A、B两表,找出id字段中,存在A表,但是不存在B表的数据。
示例:a表 b表

方法1: 使用 not in ,容易理解,效率低 ~执行时间为:1.395秒~
SELECT DISTINCT a.id FROM a WHERE a.ID NOT IN (SELECT id FROM b)方法二 : 使用 left join...on... , "B.ID isnull" 表示左连接之后在B.ID 字段为 null的记录 ~执行时间:0.739秒~
select A.ID from A left join B on A.ID=B.ID where B.ID is null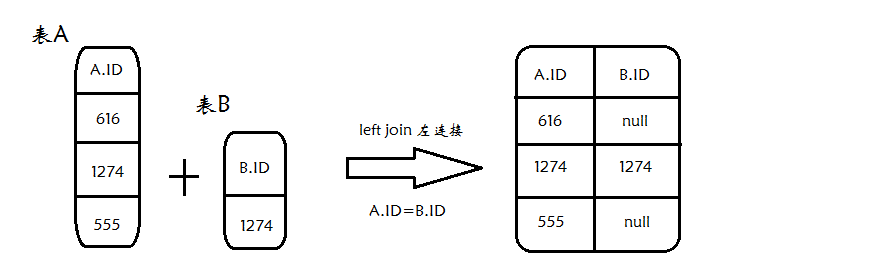
方法三 : 逻辑相对复杂,但是速度最快 ~执行时间: 0.570秒~
SELECT * FROM a
WHERE (SELECT COUNT(1) FROM b WHERE A.ID = B.ID) = 0;对于效率我没有测试,这是前人的测试结果,而且原博客最后一种方法写错了。
下面解释一下第三种做法:
按顺序来 首先SELECT * FROM a , 如果没有where的话就是查询所有。
现在有where 就缩小范围了,你可以这样理解,他按顺序遍历自己的值,当前值只有where后的表达式等于true时才会取出来。(‘’‘仅是为了方便理解,真实可能并不这样’)。
然后看子查询,子查询count(1) 只有在后面条件 a.id=b.id 时才count 的值才加一。本表没重复数据也就是说 a.id=b.id 时,count(1) =1。
等于1 的时候 WHERE (SELECT COUNT(1) FROM b WHERE A.ID = B.ID) = 0; 就是false。 所以从a中按顺序取值时只要在b中存在的,这个表达式都是false, 所以就在a中取不出来了。
除了a,b中id相等。剩下所有情况count(1)都为0 , WHERE (SELECT COUNT(1) FROM b WHERE A.ID = B.ID) = 0; 就为true. 对a 中的取值就没限制。
你看我count 一个b表中不存在的数据就返回0
![]()