最近项目上用到了Kafka(作为数据源接入),这里将自己的实践分享出来,供大家参考或针砭。
从网上查阅资料发现,基本上有2中与Kafka对接的方式:
1.Spring-Kafka
2.调用Kafka API自己实现ConsumerClient
Spring-Kafka的基本原理就是Spring自动轮询Poll数据,通过监听器MessageListener.onMessage()向用户自定义的消费入口(@KafkaListener)推送数据。因此对于用户来说,仅需要关注自己的业务实现即可,Kafka数据对于业务来说就是一个方法的入参而已。这种设计很有意思,因为Kafka是不支持主动Push的,但是Spring-Kafka自己实现了这种角色反转。Spring-Kafka本身就是一个很好的实现,而且上手相对简单,推荐大家使用这种方式。
温馨提示:Spring-Kafka和kafka-clients之间有版本的兼容性问题需特别注意,另外如果你使用SpringBoot开发的话也需要匹配特定的版本。


#Spring-Kafka KafkaConsumer消费模型(来源于网络)
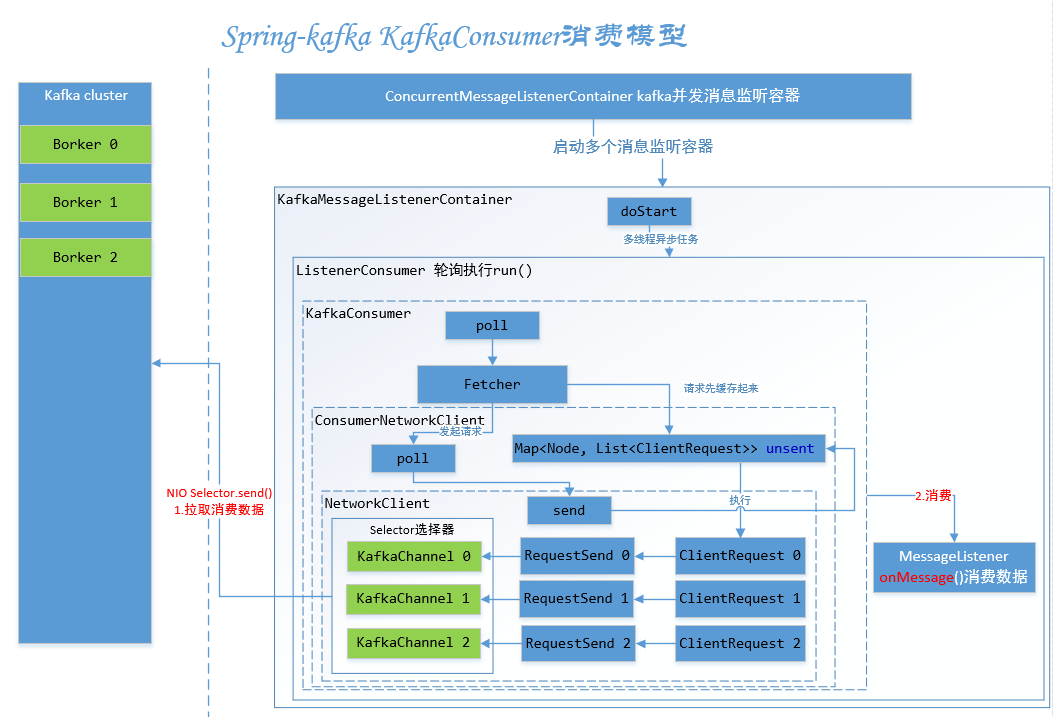
不过抱着学习研究的目的,本篇选择第2中实现方式,其实和Spring-Kafka殊途同归。
直奔主题,本篇就不阐述太多理论性的东西,仅介绍一些基本的Kafka API对象和概念:
1.KafkaConsumer,顾名思义就是Kafka的数据消费者,其主要作用是连接Kafka订阅(subscribe)相关主题(topic)并拉取(poll)数据并提交消费偏移(offset)。
2.ConsumerRecord,Kafka数据接收记录,其中有些重要的属性:topic(主题),patition(分区),offset(偏移),key(主键),value(数据值)。
PS:KafkaConsumer是非线程安全的
对于一个Kafka消费客户端有些基本的配置:
1.bootstrap.servers --连接Kafka集群的地址,多个地址以逗号分隔 2.key.deserializer --消息中key反序列化类,需要和Producer中key序列化类相对应 3.value.deserializer --消息中value的反序列化类,需要和Producer中Value序列化类相对应 4.group.id --消费者所属消费组的唯一标识
为了提高单线程消费Kafka数据的效率,我们要在此基础上创建一个专门用于处理数据的线程池。简单来说,就是一个线程只用来Poll数据,然后丢给线程池去处理。
消费线程:KafkaConsumerClient.java


/** * 消费线程 * * @author lichmama * */ public class KafkaConsumerClient extends Thread { /** 读取超时 **/ private static final int timeout = 3000; /** 核心线程数 **/ private static final int corePoolSize = 4; /** 最大线程数 **/ private static final int maximumPoolSize = 10; /** 空闲存活时间 **/ private static final long keepAliveTime = 30L; /** 队列容量 **/ private static final int capacity = 2000; /** 告警数据处理线程池 **/ private static final ExecutorService executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.SECONDS, new ArrayBlockingQueue<>(capacity)); /** kafka配置 **/ private Properties props; /** kafka主题 **/ private String topics; private static KafkaConsumer<String, String> consumer = null; private static KafkaConsumerClient client = null; private KafkaConsumerClient(Properties props, String topics) { super("KafkaConsumerClient"); this.props = props; this.topics = topics; } @Override public void run() { System.out.println("KafkaConsumerClient is running..."); try { consumer = new KafkaConsumer<String, String>(props); consumer.subscribe(Collections.singletonList(topics)); } catch (Exception e) { e.printStackTrace(); return; } while (true) { // 循环读取 try { consumer.poll(timeout).forEach(record -> { process(record); }); } catch (Exception e) { e.printStackTrace(); continue; } } } /** * 处理数据 * * @param record */ private void process(ConsumerRecord<String, String> record) { try { executor.submit(new KafkaDataProcessor(record)); } catch (Exception e) { e.printStackTrace(); } } /** * 启动KafkaConsumerClient工作线程 * * @param props * @param topics */ public static synchronized void doStart(Properties props, String topics) { if (client == null) { client = new KafkaConsumerClient(props, topics); client.start(); } else { System.out.println("KafkaConsumerClient already started!"); } } /** * 异步提交 * * @param record */ public static synchronized void commitAsync(ConsumerRecord<String, String> record) { if (consumer != null) { Map<TopicPartition, OffsetAndMetadata> currentOffset = new HashMap<>(); currentOffset.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, "no metadata")); consumer.commitAsync(currentOffset, null); } else { System.err.println("KafkaConsumer is null!"); } } }
数据处理线程:KafkaDataProcessor.java
/** * 处理线程 * @author lichmama * */ public class KafkaDataProcessor extends Thread { private ConsumerRecord<String, String> record; public KafkaDataProcessor(ConsumerRecord<String, String> record) { this.record = record; } @Override public void run() { System.out.println(String.format("topic:%s, partition:%d, offset:%d, message:%s", record.topic(), record.partition(), record.offset(), record.value())); } }
启动程序:StartKafkaConsumer.java
public class StartKafkaConsumer { public static void main(String[] args) throws Exception { Properties props = new Properties(); props.load(new FileInputStream("consumer-config.properties")); String topics = (String) props.remove("topics"); // 启动消费线程 KafkaConsumerClient.doStart(props, topics); } }
kafka消费者配置:consumer-config.properties
##-*- 消费者配置 -*-## #kafka集群地址 bootstrap.servers=localhost:9092 #消费者归属组ID group.id=test_group #单次最大拉取记录数 max.poll.records=20 #关闭自动提交 enable.auto.commit=false #key反序列化类名 key.deserializer=org.apache.kafka.common.serialization.StringDeserializer #value反序列化类名 value.deserializer=org.apache.kafka.common.serialization.StringDeserializer #订阅主题 topics=test
有一点需要注意的,要根据实际情况来调整线程池的队列长度、线程数以及单次最大拉取记录数,才能确保程序运行良好,否则可能会造成告警丢失。
到这基本就完成了,跑起来看看效果吧。