SELECT * FROM page_view p JOIN user u
ON (pv.userid = u.userid);
INSERT OVERWRITE TABLE pv_users
SELECT x.pageid, x.age FROM tmptable x
JOIN newuser y ON (x.age = y.age);b.MAP JOIN
Join操作在Map阶段完成,不再需要Reduce,前提条件是需要的数据在 Map 的过程中可以访问到。比如查询:
INSERT OVERWRITE TABLE pv_users
SELECT /*+ MAPJOIN(pv) */ pv.pageid, u.age
FROM page_view pv
JOIN user u ON (pv.userid = u.userid);可以在Map阶段完成Join
相关的参数为:
hive.join.emit.interval = 1000
hive.mapjoin.size.key = 10000
hive.mapjoin.cache.numrows = 10000
c.GROUP BY
进行GROUP BY操作时需要注意一下几点:
Map端部分聚合
事实上并不是所有的聚合操作都需要在reduce部分进行,很多聚合操作都可以先在Map端进行部分聚合,然后reduce端得出最终结果。
这里需要修改的参数为:
hive.map.aggr=true(用于设定是否在 map 端进行聚合,默认值为真)
hive.groupby.mapaggr.checkinterval=100000(用于设定 map 端进行聚合操作的条目数)
有数据倾斜时进行负载均衡:
此处需要设定hive.groupby.skewindata,当选项设定为 true 是,生成的查询计划有两个MapReduce任务。在第一个MapReduce中,map的输出结果集合会随机分布到reduce中,每个reduce 做部分聚合操作,并输出结果。这样处理的结果是,相同的Group By Key有可能分发到不同的reduce中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处 理的数据结果按照 Group By Key 分布到 reduce 中(这个过程可以保证相同的 Group By Key 分布到同一个 reduce 中),最后完成最终的聚合操作。
d.合并小文件
我们知道文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,影响处理效率。对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。
用于设置合并属性的参数有:
是否合并Map输出文件:hive.merge.mapfiles=true(默认值为真)
是否合并Reduce端输出文件:hive.merge.mapredfiles=false(默认值为假)
合并文件的大小:hive.merge.size.per.task=256*1000*1000(默认值为 256000000)
4.3.SQL语句的优化
熟练地使用 SQL,能写出高效率的查询语句。
1>.场景
有一张 user 表,为卖家每天收到表,user_id,ds(日期)为 key,属性有主营类目,指标有交易金额,交易笔数。每天要取前10天的总收入,总笔数,和最近一天的主营类目。
2>.解决方法1
如下所示:常用方法
INSERT OVERWRITE TABLE t1
SELECT user_id,substr(MAX(CONCAT(ds,cat),9) AS main_cat) FROM users
WHERE ds=20120329 // 20120329 为日期列的值,实际代码中可以用函数表示出当天日期 GROUP BY user_id;
INSERT OVERWRITE TABLE t2
SELECT user_id,sum(qty) AS qty,SUM(amt) AS amt FROM users
WHERE ds BETWEEN 20120301 AND 20120329
GROUP BY user_id
SELECT t1.user_id,t1.main_cat,t2.qty,t2.amt FROM t1
JOIN t2 ON t1.user_id=t2.user_id下面给出方法1的思路,实现步骤如下:
第一步:利用分析函数,取每个user_id最近一天的主营类目,存入临时表t1。
第二步:汇总10天的总交易金额,交易笔数,存入临时表 t2。
第三步:关联t1 t2得到最终的结果。
3>.解决方法2
如下所示:优化方法
SELECT user_id,substr(MAX(CONCAT(ds,cat)),9) AS main_cat,SUM(qty),SUM(amt) FROM users
WHERE ds BETWEEN 20120301 AND 20120329
GROUP BY user_id在工作中我们总结出:
方案 2 的开销等于方案 1 的第二步的开销,性能提升,由原有的 25 分钟完成,缩短为 10 分钟以内完成。节省了两个临时表的读写是一个关键原因,这种方式也适用于 Oracle 中的数据查找工作。
SQL具有普遍性,很多 SQL 通用的优化方案在 Hadoop 分布式计算方式中也可以达到效果。
4>.无效ID在关联时的数据倾斜问题
问题:日志中常会出现信息丢失,比如每日约为 20 亿的全网日志,其中的 user_id 为主键,在日志收集过程中会丢失,出现主键为null的情况,如果取其中的user_id和bmw_users 关联,就会碰到数据倾斜的问题。原因是Hive中,主键为null值的项会被当做相同的Key而分配进同一个计算Map。
解决方法1:user_id 为空的不参与关联,子查询过滤 null
SELECT * FROM log a
JOIN bmw_users b ON a.user_id IS NOT NULL AND a.user_id=b.user_id
UNION All SELECT * FROM log a WHERE a.user_id IS NULL解决方法2 如下所示:函数过滤 null
SELECT * FROM log a LEFT OUTER
JOIN bmw_users b ON
CASE WHEN a.user_id IS NULL THEN CONCAT(‘dp_hive’,RAND()) ELSE a.user_id END =b.user_id;这个优化适合无效 id(比如-99、 ‘’,null 等)产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的 数据分到不同的Reduce上,从而解决数据倾斜问题。因为空值不参与关联,即使分到不同 的 Reduce 上,也不会影响最终的结果。附上 Hadoop 通用关联的实现方法是:关联通过二次排序实现的,关联的列为 partion key,关联的列和表的 tag 组成排序的 group key,根据 pariton key分配Reduce。同一Reduce内根据group key排序。
5.Hbase优化
Hbase在大数据中通过唯一标识key找数据的场景是很常用的,而这种场景也是很多的。另外Hbase对于超大数据的存储和超大数据下单条数据命中上也是支持很好的。所以对于Hbase的优化也是非常有必要的。Hbase的优化主要分为以下几个方面:
1>.表的设计优化
2>.写表操作优化
3>.读表操作优化
接下来将从以上三个方面给出具体的优化方案
5.1.表的设计优化
5.1.1.预分区
默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。如下通过Java API写预先创建Regions的代码示例
public static boolean createTable(HBaseAdmin admin, HTableDescriptor table, byte[][] splits)
throws IOException {
try {
admin.createTable(table, splits);
return true;
} catch (TableExistsException e) {
logger.info("table " + table.getNameAsString() + " already exists");
// the table already exists...
return false;
}
}
public static byte[][] getHexSplits(String startKey, String endKey, int numRegions) { //start:001,endkey:100,10region [001,010]
[011,020]
byte[][] splits = new byte[numRegions-1][];
BigInteger lowestKey = new BigInteger(startKey, 16);
BigInteger highestKey = new BigInteger(endKey, 16);
BigInteger range = highestKey.subtract(lowestKey);
BigInteger regionIncrement = range.divide(BigInteger.valueOf(numRegions));
lowestKey = lowestKey.add(regionIncrement);
for(int i=0; i < numRegions-1;i++) {
BigInteger key = lowestKey.add(regionIncrement.multiply(BigInteger.valueOf(i)));
byte[] b = String.format("%016x", key).getBytes();
splits[i] = b;
}
return splits;
}5.1.2.Row Key设计
HBase中row key用来检索表中的记录,支持以下三种方式:
通过单个row key访问:即按照某个row key键值进行get操作;
通过row key的range进行scan:即通过设置startRowKey和endRowKey,在这个范围内进行扫描;
全表扫描:即直接扫描整张表中所有行记录。
在HBase中,row key可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,存为byte[]字节数组,一般设计成定长的。
row key是按照字典序存储,因此,设计row key时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
举个例子:如果最近写入HBase表中的数据是最可能被访问的,可以考虑将时间戳作为row key的一部分,由于是字典序排序,所以可以使用Long.MAX_VALUE - timestamp作为row key,这样能保证新写入的数据在读取时可以被快速命中。
Rowkey规则:
1>.越小越好
2>.Rowkey的设计是要根据实际业务来
3>.散列性
取反001 002 100 200
Hash
5.1.3.列族的设计
不要在一张表里定义太多的column family。目前Hbase并不能很好的处理超过2~3个column family的表。因为某个column family在flush的时候,它邻近的column family也会因关联效应被触发flush,最终导致系统产生更多的I/O。在实际开发中,为了规避这一点往往将多个列簇字段拼接成一个列簇。
5.1.4.In Memory
创建表的时候,可以通过HColumnDescriptor.setInMemory(true)将表放到RegionServer的缓存中,保证在读取的时候被cache命中。(读缓存)
5.1.5.Max Version
创建表的时候,可以通过HColumnDescriptor.setMaxVersions(int maxVersions)设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置setMaxVersions(1)。
5.1.6.Time To Live
创建表的时候,可以通过HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么可以设置setTimeToLive(2 * 24 * 60 * 60)。(相当于Linux中的Crontab任务)
5.1.7.Compact & Split
在HBase中,数据在更新时首先写入WAL 日志(HLog)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。于此同时, 系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了(minor compact)。
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并(major compact),将对同一个key的修改合并到一起,形成一个大的StoreFile,当StoreFile的大小达到一定阈值后,又会对 StoreFile进行分割(split),等分为两个StoreFile。
由于对表的更新是不断追加的,处理读请求时,需要访问Store中全部的StoreFile和MemStore,将它们按照row key进行合并,由于StoreFile和MemStore都是经过排序的,并且StoreFile带有内存中索引,通常合并过程还是比较快的。
实际应用中,可以考虑必要时手动进行major compact,将同一个row key的修改进行合并形成一个大的StoreFile。同时,可以将StoreFile设置大些,减少split的发生。
hbase为了防止小文件(被刷到磁盘的menstore)过多,以保证保证查询效率,hbase需要在必要的时候将这些小的store file合并成相对较大的store file,这个过程就称之为compaction。在hbase中,主要存在两种类型的compaction:minor compaction和major compaction。
minor compaction:的是较小、很少文件的合并。
major compaction 的功能是将所有的store file合并成一个,触发major compaction的可能条件有:major_compact 命令、majorCompact() API、region server自动运行(相关参数:hbase.hregion.majoucompaction 默认为24 小时、hbase.hregion.majorcompaction.jetter 默认值为0.2 防止region server 在同一时间进行major compaction)。
hbase.hregion.majorcompaction.jetter参数的作用是:对参数hbase.hregion.majoucompaction 规定的值起到浮动的作用,假如两个参数都为默认值24和0,2,那么major compact最终使用的数值为:19.2~28.8 这个范围。实际开发中可以关闭自动major compaction,手动编写major compaction,如下参考:
Timer类,contab
minor compaction的运行机制要复杂一些,它由一下几个参数共同决定:
hbase.hstore.compaction.min :默认值为 3,表示至少需要三个满足条件的store file时,minor compaction才会启动
hbase.hstore.compaction.max 默认值为10,表示一次minor compaction中最多选取10个store file
hbase.hstore.compaction.min.size 表示文件大小小于该值的store file 一定会加入到minor compaction的store file中
hbase.hstore.compaction.max.size 表示文件大小大于该值的store file 一定会被minor compaction排除
hbase.hstore.compaction.ratio 将store file 按照文件年龄排序(older to younger),minor compaction总是从older store file开始选择
5.2.写表操作优化
5.2.1.多HTable并发写
创建多个HTable客户端用于写操作,提高写数据的吞吐量,一个例子:
static final Configuration conf = HBaseConfiguration.create();
static final String table_log_name = “user_log”;
wTableLog = new HTable[tableN];
for (int i = 0; i < tableN; i++) {
wTableLog[i] = new HTable(conf, table_log_name);
wTableLog[i].setWriteBufferSize(5 * 1024 * 1024); //5MB
wTableLog[i].setAutoFlush(false);5.2.2.HTable参数设置
aAuto Flush
通过调用HTable.setAutoFlush(false)方法可以将HTable写客户端的自动flush关闭,这样可以批量写入数据到HBase,而不是有一条put就执行一次更新,只有当put填满客户端写缓存时,才实际向HBase服务端发起写请求。默认情况下auto flush是开启的。
b.Write Buffer
通过调用HTable.setWriteBufferSize(writeBufferSize)方法可以设置HTable客户端的写buffer大小,如果新设置的buffer小于当前写buffer中的数据时,buffer将会被flush到服务端。其中,writeBufferSize的单位是byte字节数,可以根据实际写入数据量的多少来设置该值。
c.WAL Flag(慎用除非导入测试数据)
在HBae中,客户端向集群中的RegionServer提交数据时(Put/Delete操作),首先会先写WAL(Write Ahead Log)日志(即HLog,一个RegionServer上的所有Region共享一个HLog),只有当WAL日志写成功后,再接着写MemStore,然后客户端被通知提交数据成功;如果写WAL日志失败,客户端则被通知提交失败。这样做的好处是可以做到RegionServer宕机后的数据恢复。
因此,对于相对不太重要的数据,可以在Put/Delete操作时,通过调用Put.setWriteToWAL(false)或Delete.setWriteToWAL(false)函数,放弃写WAL日志,从而提高数据写入的性能。
值得注意的是:谨慎选择关闭WAL日志,因为这样的话,一旦RegionServer宕机,Put/Delete的数据将会无法根据WAL日志进行恢复。
5.2.3.批量写
通过调用HTable.put(Put)方法可以将一个指定的row key记录写入HBase,同样HBase提供了另一个方法:通过调用HTable.put(List
5.2.3.多线程并发写
在客户端开启多个HTable写线程,每个写线程负责一个HTable对象的flush操作,这样结合定时flush和写buffer(writeBufferSize),可以既保证在数据量小的时候,数据可以在较短时间内被flush(如1秒内),同时又保证在数据量大的时候,写buffer一满就及时进行flush。下面给个具体的例子:
for (int i = 0; i < threadN; i++) {
Thread th = new Thread() {
public void run() {
while (true) {
try {
sleep(1000); //1 second
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (wTableLog[i]) {
try {
wTableLog[i].flushCommits();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
};
th.setDaemon(true);
th.start();
}当然这种多线程并发写在Hadoop体现下就没必要了
5.3.读表操作优化
5.3.1.HTable参数设置
a.Scanner Caching
hbase.client.scanner.caching配置项可以设置HBase scanner一次从服务端抓取的数据条数,默认情况下一次一条。通过将其设置成一个合理的值,可以减少scan过程中next()的时间开销,代价是scanner需要通过客户端的内存来维持这些被cache的行记录。有三个地方可以进行配置:
1>.在HBase的conf配置文件中进行配置;(一般不用该全局配置)
2>.通过调用HTable.setScannerCaching(int scannerCaching)进行配置
3>.通过调用Scan.setCaching(int caching)进行配置。三者的优先级越来越高。
b.Scan Attribute Selection
scan时指定需要的Column Family,可以减少网络传输数据量,否则默认scan操作会返回整行所有Column Family的数据。
c.Close ResultScanner
通过scan取完数据后,记得要关闭ResultScanner,否则RegionServer可能会出现问题(对应的Server资源无法释放)。
5.3.2.批量读
通过调用HTable.get(Get)方法可以根据一个指定的row key获取一行记录,同样HBase提供了另一个方法:通过调用HTable.get(List<Get>)方法可以根据一个指定的row key列表,批量获取多行记录,这样做的好处是批量执行,只需要一次网络I/O开销,这对于对数据实时性要求高而且网络传输RTT高的情景下可能带来明显的性能提升。
5.3.3.多线程并发读
在客户端开启多个HTable读线程,每个读线程负责通过HTable对象进行get操作。当然这种多线程并发写在Hadoop体现下就没必要了,下面是一个多线程并发读取HBase,获取店铺一天内各分钟PV值的例子
public class DataReaderServer {
//获取店铺一天内各分钟PV值的入口函数
public static ConcurrentHashMap<String, String> getUnitMinutePV(long uid, long startStamp, long endStamp){
long min = startStamp;
int count = (int)((endStamp - startStamp) / (60*1000));
List<String> lst = new ArrayList<String>();
for (int i = 0; i <= count; i++) {
min = startStamp + i * 60 * 1000;
lst.add(uid + "_" + min);
}
return parallelBatchMinutePV(lst);
}
//多线程并发查询,获取分钟PV值
private static ConcurrentHashMap<String, String> parallelBatchMinutePV(List<String> lstKeys){
ConcurrentHashMap<String, String> hashRet = new ConcurrentHashMap<String, String>();
int parallel = 3;
List<List<String>> lstBatchKeys = null;
if (lstKeys.size() < parallel ){
lstBatchKeys = new ArrayList<List<String>>(1);
lstBatchKeys.add(lstKeys);
}
else{
lstBatchKeys = new ArrayList<List<String>>(parallel);
for(int i = 0; i < parallel; i++ ){
List<String> lst = new ArrayList<String>();
lstBatchKeys.add(lst);
}
for(int i = 0 ; i < lstKeys.size() ; i ++ ){
lstBatchKeys.get(i%parallel).add(lstKeys.get(i));
}
}
List<Future< ConcurrentHashMap<String, String> >> futures = new ArrayList<Future< ConcurrentHashMap<String, String> >>(5);
ThreadFactoryBuilder builder = new ThreadFactoryBuilder();
builder.setNameFormat("ParallelBatchQuery");
ThreadFactory factory = builder.build();
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(lstBatchKeys.size(), factory);
for(List<String> keys : lstBatchKeys){
Callable< ConcurrentHashMap<String, String> > callable = new BatchMinutePVCallable(keys);
FutureTask< ConcurrentHashMap<String, String> > future = (FutureTask< ConcurrentHashMap<String, String> >) executor.submit(callable);
futures.add(future);
}
executor.shutdown();
// Wait for all the tasks to finish
try {
boolean stillRunning = !executor.awaitTermination(
5000000, TimeUnit.MILLISECONDS);
if (stillRunning) {
try {
executor.shutdownNow();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (InterruptedException e) {
try {
Thread.currentThread().interrupt();
} catch (Exception e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
// Look for any exception
for (Future f : futures) {
try {
if(f.get() != null)
{
hashRet.putAll((ConcurrentHashMap<String, String>)f.get());
}
} catch (InterruptedException e) {
try {
Thread.currentThread().interrupt();
} catch (Exception e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
} catch (ExecutionException e) {
e.printStackTrace();
}
}
return hashRet;
}
//一个线程批量查询,获取分钟PV值
protected static ConcurrentHashMap<String, String> getBatchMinutePV(List<String> lstKeys){
ConcurrentHashMap<String, String> hashRet = null;
List<Get> lstGet = new ArrayList<Get>();
String[] splitValue = null;
for (String s : lstKeys) {
splitValue = s.split("_");
long uid = Long.parseLong(splitValue[0]);
long min = Long.parseLong(splitValue[1]);
byte[] key = new byte[16];
Bytes.putLong(key, 0, uid);
Bytes.putLong(key, 8, min);
Get g = new Get(key);
g.addFamily(fp);
lstGet.add(g);
}
Result[] res = null;
try {
res = tableMinutePV[rand.nextInt(tableN)].get(lstGet);
} catch (IOException e1) {
logger.error("tableMinutePV exception, e=" + e1.getStackTrace());
}
if (res != null && res.length > 0) {
hashRet = new ConcurrentHashMap<String, String>(res.length);
for (Result re : res) {
if (re != null && !re.isEmpty()) {
try {
byte[] key = re.getRow();
byte[] value = re.getValue(fp, cp);
if (key != null && value != null) {
hashRet.put(String.valueOf(Bytes.toLong(key,
Bytes.SIZEOF_LONG)), String.valueOf(Bytes
.toLong(value)));
}
} catch (Exception e2) {
logger.error(e2.getStackTrace());
}
}
}
}
return hashRet;
}
}
//调用接口类,实现Callable接口
class BatchMinutePVCallable implements Callable<ConcurrentHashMap<String, String>>{
private List<String> keys;
public BatchMinutePVCallable(List<String> lstKeys ) {
this.keys = lstKeys;
}
public ConcurrentHashMap<String, String> call() throws Exception {
return DataReadServer.getBatchMinutePV(keys);
}
5.3.4.缓存查询结果
对于频繁查询HBase的应用场景,可以考虑在应用程序中做缓存,当有新的查询请求时,首先在缓存中查找,如果存在则直接返回,不再查询HBase;否则对HBase发起读请求查询,然后在应用程序中将查询结果缓存起来。至于缓存的替换策略,可以考虑LRU等常用的策略。
5.3.5.Blockcache设置读缓存,在服务器端
HBase上Regionserver的内存分为两个部分,一部分作为Memstore,主要用来写;另外一部分作为BlockCache,主要用于读。
写请求会先写入Memstore,Regionserver会给每个region提供一个Memstore,当Memstore满64MB以后,会启动 flush刷新到磁盘。当Memstore的总大小超过限制时(heapsize * hbase.regionserver.global.memstore.upperLimit * 0.9),会强行启动flush进程,从最大的Memstore开始flush直到低于限制。
读请求先到Memstore中查数据,查不到就到BlockCache中查,再查不到就会到磁盘上读,并把读的结果放入BlockCache。由于BlockCache采用的是LRU策略,因此BlockCache达到上限(heapsize * hfile.block.cache.size * 0.85)后,会启动淘汰机制,淘汰掉最老的一批数据。
一个Regionserver上有一个BlockCache和N个Memstore,它们的大小之和不能大于等于heapsize * 0.8,否则HBase不能启动。默认BlockCache为0.2,而Memstore为0.4。对于注重读响应时间的系统,可以将 BlockCache设大些,比如设置BlockCache=0.4,Memstore=0.39,以加大缓存的命中率。