网页链接
需爬取的内容:所有国家所有物流渠道时效表现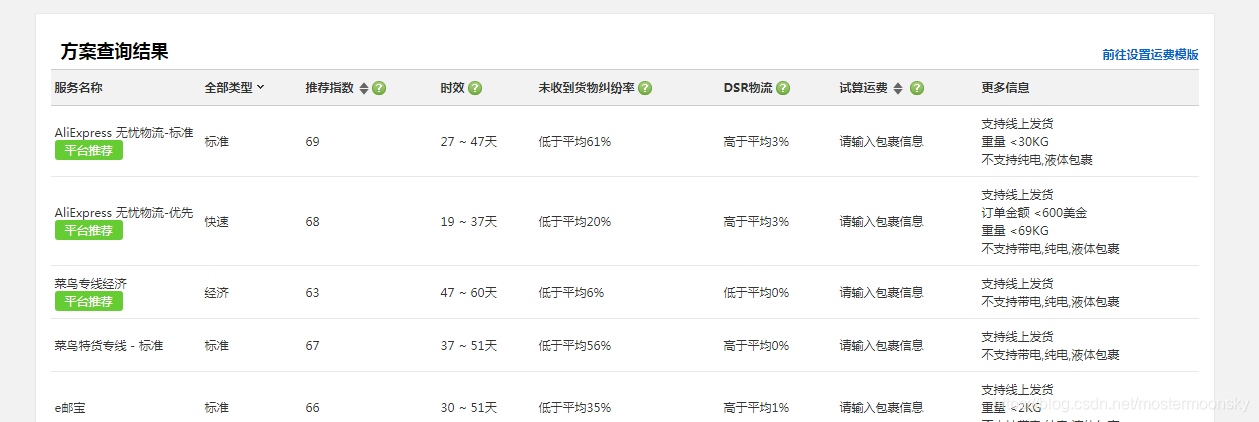
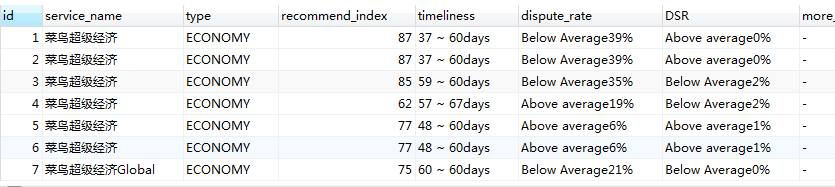
爬取内容展示:
上代码:
from bs4 import BeautifulSoup
from urllib.request import urlopen
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
import random
import requests
import time
import json
import threading
import pymysql
import datetime
def channellist():
list = []
url = 'https://ilogistics.aliexpress.com/recommendation_engine_public.htm'
response = urlopen(url)
soup = BeautifulSoup(response, 'html.parser')
a = soup.select('div[class = "service-list-class-block"]>li>input')
for item in a:
value = item['value']
list.append(value)
return list
#构造随机切换响应头列表
ua_list = [
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36",
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36"
]
headers = {
"origin":"https://ilogistics.aliexpress.com",
"referer":"zhttps://ilogistics.aliexpress.com/recommendation_engine_public.htm",
"sec-fetch-mode":"zcors",
"sec-fetch-site":"zsame-origin",
"content-type":"application/x-www-form-urlencoded; charset=UTF-8",
"accept":"application/json, text/javascript, */*; q=0.01",
"accept-encoding":"gzip, deflate, br",
"accept-language":"zh-CN,zh;q=0.9,en;q=0.8",
"User-Agent": random.choice(ua_list)
}
form = {"_csrf_token_":"409mp_mcutc9",
"logistics-services-set":"/",
"logistics-services-list-all":"[[Ljava.lang.String;@4d577287,",
"logistics-class-filter":"ALL",
"sort-by-recommend-points":"0",
"sort-by-logistics-freight":"0",
"toCountry":"RU",
"fromCountry":"CN",
"logistics-express-item":"CAINIAO#CAINIAO_STANDARD_SG#CAINIAO_STANDARD_SG#STANDARD",
"limitedGoods":"general",
"orderAmount":"",
"packageWeight":"",
"packageLength":"",
"packageWidth":"",
"packageHeight":""
}
#爬取内容函数
def getCountryDict(): #得到国家对应二字码的字典及列表
dict = {}
list =[]
url = 'https://ilogistics.aliexpress.com/recommendation_engine_public.htm'
response = urlopen(url)
soup = BeautifulSoup(response, 'html.parser')
a = soup.select('select[name="toCountry"]>option')
for item in a:
value = item['value']
name = item.string
dict[name] = value
list.append(value)
dict.pop('Other Country')
list.remove('OTHER')
list.remove('Other')
return [dict,list]
countryDict = getCountryDict()
currentdate = datetime.date.today() #当前日期作为版本号插入
def splitDict(list,dict,n): #切分字典
for i in range(0,len(list),n):
tem_dict ={key: value for key, value in dict.items() if value in list[i:i+n]}
yield tem_dict
url = "https://ilogistics.aliexpress.com/recommendationJsonPublic.do"
i = 1
channels = channellist()
irank = list(i for i in range(100,1000,100))
def grabContent(countrydict):
global i
session = requests.session()
for k,v in countrydict.items():
for channel in channels:
form["toCountry"] = v
form["logistics-express-item"] = channel
response = session.post(url, headers=headers, data=form, verify=False)
aa = response.content.decode('utf-8')
b = json.loads(aa)
# print(b['logisticsServices'][0]['dsr'])
if 'logisticsServices' in b.keys() and len(b['logisticsServices']) != 0 and b['logisticsServices'][0]['recommendPoints'] != '-' and b['logisticsServices'][0]['recommendPoints'] != 'No data available':
serviceName = b['logisticsServices'][0]['serviceName']
logisticsClass = b['logisticsServices'][0]['logisticsClass']
recommendPoints = b['logisticsServices'][0]['recommendPoints']
deliveryPeriod = b['logisticsServices'][0]['deliveryPeriod']
dispute = b['logisticsServices'][0]['dispute']
dsr = b['logisticsServices'][0]['dsr']
freight = b['logisticsServices'][0]['freight']
list = [k, serviceName, logisticsClass, recommendPoints, deliveryPeriod, dispute, dsr, freight]
list2 = [serviceName,logisticsClass,recommendPoints,deliveryPeriod,dispute,dsr,'-',k,currentdate ]
conn = pymysql.connect(host="localhost", user="root", password="123456", database="test",
charset="utf8", port=3306)
cursor = conn.cursor()
sql = """insert into smt_monitor
(service_name,type,recommend_index,timeliness,dispute_rate,DSR,more_info,destination,version)
values('%s','%s',%s,'%s','%s','%s','%s','%s','%s')""" % tuple(list2)
try:
cursor.execute(sql)
conn.commit()
except:
conn.rollback()
print("写入:" + str(i) + "行")
i += 1
if i in irank:
time.sleep(2) #多层伪装停顿,防止服务器断开
time.sleep(1)
else:
print(b)
time.sleep(1)
cursor.close()
conn.close()
temDicts = splitDict(countryDict[1],countryDict[0],10)
threadlists = [] #创建一个列表装线程对象
for temDict in temDicts:
threadlists.append(threading.Thread(target=grabContent,args=(temDict,))) #把线程对象放进列表
if __name__ == '__main__':
for target in threadlists:
target.start() #启动每一个线程
