1. 文档编写目的
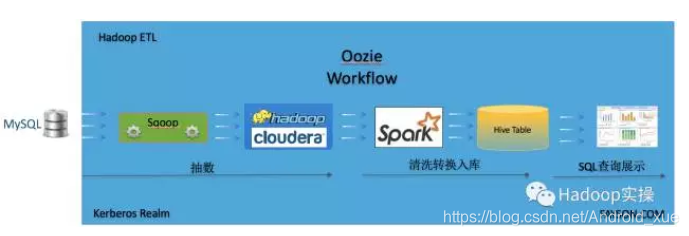
在使用CDH集群中经常会有一些特定顺序的作业需要在集群中运行,对于需要多个作业顺序执行的情况下,如何能够方便的构建一个完整的工作流在CDH集群中执行,前面Fayson也讲过关于Hue创建工作流的一系列文章具体可以参考《如何使用Hue创建Spark1和Spark2的Oozie工作流》、《如何使用Hue创建Spark2的Oozie工作流(补充)》、《如何在Hue中创建Ssh的Oozie工作流》。本篇文章主要讲述如何使用Hue创建一个以特定顺序运行的Oozie工作流。本文工作流程如下:
- 内容概述
1.作业描述
2.使用Hue创建Oozie工作流
3.工作流测试 - 测试环境
1.CM和CDH版本为5.11.2
2.采用sudo权限的ec2-user用户操作
3.集群已启用Kerberos - 前置条件
1.集群已安装Hue服务
2.集群已安装Oozie服务
2. 创建一个Parquet格式的Hive表
创建一个Hive表,该表用于Spark作业保存数据,注意这里创建的Parquet格式的表
create table testaaa (
`age` bigint COMMENT '',
`id` bigint COMMENT '',
`name` string COMMENT ''
) STORED AS parquet
3. Sqoop抽数作业
这里的Sqoop抽数以MySQL为例。
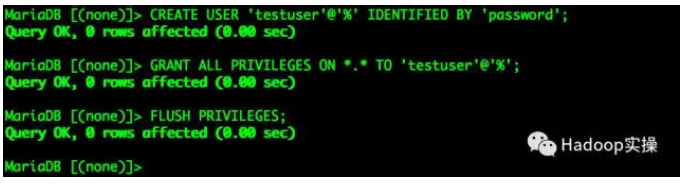
1.创建一个MySQL的测试账号及准备测试数据
CREATE USER 'testuser'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON *.* TO 'testuser'@'%';
FLUSH PRIVILEGES;
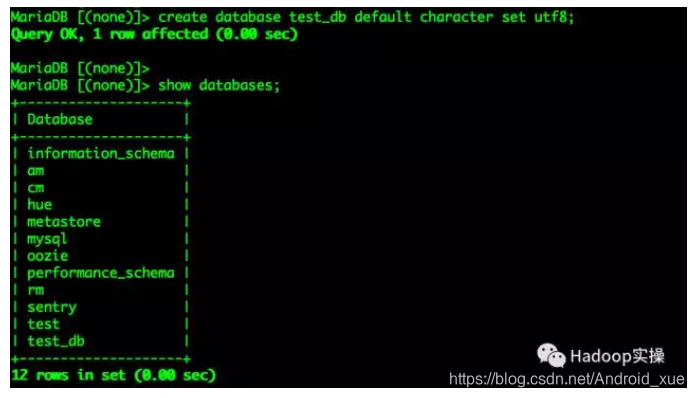
准备测试表和数据
create database test_db default character set utf8;
创建表并插入测试数据
create table test_user(
id int(10) primary key not null auto_increment,
name varchar(20) not null,
age int(10) not null
) ENGINE=InnoDB DEFAULT CHARSET=UTF8;
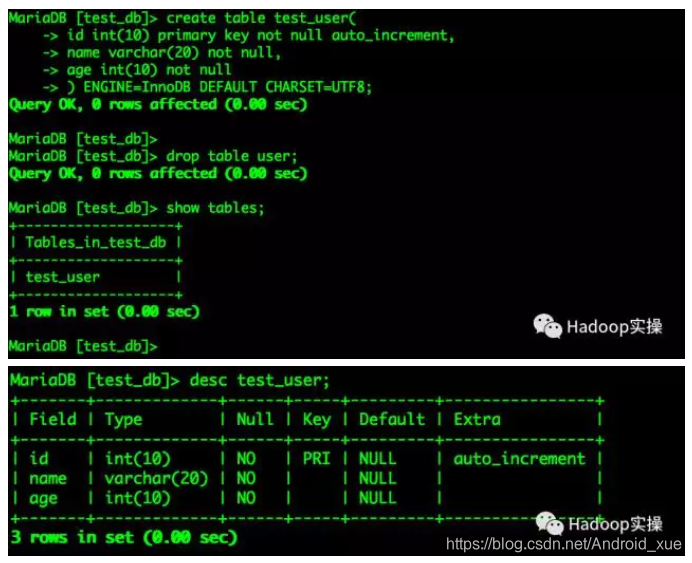
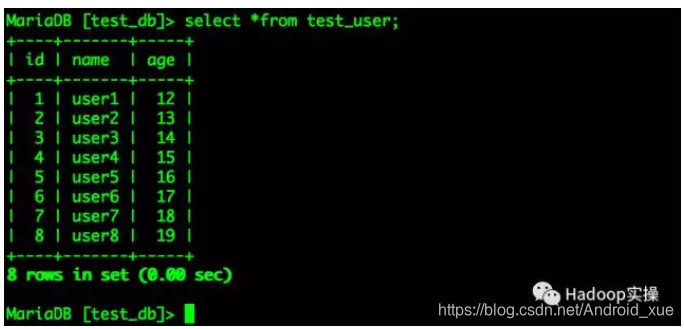
向表中插入数据
insert into test_user (name,age) values('user1', 12);
insert into test_user (name,age) values('user2', 13);
insert into test_user (name,age) values('user3', 14);
insert into test_user (name,age) values('user4', 15);
insert into test_user (name,age) values('user5', 16);
insert into test_user (name,age) values('user6', 17);
insert into test_user (name,age) values('user7', 18);
insert into test_user (name,age) values('user8', 19);
2.Sqoop抽数脚本
import
--connect
jdbc:mysql://10.169.xx.xxx/test_user
--username
root
--password
root
--as-textfile
--columns
id,name,age
--table
test_user
--target-dir
hdfs://master02:8020/tmp/test_user
-m
1
4. Spark ETL作业
将Sqoop抽取的数据通过Python的Spark作业进行ETL操作写入Hive表中
1.编写Spark脚本
#!/usr/local/anaconda3/bin/python
#coding:utf-8
# 初始化sqlContext
from pyspark import SparkConf,SparkContext
from pyspark.sql import HiveContext,Row
conf=(SparkConf().setAppName('PySparkETL'))
sc=SparkContext(conf=conf)
sqlContext = HiveContext(sc)
# 加载文本文件并转换成Row.
lines = sc.textFile("/tmp/test_user/*")
parts = lines.map(lambda l: l.split(","))
people = parts.map(lambda p: Row(id=int(p[0]),name=p[1], age=int(p[2])))
# 将DataFrame注册为table.
schemaPeople = sqlContext.createDataFrame(people)
schemaPeople.registerTempTable("people")
sqlContext.cacheTable("people")
# 执行sql查询,查下条件年龄在13岁到16岁之间
teenagers = sqlContext.sql("SELECT * FROM people WHERE age >= 13 AND age <= 16")
teenagers.write.saveAsTable("testaaa", mode="append")
5. Hive查询作业
将Spark作业处理后的数据写入hive表中,使用Hive对表进行查询操作
编写hive-query.sql文件,内容如下:
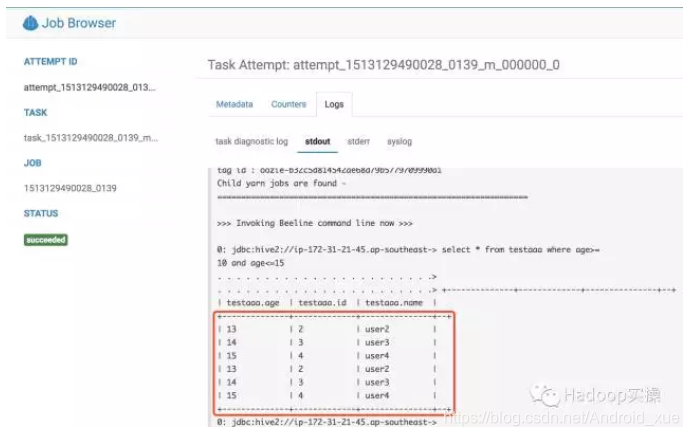
select * from testaaa where age>=10 and age<=15
6. 创建工作流
1.进入Hue界面,选择”Workflows” => “Editors”=> “Workflows”
2.在以下界面中点击“Create”按钮创建工作流
3.然后进入WrokSpace

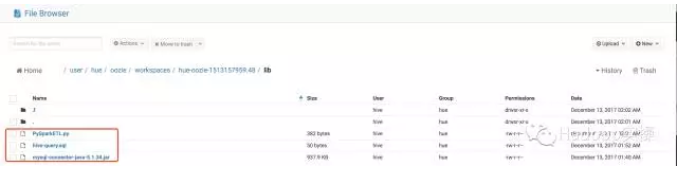
将工作流相关的JDBC驱动包、ETL和Hive脚本放在当前WorkSpace的lib目录下
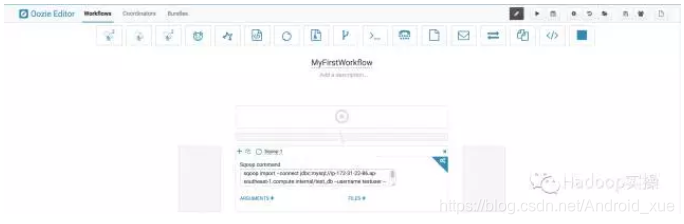
4.在工作流中添加Sqoop抽数作业
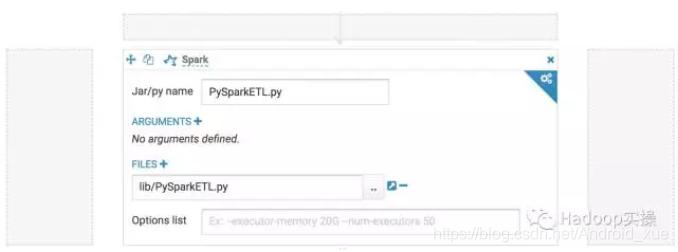
5.添加PySpark ETL工作流
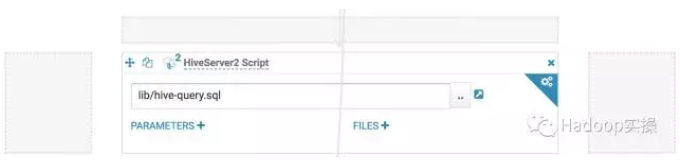
6.添加Hive工作流
如下是一个完成的工作流
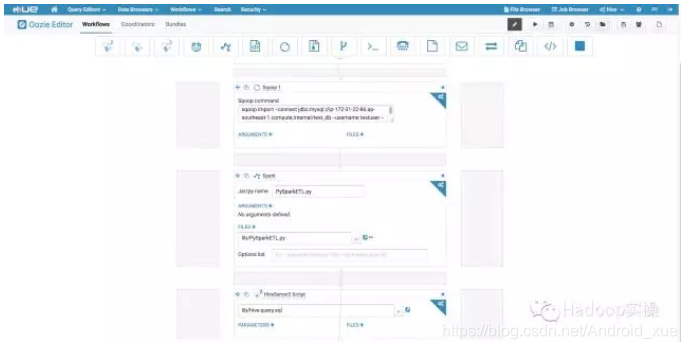
点击保存,完成工作流定义。
7. 工作流运行
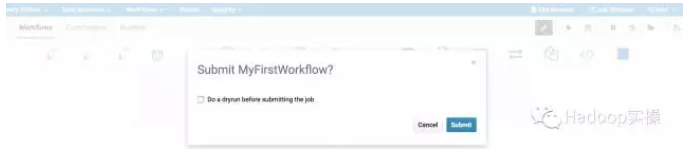
1.工作流保存成功后,点击运行
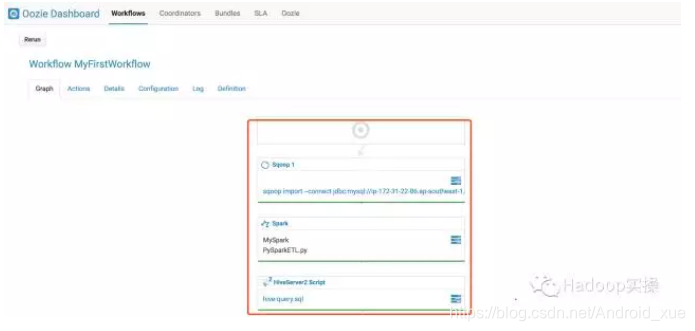
2.Oozie调度任务执行成功
8. 作业运行结果查看
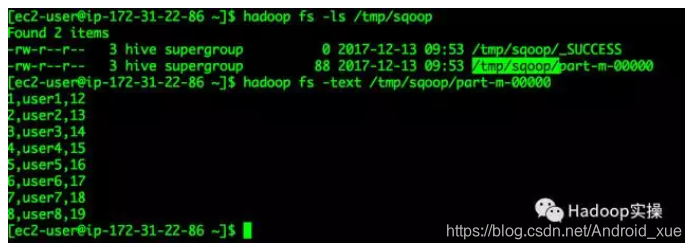
Sqoop抽数结果查看(我上面把目录改了/tmp/test_user/*,下图是原文的路径)
Spark ETL执行成功查看Hive表testaaa数据
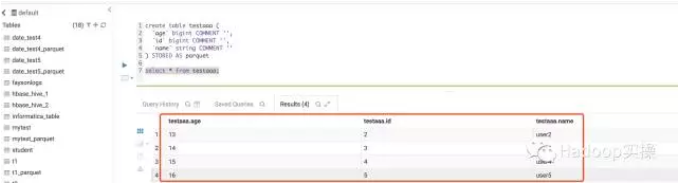
Hive作业执行结果查看