网络爬虫的流程梳理
URL放在队列里面,如果被访问过就设置个标记,直到遍历完所有的URL。

搭建maven环境
I eclipse搭建maven环境(更快捷的管理jar包)
1、网上下载maven
下载地址:
http://maven.apache.org/download.cgi
2、配置环境变量
① 新建系统变量如下(本地的maven路径):

② path中加入如下路径(win10):

③ 测试安装是否完成:

3、配置本地仓库
① Window->Preferences->Maven->Installations
选中add,加入自己本地的maven路径。

② 第一步之后会默认启用maven/conf路径下的settings.xml文件,在这个文件中配置本地仓库,相应的改成自己的路径。repository用来存放jar包。

4、配置jar包
直接在pom.xml文件的dependencies节点中添加依赖即可。
查找jar包的网址:
https://mvnrepository.com/tags/maven

eclipse快速输出:syso + alt + /
eclipse快速设置get set方法:右击Source->Generate Getters() and Setters()
II IDEA搭建maven环境
1、添加本地maven仓库
配置好后会自动下载需要的jar包。
如果最后没有出现Build Success,可能是网络不稳定,建议重新再来一遍,或者删除以lastupdate为后缀名的文件,再次更新maven project。依赖项的添加和eclipse一样。

2、reimport maven project
设置好后还是发现pom.xml文件报错。
View->Tool Windows->Maven,点击下图的Reimport All Maven Projects。

3、添加run
Main class为你要运行的类,并设置好自己的jre。

IDEA快速添加main函数:psvm
IDEA快速输出:sout
IDEA快速设置get set方法:鼠标放在私有成员变量上,按下alt + enter,Create getter and setter for X
一、静态页面爬取
爬取豆瓣电影排行榜的一些数据举例子。
静态页面的爬取可以用HttpClient的jar包下载页面,用HtmlCleaner的jar包解析页面。
1、页面下载
Page是自己建的实体类。先使用HttpClient 创建客户端,根据URL创建请求,客户端提交请求得到相应,(虚拟服务端)将响应的内容返回,其中content中包含了整个页面的html代码块,下一步需要对代码进行解析。
public class PageDownloadUtil {
public static Page getPageContent(String url) {
//创建客户端
HttpClient client=HttpClients.createDefault();
//创建get方法并添加请求头
HttpGet request=new HttpGet(url);
//request.setHeader("user-agent", ""); //可以设置请求头
HttpResponse response = null;
try {
response = client.execute(request);
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//将得到的实体转换成字符串类型
HttpEntity entity=response.getEntity();
String content=null;
try {
content=EntityUtils.toString(entity,"UTF-8");
} catch (ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
Page page=new Page();
page.setContent(content);
page.setUrl(url);
page.setDownnumber("0");
page.setUpnumber("0");
return page;
}
}
2、页面解析
使用Htmlcleaner的clean方法清洗上一步的html代码,再根据XPath定位到对应的标签,最后用正则表达式匹配出想要的数据,存放到容器里面。
public class DouBanProcessService {
private static String allnumberRegex = "\\d+";
private static String allchineseRegex = "[\\u4E00-\\u9FA5]+";
public static Page process(Page page) {
String content = page.getContent();
// 获取整个html的node
HtmlCleaner htmlCleaner = new HtmlCleaner();
TagNode rootNode = htmlCleaner.clean(content);
List<String> list=new ArrayList<String>();
int i=0;
try {
Object[] numberXPath = rootNode
.evaluateXPath("//*[@id=\"9593388\"]/div/div[3]");
if (numberXPath.length > 0) {
TagNode node = (TagNode) numberXPath[0];
Pattern numberPattern = Pattern.compile(allnumberRegex,
Pattern.DOTALL);
Matcher matcher1 = numberPattern.matcher(node.getText()
.toString());
while (matcher1.find()) {
list.add(matcher1.group(0));
System.out.println(matcher1.group(0));
}
}
page.setUpnumber(list.get(i++));
page.setDownnumber(list.get(i++));
page.setCommentumber(list.get(i++));
Object[] nameXPath = rootNode
.evaluateXPath("//*[@id=\"9593388\"]/header/a[2]");
if (nameXPath.length > 0) {
TagNode node = (TagNode) nameXPath[0];
Pattern namePattern = Pattern.compile(allchineseRegex,
Pattern.DOTALL);
Matcher matcher2 = namePattern.matcher(node.getText()
.toString());
while (matcher2.find()) {
page.setName(matcher2.group(0));
}
}
} catch (XPatherException e) {
e.printStackTrace();
}
return page;
}
public static void main(String[] args) {
String url = "https://movie.douban.com/review/best/";
// 下载页面
Page page= PageDownloadUtil.getPageContent(url);
Page after_page=DouBanProcessService.process(page);
System.out.println("电影名字:"+page.getName()+" 点赞人数:"+page.getUpnumber()+
" 差评人数:"+page.getDownnumber()+" 评论人数:"+page.getCommentumber());
}
}
3、结果
结果显示简单的静态页面被爬取下来了。

二、动态页面爬取
爬取爱奇艺海贼王连载的每集的标题举例子。
动态页面下载就需要用到HtmlUnit的jar包,用来模拟点击事件。针对Ajax异步请求,通过观察URL的规律,直接暴力抓取json数据包的URL。页面解析可以用Jsoup的jar包,操作比HtmlCleaner更简单。
1、页面下载
① 第一次请求(从左图到右图)
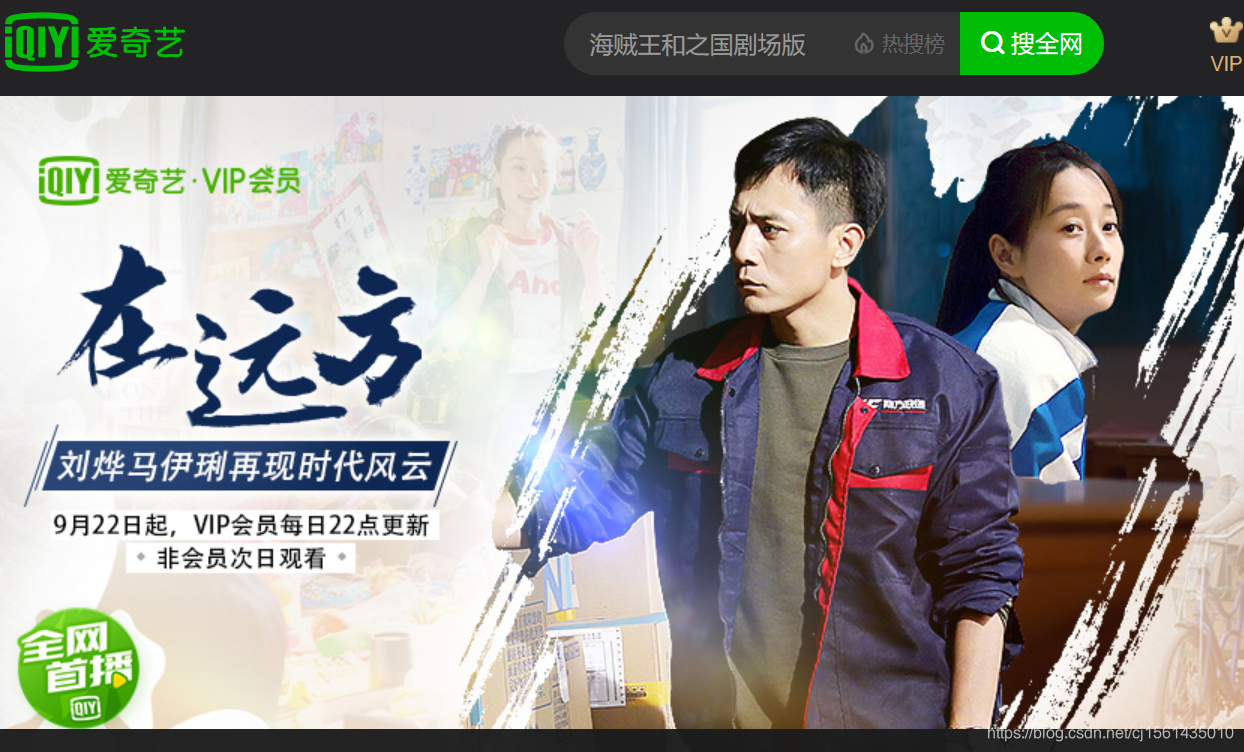
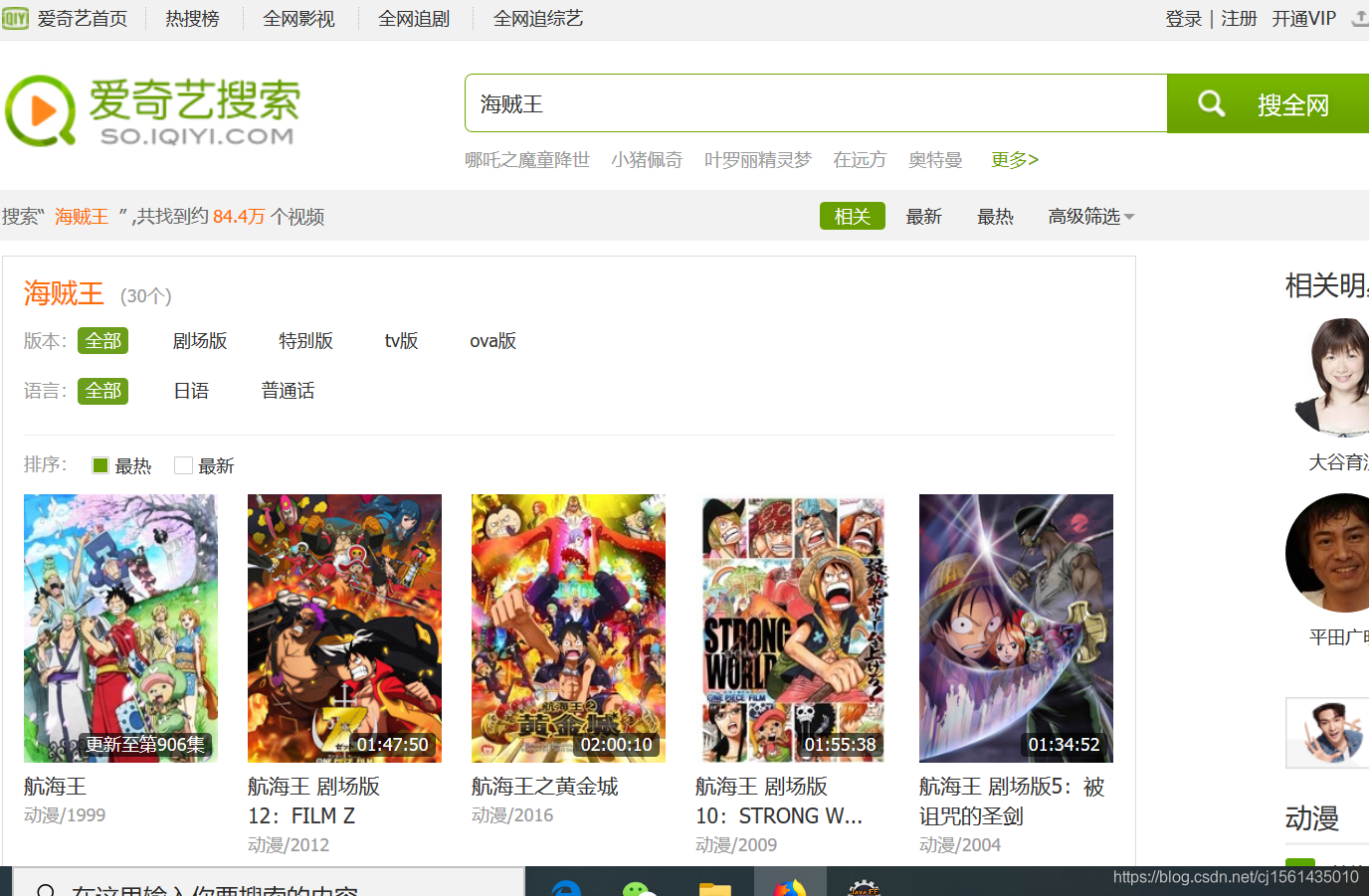
jsoup的jar包解析Dom树的结点,可以很方便的select出想操作的节点,newURL返回的是上图第二个页面的链接。
public class SimulatedLoginUtil {
public static String getnewURL(String url) {
// jsoup模拟海贼王超链接的点击事件,返回新的URL
String newURL = null;
// System.getProperties().setProperty("proxySet", "true"); 代理协议
// System.getProperties().setProperty("https.proxyHost",
// "192.168.130.15"); 代理IP
// System.getProperties().setProperty("https.proxyPort", "8848"); 代理端口
Connection con = Jsoup.connect(url);// 获取连接
con.header(
"User-Agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0");// 配置模拟浏览器
con.header("Accept-Language", "zh-CN");
Response rs = null;
try {
rs = con.execute();
Document dom = Jsoup.parse(rs.body());// 转换为Dom树
// 直接再Dom树里面选择(根据id或者class)
List<Element> et = dom.select(".search-box-input");
// 在搜索框中设值,这个中文字还要转成UTF-8格式,在字符串处理模块再转
Element inputtext = et.get(0).attr("value", "海贼王");
String des_keyword = inputtext.attr("value");
newURL = StringProcessUtil.produceFornewurl(url, des_keyword); //改变URL并转码
} catch (IOException e) {
e.printStackTrace();
}
...续第二次请求
}
}
② 第二次请求(从左图到右图)
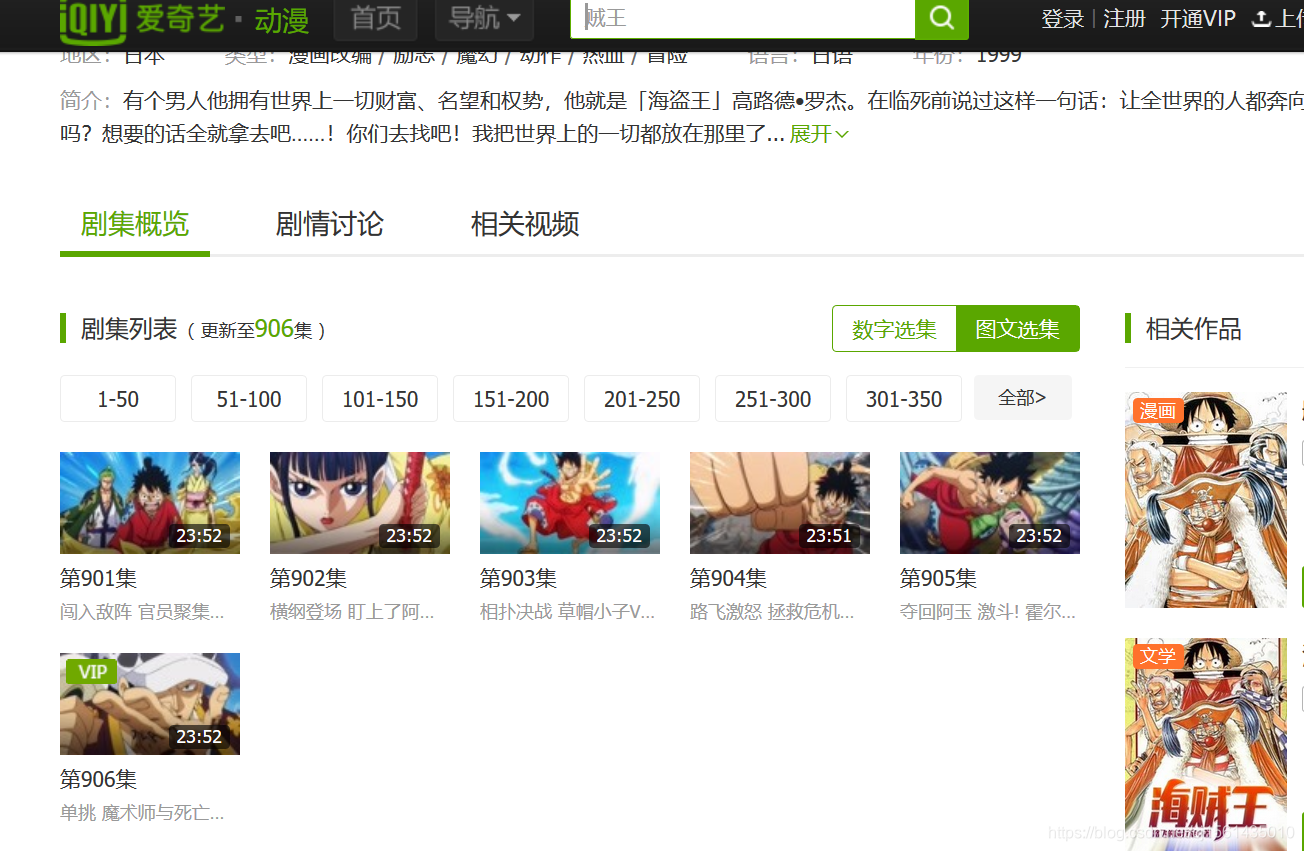
先在新的URL(已经转成UTF-8格式)里面查找跳转到下个页面的超链接,HtmlUnit模拟页面的的点击,finallyURL返回的也是上图第二个页面的链接。
public class SimulatedLoginUtil {
public static String getnewURL(String url) {
...续第一次请求
// htmlunit模拟网页点击,选中要查看的海贼王非剧场版动漫
WebClient client = new WebClient(BrowserVersion.getDefault());
client.getOptions().setCssEnabled(false);
client.getOptions().setJavaScriptEnabled(false);
client.getOptions().setTimeout(10000);
client.getOptions().setThrowExceptionOnScriptError(false);
client.getOptions().setThrowExceptionOnFailingStatusCode(false);
client.getOptions().setRedirectEnabled(true);
// client.getCookieManager().setCookiesEnabled(true);
// client.getOptions().setUseInsecureSSL(true);
client.setAjaxController(new NicelyResynchronizingAjaxController());
String finallyURL = null;
HtmlPage page = null, next_page = null;
int k = 0, flag = 0;
try {
page = client.getPage(newURL);
System.out.println(newURL);
// Dom树中遍历
DomNodeList<DomElement> domlist = page.getElementsByTagName("a");
for (int i = 0; i < domlist.getLength(); i++) {
DomElement domElement = domlist.get(i);
if (domElement.asText().equals("航海王")) {
k = i;
flag = 1;
break;
}
}
if (flag == 0)
System.out.println("没找到超链接a");
HtmlElement e = (HtmlElement) domlist.get(k);
client.waitForBackgroundJavaScript(3000); // 等待js执行完毕
// 模拟点击事件
next_page = e.click();
client.waitForBackgroundJavaScript(3000); // 等待js执行完毕
finallyURL = next_page.getUrl().toString();
} catch (FailingHttpStatusCodeException e3) {
e3.printStackTrace();
} catch (MalformedURLException e3) {
e3.printStackTrace();
} catch (IOException e3) {
e3.printStackTrace();
}
return finallyURL;
}
}
2、字符串处理
produceFornewurl(String url, String keyword)函数不仅要转成UTF-8编码,还要修改网址,其中跳转后的网址将www换成了so。
public class StringProcessUtil {
...继清洗数据
public static String produceFornewurl(String url, String keyword) {
String newURL = null;
String encodekeyword = null;
int index_point = url.indexOf(".");
int index_www = url.indexOf("w");
newURL = url.substring(0, index_www) + "so"
+ url.substring(index_point);
try {
// URL中的中文要转成UTF-8
encodekeyword = URLEncoder.encode(keyword, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
newURL = newURL + "so/q_" + encodekeyword;
return newURL;
}
}
3、页面解析(包括第二次请求的转编码格式)
观察法,查看URL的变化规律,其实就是page后面变换值。打开缓冲区,用StringBuilder 类接收json中的数据,再HtmlCleaner+Regex抓取最终页面中的数据。340集标题名字残缺真是很骚气,找了半天才发现是网页的问题。。。
public class DynamicDownload {
public static Map<String, String> dynamicdownloadForonePage(String url,
int pageindex) {
String content = null;
String oldurl = "https://pcw-api.iqiyi.com/albums/album/avlistinfo?aid=202861101&size=50&page=";
String newurl = oldurl + pageindex;
StringBuilder json = new StringBuilder();
URLConnection uc = null;
BufferedReader in = null;
String str = null;
URL urlobject = null;
// 根据URL直接抓取json包
try {
urlobject = new URL(newurl);
uc = urlobject.openConnection();
//打开缓冲区
in = new BufferedReader(new InputStreamReader(
urlobject.openStream(), "UTF-8"));
while ((str = in.readLine()) != null)
json.append(str);
if (in != null)
in.close();
} catch (MalformedURLException e1) {
e1.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
// 清洗需要的内容,并放到map里面
content = json.toString();
HtmlCleaner cleaner = new HtmlCleaner();
TagNode rn = cleaner.clean(content);
Map<String, String> rs = new LinkedHashMap<String, String>();
String temp1, temp2;
//regex匹配
Pattern p_number = Pattern.compile("\"order\":\\d+");
Pattern p_name = Pattern.compile("subtitle\":\"[^\"]+\",\"vid");
Matcher m_number = p_number.matcher(rn.getText().toString());
Matcher m_name = p_name.matcher(rn.getText().toString());
while (m_number.find() && m_name.find()) {
temp1 = m_number.group(0);
temp2 = m_name.group(0);
rs.put(temp1, temp2);
}
// 修复爱奇艺页面中的340集名字残缺
List<String> list = new ArrayList<>();
int flag = 0, i = 0;
if (pageindex == 7) {
for (String key : rs.keySet()) {
if ("\"order\":340".equals(key))
flag = 1;
if (flag == 1) {
String value = rs.get(key);
list.add(value);
}
}
flag = 0;
for (String key : rs.keySet()) {
if ("\"order\":340".equals(key)) {
flag = 1;
rs.put(key, "subtitle\":\"被称为天才的男人! 霍古巴可现身\",\"vid");
continue;
}
if (flag == 1) {
rs.put(key, list.get(i++));
}
}
// rs.put("\"order\":350", list.get(i++));
}
return rs;
}
}
4、数据清洗
前面哈希表里面存放的是下图,需要清洗数据,重新存放到哈希表里面。
cutForonepice(Map<String, String> m)函数是清洗map里面的数据,保存成集号和标题的形式。

public class StringProcessUtil {
public static Map<String, String> cutForonepice(Map<String, String> m) {
Map<String, String> rs = new LinkedHashMap<String, String>();
String right = "340";
int index1, index2, index3;
String newkey, newvalue;
for (String key : m.keySet()) {
index1 = key.indexOf(":", 0);
newkey = key.substring(index1 + 1, key.length());
String value = m.get(key);
index2 = value.indexOf(":", 0);
index3 = value.indexOf(",", 0);
newvalue = value.substring(index2 + 2, index3 - 1);
rs.put(newkey, newvalue);
}
return rs;
}
...续字符串处理
}
5、入口类
/*
* 海贼王onepice执行入口
*/
public class StartCrawl {
public static void main(String[] args) {
ResultMap object = new ResultMap();
Map<String, String> des_map = new LinkedHashMap<String, String>();
String url = "https://www.iqiyi.com";
String des_url = SimulatedLoginUtil.getnewURL(url);
for (int i = 1; i <= 19; i++) {
Map<String, String> rs = DynamicDownload.dynamicdownloadForonePage(
des_url, i);
des_map.putAll(rs);
System.out.println("第" + i + "页 已经抓取完成");
}
object.setTree(des_map);
object.setTree(StringProcessUtil.cutForonepice(object.getTree()));
System.out.println("全部抓取完毕");
for (String key : object.getTree().keySet()) {
String value = object.getTree().get(key);
System.out.println(key + " " + value);
}
}
}
6、结果
成功取到想要的数据,可以将它放到数据库或者存到本地的excel、txt等等格式。

三、邮件推送
1、设置开启服务(网易邮箱为例)

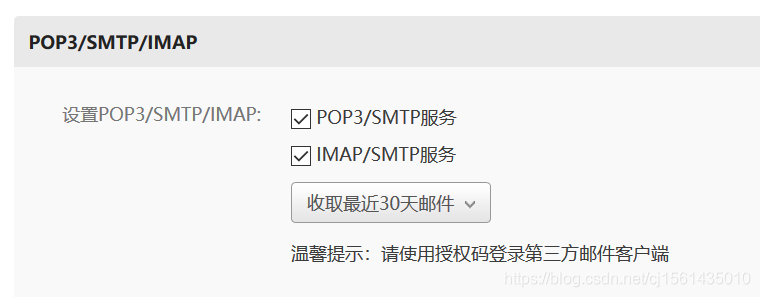
2、代码
public class SendEmailUtil {
public static void send() {
final String send_account = "[email protected]";
final String send_password = ReadFileUtil.readTextFile("D:\\IDEAproject\\Spider\\pwd.txt").trim(); // 密码或者是你自己的设置的授权码
// SMTP服务器
String MEAIL_163_SMTP_HOST = "smtp.163.com";
String SMTP_163_PORT = "25";// 端口号,这个是163使用到的;
// 收件人
String receive_account = "[email protected]";
Properties p = new Properties(); //创建连接对象
//Properties.
p.put("mail.transport.protocol", "smtp"); //设置邮件发送的协议
p.setProperty("mail.smtp.host", "smtp.163.com"); //设置发送邮件的服务器(这里用的163-SMTP服务器)
p.setProperty("mail.smtp.auth", "true"); //设置经过账号密码的授权
//设置服务器的端口号
p.setProperty("mail.smtp.port", "25");
p.setProperty("mail.smtp.socketFactory.port", "25");
p.setProperty("mail.smtp.socketFactory.class", "javax.net.ssl.SSLSocketFactory");
Session session = Session.getInstance(p, new Authenticator() {
// 设置认证账户信息
@Override
protected PasswordAuthentication getPasswordAuthentication() {
return new PasswordAuthentication(send_account, send_password);
}
});
try {
MimeMessage message = new MimeMessage(session); //创建邮件对象
message.setFrom(new InternetAddress(send_account)); //设置发件人
message.setRecipients(Message.RecipientType.TO, receive_account);
message.setRecipients(Message.RecipientType.CC, send_account); //重点:最好写这个抄送,不然大概率会被当成垃圾邮件!!
message.setFrom(new InternetAddress(send_account));
message.setSubject("one pice!");
message.setText("海贼王更新了!!!");
message.setSentDate(new Date());
message.saveChanges();
Transport.send(message);
} catch (MessagingException e) {
e.printStackTrace();
}
}
}
public class ReadFileUtil {
public static String readTextFile(String path) {
StringBuilder content = new StringBuilder("");
try {
File file = new File(path);
BufferedReader buffer = new BufferedReader(new FileReader(file));
String line = null;
while ((line = buffer.readLine()) != null) {
content.append(line);
content.append("\n");
}
buffer.close();
} catch (Exception e) {
System.out.println("读取内容出错");
e.printStackTrace();
}
return content.toString();
}
public static void main(String[] args) {
String x=ReadFileUtil.readTextFile("D:\\IDEAproject\\Spider\\pwd.txt");
System.out.println(x);
}
}
3、结果

