临界区
所谓临界区就是访问和操作共享数据的代码段。多个执行线程并发访问同一个资源通常是不安全的,为了避免在临界区中并发访问,编程者必须保证这些代码原子的执行——也就是说,操作在执行结束前不可被打断,就如同临界区是一个不可分割的指令一样。
竞争
如果两个执行线程有可能处于同一个临界区中执行,那么这就是程序的一个Bug,如果这种情况确实发生了,我们就称它为竞争条件。
同步
避免并发和防止竞争条件称为同步。
内核同步的手段——加锁
它如同一把门锁,门后的房间可以想象成一个临界区,在指定的时间内,房间里只有一个执行线程可以执行,当它访问完共享数据时,走出房间打开门锁。
锁本身是通过原子操作实现的,原子操作不存在竞争。
内核中有可能造成并发执行的原因
中断随时会发生,也就会随时打断当前执行的代码。如果中断和被打断的代码在相同的临界区,就产生了竞争条件
软中断和tasklet也会随时被内核唤醒执行,也会像中断一样打断正在执行的代码
内核具有抢占性,发生抢占时,如果抢占的线程和被抢占的线程在相同的临界区,就产生了竞争条件
用户进程睡眠后,调度程序会唤醒一个新的用户进程,新的用户进程和睡眠的进程可能在同一个临界区中
对称多处理,2个或多个处理器可以同时执行相同的代码
哪些数据需要保护
执行线程的局部数据仅仅被它本身所访问,显然不需要保护,比如,局部自动变量(还有动态分配的数据结构,其结构存放在堆栈中)不需要任何形式的锁。类似的,如果数据只被特定的进程访问,那么要不需要加锁(因为进程一次只在一个处理器上执行)。
到底什么数据需要加锁?大多数内核数据结构都需要加锁!有一条很好的经验可以帮助我们判断:如果有其它执行线程可以访问这些数据,那么就给这些数据加上某种形式的锁;如果任何什么东西都能看到它,那么就要锁住它。记住:要给数据而不是给代码加锁。
在编写内核代码时,你要问自己下面这些问题
这个数据是不是全局的?除了当前线程以外,其他线程能不能访问它?
这个数据会不会在进程上下文或者中断上下文中共享?它是不是要在两个不同的中断处理程序中共享?
进程在访问数据时可不可能被抢占?被调度的新程序会不会访问同一数据?
当前进程会不会睡眠(或者阻塞)在某些资源上,如果是,它会让共享数据处于何种状态?
怎样防止数据失控?
如果这个函数又在另一个处理器上被调度将会发生什么?
死锁
死锁就是所有线程都在相互等待释放资源,导致谁也无法继续执行下去。
下面一些简单的规则可以帮助我们避免死锁
如果有多个锁的话,尽量确保每个线程都是按相同的顺序加锁,按加锁相反的顺序解锁。(即加锁a->b->c,解锁c->b->a)
防止发生饥饿。即设置一个超时时间,防止一直等待下去。
不要重复请求同一个锁。
设计应力求简单。加锁的方案越复杂就越容易出现死锁。
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-833878f763.css">
<div id="content_views" class="markdown_views">
<!-- flowchart 箭头图标 勿删 -->
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;">
<path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path>
</svg>
<h2 id="原子操作"><a name="t0"></a><a name="t0"></a>原子操作</h2>
原子正数操作
定义一个 atomic_t 类型的数据方法很平常,你还可以在定义它时给它设定初值:
atomic_t v; //定义v
atomic_t u = ATOMIC_INIT(0); //定义u并把它初始化为0
atomic_set(&v, 4); //v = 4
atomic_add(2, &v); //v = v + 2
atomic_inc(&v); //v = v + 1
- 1
- 2
- 3
- 4
- 5
还可以用原子整数操作原子地执行一个操作并检查结果,一个常见的例子就是:
int atomic_dec_and_test(atomic_t *v);
- 1

原子位操作
由于原子位操作是对普通的指针进行的操作,所以不像原子整数操作类型对应 atomic_t ,这里没有特殊的数据类型。
unsigned long word = 0;
set_bit(0, &word); //设置第0位
set_bit(1, &word); //设置第1位
clear_bit(1, &word); //清空第1位
change_bit(0, &word); //翻转第0位
//原子地设置第0位并返回设置之前的值
if (test_and_set_bit(0, &word)){
}
word = 7;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
自旋锁
spin lock的特点
我们可以总结spin lock的特点如下:
- spin lock是一种死等的锁机制。当发生访问资源冲突的时候,可以有两个选择:一个是死等,一个是挂起当前进程,调度其他进程执行。spin lock是一种死等的机制,当前的执行thread会不断的重新尝试直到获取锁进入临界区。
- 只允许一个thread进入。semaphore可以允许多个thread进入,spin lock不行,一次只能有一个thread获取锁并进入临界区,其他的thread都是在门口不断的尝试。
- 执行时间短。由于spin lock死等这种特性,因此它使用在那些代码不是非常复杂的临界区(当然也不能太简单,否则使用原子操作或者其他适用简单场景的同步机制就OK了),如果临界区执行时间太长,那么不断在临界区门口“死等”的那些thread是多么的浪费CPU啊(当然,现代CPU的设计都会考虑同步原语的实现,例如ARM提供了WFE和SEV这样的类似指令,避免CPU进入busy loop的悲惨境地)
- 可以在中断上下文执行。由于不睡眠,因此spin lock可以在中断上下文中适用。
场景分析
对于spin lock,其保护的资源可能来自多个CPU CORE上的进程上下文和中断上下文的中的访问:
- 用户进程通过系统调用访问,内核线程直接访问,来自workqueue中work function的访问(本质上也是内核线程)。
- 中断上下文包括:HW interrupt context(中断handler)、软中断上下文(soft irq,当然由于各种原因,该softirq被推迟到softirqd的内核线程中执行的时候就不属于这个场景了,属于进程上下文那个分类了)、timer的callback函数(本质上也是softirq)、tasklet(本质上也是softirq)。
先看最简单的单CPU上的进程上下文的访问。如果一个全局的资源被多个进程上下文访问,这时候,内核如何交错执行呢?对于那些没有打开preemptive选项的内核,所有的系统调用都是串行化执行的,因此不存在资源争抢的问题。如果内核线程也访问这个全局资源呢?本质上内核线程也是进程,类似普通进程,只不过普通进程时而在用户态运行、时而通过系统调用陷入内核执行,而内核线程永远都是在内核态运行,但是,结果是一样的,对于non-preemptive的linux kernel,只要在内核态,就不会发生进程调度,因此,这种场景下,共享数据根本不需要保护(没有并发,谈何保护呢)。如果时间停留在这里该多么好,单纯而美好,在继续前进之前,让我们先享受这一刻。
当打开premptive选项后,事情变得复杂了,我们考虑下面的场景:
- 进程A在某个系统调用过程中访问了共享资源R
- 进程B在某个系统调用过程中也访问了共享资源R
会不会造成冲突呢?假设在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,在中断返回现场的时候,发生进程切换,B启动执行,并通过系统调用访问了R,如果没有锁保护,则会出现两个thread进入临界区,导致程序执行不正确。
OK,我们加上spin lock看看如何:A在进入临界区之前获取了spin lock,同样的,在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,B在访问临界区之前仍然会试图获取spin lock,这时候由于A进程持有spin lock而导致B进程进入了永久的spin……怎么破?linux的kernel很简单,在A进程获取spin lock的时候,禁止本CPU上的抢占(上面的永久spin的场合仅仅在本CPU的进程抢占本CPU的当前进程这样的场景中发生)。如果A和B运行在不同的CPU上,那么情况会简单一些:A进程虽然持有spin lock而导致B进程进入spin状态,不过由于运行在不同的CPU上,A进程会持续执行并会很快释放spin lock,解除B进程的spin状态。
多CPU core的场景和单核CPU打开preemptive选项的效果是一样的,这里不再赘述。
我们继续向前分析,现在要加入中断上下文这个因素。访问共享资源的thread包括:
- 运行在CPU0上的进程A在某个系统调用过程中访问了共享资源R
- 运行在CPU1上的进程B在某个系统调用过程中也访问了共享资源R
- 外设P的中断handler中也会访问共享资源R
在这样的场景下,使用spin lock可以保护访问共享资源R的临界区吗?我们假设CPU0上的进程A持有spin lock进入临界区,这时候,外设P发生了中断事件,并且调度到了CPU1上执行,看起来没有什么问题,执行在CPU1上的handler会稍微等待一会CPU0上的进程A,等它立刻临界区就会释放spin lock的,但是,如果外设P的中断事件被调度到了CPU0上执行会怎么样?CPU0上的进程A在持有spin lock的状态下被中断上下文抢占,而抢占它的CPU0上的handler在进入临界区之前仍然会试图获取spin lock,悲剧发生了,CPU0上的P外设的中断handler永远的进入spin状态,这时候,CPU1上的进程B也不可避免在试图持有spin lock的时候失败而导致进入spin状态。为了解决这样的问题,linux kernel采用了这样的办法:如果涉及到中断上下文的访问,spin lock需要和禁止本CPU上的中断联合使用。
linux kernel中提供了丰富的bottom half的机制,虽然同属中断上下文,不过还是稍有不同。我们可以把上面的场景简单修改一下:外设P不是中断handler中访问共享资源R,而是在的bottom half中访问。使用spin lock+禁止本地中断当然是可以达到保护共享资源的效果,但是使用牛刀来杀鸡似乎有点小题大做,这时候disable bottom half就OK了。
最后,我们讨论一下中断上下文之间的竞争。同一种中断handler之间在uni core和multi core上都不会并行执行,这是linux kernel的特性。如果不同中断handler需要使用spin lock保护共享资源,对于新的内核(不区分fast handler和slow handler),所有handler都是关闭中断的,因此使用spin lock不需要关闭中断的配合。bottom half又分成softirq和tasklet,同一种softirq会在不同的CPU上并发执行,因此如果某个驱动中的sofirq的handler中会访问某个全局变量,对该全局变量是需要使用spin lock保护的,不用配合disable CPU中断或者bottom half。tasklet更简单,因为同一种tasklet不会多个CPU上并发,具体我就不分析了,大家自行思考吧。
综上所述,进程和进程间的数据共享:
单核:支持抢占的情况下,使用自旋锁会禁止抢占,自旋锁没有起到“自旋”的作用,因此此时根本不会发生竞争。
多核:首先,多核可以真正意义上的并发执行,使用自旋锁可以让不同cpu上的进程访问共享数据时进行自旋等待,同时持有锁会禁止该核上的抢占。
进程和底半部(softirq tasklet)间的数据共享:
个人认为进程——下半部间的数据共享和进程——进程之间的数据共享是一样的,因为持有自旋锁的情况下 preempt_count 非0,preempt_count 非0的情况下,不但禁止了抢占,底半部也是被禁止的。但书上说,这种情况下常用的做法是,先获得一个锁,再禁止底半部,有些疑问,待解答。
进程和硬中断间的数据共享:
进程在访问共享数据前先获得一把自旋锁,在这种情况下,高优先级抢占和底半部是被禁止了,但是中断可能随时到来,如果中断处理函数中去试图获得同一把锁,如果不在同一个cpu上就需要锁来保护,如果在同一个cpu上发生就会造成死锁,因此要获得锁之前禁止本地中断。常用的做法是,当一个进程持有一把锁之前,先禁止本地中断。
底半部之间的数据共享:
softirq——softirq:同一种softirq会在不同的CPU上并发执行,因此如果某个驱动中的sofirq的handler中会访问某个全局变量,对该全局变量是需要使用spin lock保护的,不用配合disable CPU中断或者bottom half.这里使用自旋锁的目的个人觉得是持有锁导致禁止了底半部,而不是竞争时“自旋”。
tasklet——tasklet:相同类型的tasklet不会并发执行,因此无需保护。
softirq——tasklet:多核的情况下会并发执行,需要自旋锁保护。
底半部和硬中断之间的数据共享:
唯一可以中断底半部的就是硬中断,这和进程——硬中断共享数据的情况是一样的,常用的做法是,当一个底半部持有一把锁之前,先禁止本地中断。
硬中断之间的数据共享:
同一种中断handler之间在uni core和multi core上都不会并行执行,这是linux kernel的特性。
如果不同中断handler需要使用spin lock保护共享资源,对于新的内核(不区分fast handler和slow handler),所有handler都是关闭中断的,因此使用spin lock不需要关闭中断的配合。老的内核需要使用spin lock之前先禁止本地处理器上的中断。
自旋锁方法列表如下:
spin_lock() 获取指定的自旋锁
spin_lock_irq() 禁止本地中断并获取指定的锁
spin_lock_irqsave() 保存本地中断的当前状态,禁止本地中断,并获取指定的锁
spin_unlock() 释放指定的锁
spin_unlock_irq() 释放指定的锁,并激活本地中断
spin_unlock_irqstore() 释放指定的锁,并让本地中断恢复到以前状态
spin_lock_init() 动态初始化指定的spinlock_t
spin_trylock() 试图获取指定的锁,如果未获取,则返回0
spin_is_locked() 如果指定的锁当前正在被获取,则返回非0,否则返回0
读写自旋锁
读写自旋锁除了和普通自旋锁一样有自旋特性以外,还有以下特点:
- 读锁之间是共享的,即一个线程持有了读锁之后,其他线程也可以以读的方式持有这个锁
- 写锁之间是互斥的,即一个线程持有了写锁之后,其他线程不能以读或者写的方式持有这个锁
- 读写锁之间是互斥的,即一个线程持有了读锁之后,其他线程不能以写的方式持有这个锁
注:读写锁要分别使用,不能混合使用,否则会造成死锁。
正常的使用方法:
DEFINE_RWLOCK(mr_rwlock);
read_lock(&mr_rwlock);
/* 临界区(只读).... */
read_unlock(&mr_rwlock);
write_lock(&mr_lock);
/* 临界区(读写)... */
write_unlock(&mr_lock);
混合使用时:
/* 获取一个读锁 */
read_lock(&mr_lock);
/* 在获取写锁的时候,由于读写锁之间是互斥的,
* 所以写锁会一直自旋等待读锁的释放,
* 而此时读锁也在等待写锁获取完成后继续下面的代码。
* 因此造成了读写锁的互相等待,形成了死锁。
*/
write_lock(&mr_lock);
读写锁相关文件参照 各个体系结构中的
read_lock() 获取指定的读锁
read_lock_irq() 禁止本地中断并获得指定读锁
read_lock_irqsave() 存储本地中断的当前状态,禁止本地中断并获得指定读锁
read_unlock() 释放指定的读锁
read_unlock_irq() 释放指定的读锁并激活本地中断
read_unlock_irqrestore() 释放指定的读锁并将本地中断恢复到指定前的状态
write_lock() 获得指定的写锁
write_lock_irq() 禁止本地中断并获得指定写锁
write_lock_irqsave() 存储本地中断的当前状态,禁止本地中断并获得指定写锁
write_unlock() 释放指定的写锁
write_unlock_irq() 释放指定的写锁并激活本地中断
write_unlock_irqrestore() 释放指定的写锁并将本地中断恢复到指定前的状态
write_trylock() 试图获得指定的写锁;如果写锁不可用,返回非0值
rwlock_init() 初始化指定的rwlock_t
信号量
信号量也是一种锁,和自旋锁不同的是,线程获取不到信号量的时候,不会像自旋锁一样循环的去试图获取锁, 而是进入睡眠,直至有信号量释放出来时,才会唤醒睡眠的线程,进入临界区执行。
由于使用信号量时,线程会睡眠,所以等待的过程不会占用CPU时间。所以信号量适用于等待时间较长的临界区。信号量消耗的CPU时间的地方在于使线程睡眠和唤醒线程,如果 (使线程睡眠 + 唤醒线程)的CPU时间 > 线程自旋等待的CPU时间,那么可以考虑使用自旋锁。
信号量有二值信号量和计数信号量2种,其中二值信号量比较常用。二值信号量表示信号量只有2个值,即0和1。信号量为1时,表示临界区可用,信号量为0时,表示临界区不可访问。二值信号量表面看和自旋锁很相似,区别在于争用自旋锁的线程会一直循环尝试获取自旋锁,而争用信号量的线程在信号量为0时,会进入睡眠,信号量可用时再被唤醒。
计数信号量有个计数值,比如计数值为5,表示同时可以有5个线程访问临界区。
信号量相关函数参照:
/* 定义并声明一个信号量,名字为mr_sem,用于信号量计数 */
static DECLARE_MUTEX(mr_sem);
/* 试图获取信号量...., 信号未获取成功时,进入睡眠
* 此时,线程状态为 TASK_INTERRUPTIBLE
*/
down_interruptible(&mr_sem);
/* 这里也可以用:
* down(&mr_sem);
* 这个方法把线程状态置为 TASK_UNINTERRUPTIBLE 后睡眠
*/
/* 临界区 ... */
/* 释放给定的信号量 */
up(&mr_sem);
一般用的比较多的是down_interruptible()方法,因为以 TASK_UNINTERRUPTIBLE 方式睡眠无法被信号唤醒。
对于 TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE 补充说明一下:
TASK_INTERRUPTIBLE - 可打断睡眠,可以接受信号并被唤醒,也可以在等待条件全部达成后被显式唤醒(比如wake_up()函数)。
TASK_UNINTERRUPTIBLE - 不可打断睡眠,只能在等待条件全部达成后被显式唤醒(比如wake_up()函数)。
sema_init(struct semaphore *, int) 以指定的计数值初始化动态创建的信号量
init_MUTEX(struct semaphore *) 以计数值1初始化动态创建的信号量
init_MUTEX_LOCKED(struct semaphore *) 以计数值0初始化动态创建的信号量(初始为加锁状态)
down_interruptible(struct semaphore *) 以试图获得指定的信号量,如果信号量已被争用,则进入可中断睡眠状态
down(struct semaphore *) 以试图获得指定的信号量,如果信号量已被争用,则进入不可中断睡眠状态
down_trylock(struct semaphore *) 以试图获得指定的信号量,如果信号量已被争用,则立即返回非0值
up(struct semaphore *) 以释放指定的信号量,如果睡眠队列不空,则唤醒其中一个任务
信号量结构体具体如下:
/* Please don't access any members of this structure directly */
struct semaphore {
spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};
可以发现信号量结构体中有个自旋锁,这个自旋锁的作用是保证信号量的down和up等操作不会被中断处理程序打断。
读写信号量
读写信号量和信号量之间的关系 与 读写自旋锁和普通自旋锁之间的关系 差不多。读写信号量都是二值信号量,即计数值最大为1,增加读者时,计数器不变,增加写者,计数器才减一。也就是说读写信号量保护的临界区,最多只有一个写者,但可以有多个读者。
读写信号量的相关内容参见:
互斥体
互斥体也是一种可以睡眠的锁,相当于二值信号量,只是提供的API更加简单,使用的场景也更严格一些,如下所示:
- mutex的计数值只能为1,也就是最多只允许一个线程访问临界区
- 在同一个上下文中上锁和解锁
- 不能递归的上锁和解锁
- 持有个mutex时,进程不能退出
- mutex不能在中断或者下半部中使用,也就是mutex只能在进程上下文中使用
- mutex只能通过官方API来管理,不能自己写代码操作它
在面对互斥体和信号量的选择时,只要满足互斥体的使用场景就尽量优先使用互斥体。
在面对互斥体和自旋锁的选择时,参见下表:
- 低开销加锁 优先使用自旋锁
- 短期锁定 优先使用自旋锁
- 长期加锁 优先使用互斥体
- 中断上下文中加锁 使用自旋锁
- 持有锁需要睡眠 使用互斥体
互斥体头文件:
mutex_lock(struct mutex *) 为指定的mutex上锁,如果锁不可用则睡眠
mutex_unlock(struct mutex *) 为指定的mutex解锁
mutex_trylock(struct mutex *) 试图获取指定的mutex,如果成功则返回1;否则锁被获取,返回0
mutex_is_locked(struct mutex *) 如果锁已被争用,则返回1;否则返回0
完成变量
完成变量的机制类似于信号量,比如一个线程A进入临界区之后,另一个线程B会在完成变量上等待,线程A完成了任务出了临界区之后,使用完成变量来唤醒线程B。
完成变量的头文件:
init_completion(struct completion *) 初始化指定的动态创建的完成变量
wait_for_completion(struct completion *) 等待指定的完成变量接受信号
complete(struct completion *) 发信号唤醒任何等待任务
使用完成变量的例子可以参考:kernel/sched.c 和 kernel/fork.c
一般在2个任务需要简单同步的情况下,可以考虑使用完成变量。
顺序锁
顺序锁为读写共享数据提供了一种简单的实现机制。之前提到的读写自旋锁和读写信号量,在读锁被获取之后,写锁是不能再被获取的,也就是说,必须等所有的读锁释放后,才能对临界区进行写入操作。
顺序锁则与之不同,读锁被获取的情况下,写锁仍然可以被获取。
使用顺序锁的读操作在读之前和读之后都会检查顺序锁的序列值,如果前后值不符,则说明在读的过程中有写的操作发生,那么读操作会重新执行一次,直至读前后的序列值是一样的。
do
{
/* 读之前获取 顺序锁foo 的序列值 */
seq = read_seqbegin(&foo);
...
} while(read_seqretry(&foo, seq)); /* 顺序锁foo此时的序列值!=seq 时返回true,反之返回false */
顺序锁优先保证写锁的可用,所以适用于那些读者很多,写者很少,且写优于读的场景。
顺序锁的使用例子可以参考:kernel/timer.c和kernel/time/tick-common.c文件
禁止抢占
其实使用自旋锁已经可以防止内核抢占了,但是有时候仅仅需要禁止内核抢占,不需要像自旋锁那样连中断都屏蔽掉。
这时候就需要使用禁止内核抢占的方法了:
preempt_disable() 增加抢占计数值,从而禁止内核抢占
preempt_enable() 减少抢占计算,并当该值降为0时检查和执行被挂起的需调度的任务
preempt_enable_no_resched() 激活内核抢占但不再检查任何被挂起的需调度的任务
preempt_count() 返回抢占计数
这里的preempt_disable()和preempt_enable()是可以嵌套调用的,disable和enable的次数最终应该是一样的。
禁止抢占的头文件参见:
顺序和屏障
对于一段代码,编译器或者处理器在编译和执行时可能会对执行顺序进行一些优化,从而使得代码的执行顺序和我们写的代码有些区别。
一般情况下,这没有什么问题,但是在并发条件下,可能会出现取得的值与预期不一致的情况
比如下面的代码:
/*
* 线程A和线程B共享的变量 a和b
* 初始值 a=1, b=2
*/
int a = 1, b = 2;
/*
* 假设线程A 中对 a和b的操作
*/
void Thread_A()
{
a = 5;
b = 4;
}
/*
* 假设线程B 中对 a和b的操作
*/
void Thread_B()
{
if (b == 4)
printf("a = %d\n", a);
}
由于编译器或者处理器的优化,线程A中的赋值顺序可能是b先赋值后,a才被赋值。
所以如果线程A中 b=4; 执行完,a=5; 还没有执行的时候,线程B开始执行,那么线程B打印的是a的初始值1。
这就与我们预期的不一致了,我们预期的是a在b之前赋值,所以线程B要么不打印内容,如果打印的话,a的值应该是5。
在某些并发情况下,为了保证代码的执行顺序,引入了一系列屏障方法来阻止编译器和处理器的优化。
rmb() 阻止跨越屏障的载入动作发生重排序
read_barrier_depends() 阻止跨越屏障的具有数据依赖关系的载入动作重排序
wmb() 阻止跨越屏障的存储动作发生重排序
mb() 阻止跨越屏障的载入和存储动作重新排序
smp_rmb() 在SMP上提供rmb()功能,在UP上提供barrier()功能
smp_read_barrier_depends() 在SMP上提供read_barrier_depends()功能,在UP上提供barrier()功能
smp_wmb() 在SMP上提供wmb()功能,在UP上提供barrier()功能
smp_mb() 在SMP上提供mb()功能,在UP上提供barrier()功能
barrier() 阻止编译器跨越屏障对载入或存储操作进行优化
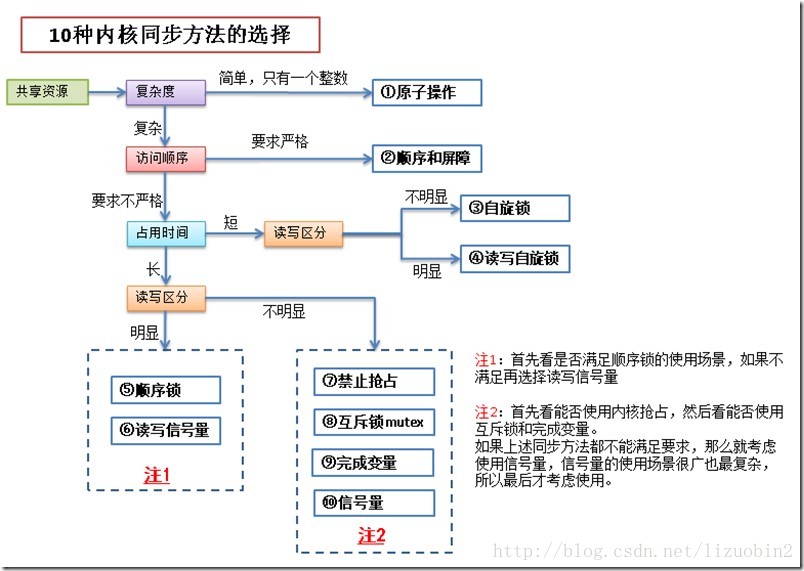
10种同步方法在图中分别用蓝色框标出。