MySQL中int(M)和tinyint(M)数值类型中M值的意义
在一开始接触MySQL数据库时,对于int(M)及tinyint(M)两者数值类型后面的M值理解是最多能够插入数据库中的值不能大于M;
后来工作后,也是一边学习一边使用,之后的理解是其中的M的意思是插入数据库中的值的字符长度不能大于M,例如,int(4),想要插入1234,1234的字符长度是4,就正好可以插入数据库,12341就不行,因为是5个字符长度,这也都是道听途说,自己从来没有验证过;
如今,由于面试中经常会被问到有关数据库方面的知识,今天也想着深入了解下这个M代表的含义(上述两个理解都是错误的)。
首先,我们创建一个数据表test:
mysql> CREATE TABLE test(
-> id1 int(1),
-> id2 tinyint(1)
->);
我们给id1定义为int,并设置字符长度为1,id2定义为tinyint,也设置字符长度为1;
然后分别插入值127,127,结果发现,两者都插入到了数据表中:
mysql> INSERT INTO test(id1,id2) values(127,127);//运行成功
结果是插入成功的,从此次测试已经可以知道,我之前的想法都是错误的,接下来我们再做一个实验,插入数据128,128,即id=128,id2=128:
mysql> INSERT INTO test(id1,id2) values(128,128);//运行失败:ERROR 1264 (22003):Out of range value for column 'id2' at row 1
出错了,int类型的id1插入成功了,tinyint类型的id2提示超出了范围,这是为什么呢?
首先,我们先要了解一个基础知识点,就是下面这张表:(摘自W3C教程)
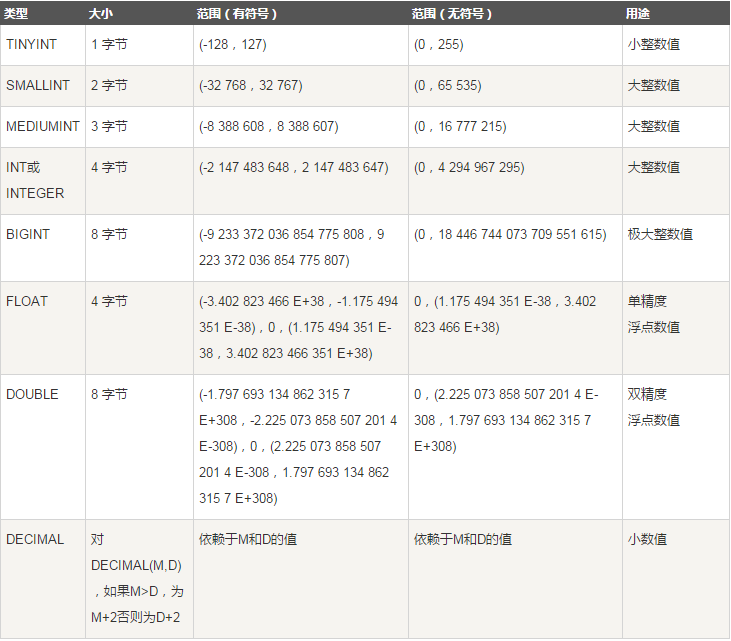
上述表格中的数值类型都是定长的,也就是说,无论你存的数值是多少,多大或者多小,占用的字节大小都是固定的。例如,之前设置的int(1),虽然M值是1个字符,但是它所占用的空间大小永远都是4个字节的大小,换句话说就是,你可以存入有符号整型从-2 147 483 648到2 147 483 647包括这两个数的中间任何一个数。int(1)和int(11)占用的是4个字节,可以存入上述这些数,tinyint(1)和tinyint(4)占用的是1个字节,可以存入从-128到127的数,这也是为什么之前的一次试验,int(1)插入128成功,而tinyint(1)插入128却提示超出长度。
那么,这个M值到底代表什么意思呢?
到这里,我们已经可以发现,M值即使设置为1,它也可以存入字符长度大于1的值,那么,如果存入的字符长度小于1会怎么样?我们来试一试:
先将id1的类型更改为int(2),然后插入数据id1=1:
mysql> ALTER TABLE test Modify id1 int(2); mysql> INSERT INTO test(id1) values(1);//运行成功,说明值1已经插入到test表中
我们查询一下表中的数据,看看结果具体如何:

mysql> SELECT * FROM test; +------+ | id1 | +------+ | 1 | +------+
接下来,我们再修改一下id1的填充数据类型zerofill(表示用0填充),这里先知道如何操作即可,我们再从结果得出结论:
mysql> ALTER TABLE test MODIFY id1 int(2) zerofill; mysql> SELECT * FROM test;
+------+ | id1 | +------+ | 01 | +------+
现在是不是有些清楚了。我们设置的M值是2,没有设置zerofill用0填充时,对于操作没有任何影响,而设置了zerofill后,我们可以清楚地看到值1字符数不足M值,左前位置补0。我们也可以将M值设置成别的大小进行多次测试,这里就不进行测试了。
需要强调的是,不同的数据类型中的M值意义是不一样的,我们这里仅讨论整型中的M值。
从上面我们可以得到如下的结论:
1、整数型的数值类型已经限制了取值范围,有符号整型和无符号整型都有,而M值并不代表可以存储的数值字符长度,它代表的是数据在显示时显示的最小长度;
2、当存储的字符长度超过M值时,没有任何的影响,只要不超过数值类型限制的范围;
3、当存储的字符长度小于M值时,只有在设置了zerofill用0来填充,才能够看到效果,换句话就是说,没有zerofill,M值就是无用的。
总结:int(11),tinyint(1),bigint(20),后面的数字,不代表占用空间容量。而代表最小显示位数。这个东西基本没有意义,除非你对字段指定zerofill。
所以我们在设计mysql数据库时,建表时,mysql会自动分配长度:int(11)、tinyint(4)、smallint(6)、mediumint(9)、bigint(20)。
所以,就用这些默认的显示长度就可以了。不用再去自己填长度,比如搞个int(10)、tinyint(1)之类的,基本没用。而且导致表的字段类型多样化。
参考博客:http://www.cnblogs.com/stringzero/p/5707467.html
MySQL当记录不存在时insert,当记录存在时更新;网上基本有三种解决方法
第一种:
示例一:insert多条记录
假设有一个主键为 client_id 的 clients 表,可以使用下面的语句:
INSERT INTO clients (client_id, client_name, client_type) SELECT supplier_id, supplier_name, 'advertising' FROM suppliers WHERE not exists (select * from clients where clients.client_id = suppliers.supplier_id);
示例一:insert单条记录
INSERT INTO clients (client_id, client_name, client_type) SELECT 10345, 'IBM', 'advertising' FROM dual WHERE not exists (select * from clients where clients.client_id = 10345);
使用 dual 做表名可以让你在 select 语句后面直接跟上要insert字段的值,即使这些值还不存在当前表中
第二种:INSERT 中 ON DUPLICATE KEY UPDATE的使用
如果您指定了ON DUPLICATE KEY UPDATE,并且insert行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则执行旧行UPDATE。
例如,如果列a被定义为UNIQUE,并且包含值1,则以下两个语句具有相同的效果:
INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1;
UPDATE table SET c=c+1 WHERE a=1;
如果行作为新记录被insert,则受影响行的值为1;如果原有的记录被更新,则受影响行的值为2。
注释:如果列b也是唯一列,则INSERT与此UPDATE语句相当:
UPDATE table SET c=c+1 WHERE a=1 OR b=2 LIMIT 1;
如果a=1 OR b=2与多个行向匹配,则只有一个行被更新。通常,您应该尽量避免对带有多个唯一关键字的表使用ON DUPLICATE KEY子句。
您可以在UPDATE子句中使用VALUES(col_name)函数从INSERT...UPDATE语句的INSERT部分引用列值
换句话说,如果没有发生重复关键字冲突,则UPDATE子句中的VALUES(col_name)可以引用被insert的col_name的值
本函数特别适用于多行insert。 VALUES()函数只在INSERT...UPDATE语句中有意义,其它时候会返回NULL
示例:
INSERT INTO table (a,b,c) VALUES (1,2,3),(4,5,6) ON DUPLICATE KEY UPDATE c=VALUES(a)+VALUES(b);
本语句与以下两个语句作用相同:
INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=3;
INSERT INTO table (a,b,c) VALUES (4,5,6) ON DUPLICATE KEY UPDATE c=9;
当您使用ON DUPLICATE KEY UPDATE时,DELAYED选项被忽略。
第三种:REPLACE语句
我们在使用数据库时可能会经常遇到这种情况。
如果一个表在一个字段上建立了唯一索引,当我们再向这个表中使用已经存在的键值insert一条记录,那将会抛出一个主键冲突的错误。
当然,我们可能想用新记录的值来覆盖原来的记录值。如果使用传统的做法,必须先使用DELETE语句删除原先的记录,然后再使用
INSERTinsert新的记录。而在MySQL中为我们提供了一种新的解决方案,这就是REPLACE语句。使用REPLACEinsert一条记录时,
如果不重复,REPLACE就和INSERT的功能一样,如果有重复记录,REPLACE就使用新记录的值来替换原来的记录值。
使用REPLACE的最大好处就是可以将DELETE和INSERT合二为一,形成一个原子操作。这样就可以不必考虑在同时使用DELETE和INSERT时添加事务等复杂操作了。
在使用REPLACE时,表中必须有唯一索引,而且这个索引所在的字段不能允许空值,否则REPLACE就和INSERT完全一样的。
在执行REPLACE后,系统返回了所影响的行数,如果返回1,说明在表中并没有重复的记录,如果返回2,说明有一条重复记录,系统自动先调用了 DELETE删除这条记录,
然后再记录用INSERT来insert这条记录。如果返回的值大于2,那说明有多个唯一索引,有多条记录被删除和insert
REPLACE的语法和INSERT非常的相似,如下面的REPLACE语句是insert或更新一条记录
REPLACE INTO users (id,name,age) VALUES(123, '赵本山', 50);
insert多条记录:
REPLACE INTO users(id, name, age) VALUES(123, '赵本山', 50), (134,'Mary',15);
REPLACE也可以使用SET语句
REPLACE INTO users SET id = 123, name = '赵本山', age = 50;
上面曾提到REPLACE可能影响3条以上的记录,这是因为在表中有超过一个的唯一索引。
在这种情况下,REPLACE将考虑每一个唯一索引,并对每一个索引对应的重复记录都删除,然后insert这条新记录。
假设有一个table1表,有3个字段a, b, c。它们都有一个唯一索引。
CREATE TABLE table1 (a INT NOT NULL UNIQUE, b INT NOT NULL UNIQUE, c INT NOT NULL UNIQUE);
假设table1中已经有了3条记录
a b c 1 1 1 2 2 2 3 3 3
下面我们使用REPLACE语句向table1中insert一条记录。
REPLACE INTO table1(a, b, c) VALUES(1,2,3);
返回的结果如下
Query OK, 4 rows affected (0.00 sec)
在table1中的记录如下
a b c 1 2 3
我们可以看到,REPLACE将原先的3条记录都删除了,然后将(1, 2, 3)insert
总结:虽然没有具体测试,
感觉第一种最费资源了(只是感觉),不过你要是没有主键的话也只能用他了
第二种和第三种的区别是:
1)insert是先尝试insert,若主键存在则更新。REPLACE是先尝试insert,若主键存在则删除原纪录再insert。
2)如果有多个唯一关键字发生冲突(不同关键字的冲突发生在不同记录),比如现在有2个字段2条记录冲突了(没条记录冲突一个字段),则insert是选择排序后在前面的一条进行更新,REPLACE是删除那两条记录,
然后insert新记录
