从本章开始, 将学习一些可包含一组元素的数据结构, 也被称为数据集合, 比如数组 (切片,slice) 和 map, 这很显然是受到 Python 语言的影响.
数组类型会使用[ ] 符号, 这也是大多数编程语言的基本类型, Go 语言的数组与其他语言基本类似, 但也有自己的一些特点, 它不具备 C 数组的动态特性, 如果需要类似功能, 需使用 Go 语言的 slice 类型, 该类型是一种基于 Go 数组类型的上层类型, 数组类型可包含存储空间, 但是不够灵活, 所以在 Go 代码中较少使用, 通常情况下, 都会使用 slice 类型, 该类型更易用且功能更强大.
7.1 声明和初始化
7.1.1 概念
数组是一个定长的数据元素序列, 同时所有数据元素的类型都相同, 并能使用任意类型, 比如整型, 字符串或用户自定义类型, 数组长度必须由一个常量表达式提供, 并且必须是一个非负的整型值, 在编译期内, 需对数组的所有元素值进行初始化.
数组元素的类型也可使用空接口 (参见 11.9 节), 只是在使用这些元素值时, 需提供一次类型断言 (类型检查),参见 11.3 节.
通过数组索引 (位置信息), 可访问和修改数组元素值, 索引值将从 0 开始, 即第一个元素的索引值为 0, 第二个元素的索引值为 1, 依次类推, 数组元素的个数, 被称为数组的长度或尺寸, 在数组声明时, 数组长度必须是一个常量 (以便在编译期内, 为数组分配内存), 最大的数组长度为 2Gb.
数组的声明格式为:

下图给出了数组的存储方式:
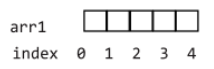
在声明数组时, 所有元素值都将自动初始化为对应类型的默认值, 如果是 int 类型, 元素值将自动初始化为 0.len(arr1) 可获取 arr1 数组的长度, 即为 5, 因此该数组的索引范围为 0 ∼ len(arr1)-1. arr1[0] 可获取数组的第一个元素, arr1[2] 可获取数组的第三个元素, 因此 arr1[i] 可获取索引值为 i 的元素值, 获取最后一个元素, 可使用 arr1[len(arr1)-1].
使用索引值, 可为数组元素分配一个数值, 如 arr[i] = value, 同时数组只接受有效索引值, 如果给出的索引值大于或等于 len(arr1), 如果被编译器检测到, 它将产生一个错误信息, 告知索引值超出了数组边界, 如果未被编译器检测到, 将在程序执行时, 导致运行崩溃, 参见第 13 章.
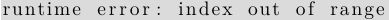
由于存在索引值, 可使用 for 语句对数组进行处理:
• 初始化数组元素
• 打印数组元素
• 连续处理每个数组元素
例 7.1 for_arrays.go

注意 for 语言中, i < len(arr1) 和 i <= len(arr1) 之间的区别, 在数组处理中, 也可使用 for-range:

其中 i 为数组的索引值, 同时 for 语句也可用于 slice 类型, 参见 7.2 节.
由于 Go 数组是一个数值类型 (不同于 C/C++ 可使用指针, 访问数组的第一个元素), 因此也可使用 new() 函数, 创建一个 Go 数组:
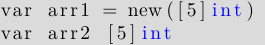
arr1 与 arr2 的区别在于,arr1 的元素类型为 *int, 而 arr2 的元素类型为 int. 如果将数组分配给其他数组, 将生成原数组的一个内存副本, 如下:
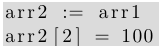
arr2 元素值将变更为 arr1 元素值, 在之后的语句中, 修改 arr2 元素值, 并不会导致 arr1 元素值的变更.
同时数组也可作为实参, 传递给函数, 如 func1(arr1), 这时也将创建原数组的一个副本, func1 也无法对原数组进行修改. 为了实现更高效的处理方法,arr1 可使用 &, 将引用传递给函数, 如func1(&arr1),
例 7.2 for_arrays.go


同时创建基于数值的 slice 也可使用上述方法, 也能将 slice 传递给函数, 参见 7.1.4 节.

7.1.2 数组的构造器
如果需要预先定义数组的元素值, 可使用{,} 组合符号完成定义, 这被称为数组的构造器, 而不是采用 [索引值]= 元素值, 进行每个元素的初始化, 而 Go 语言中, 所有复合类型都可使用类似的构造器, 完成所有元素的初始化.
例 7.3 array_literals.go

在 arrAge 数组定义中, 由于给出了对应的元素值, 可忽略 [5]int, 如果数组定义为 [10]int { 1, 2, 3 }, 等于提供了索引值 0-2 的元素值, 而后续的元素值将初始化为 0.
在 arrLazy 数组定义中, 编译器将获取{} 中元素值的个数, 以确定数组的长度. 同时 […]int 并不是一种类型,所以它是非法的, 应写为:
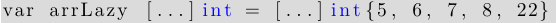
如果… 被忽略, 数组定义将被视为 slice 定义.
在 arrKeyValue 数组定义中, 只给出了索引值为 3 和 4 的元素值, 其他元素将初始化为空串, 从输出结果可查看该数组的初始化, 同时数组长度也可写为… 或是直接忽略. 同时也可获取新创建数组的指针, 即数组的访问地址, 如下:
例 7.4 pointer_array2.go


几何坐标 (或称之为矢量) 也将是数组应用的经典示例, 为了简化代码, 可使用该类型假名:

7.1.3 多维数组
数组通常是一个一维数组, 同时也可组合为多维数组, 比如:
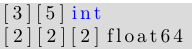
内层数组通常会包含相同的长度, 而 Go 语言的多维数组将呈现一个矩形分布, 同时 slice 类型将是一个例外,参见 7.2.5 节.
例 7.5 multidim_array.go

7.1.4 将数组传递给函数
如果将大型数组传递给函数, 将会造成内存用量的快速上升, 可使用两种方法, 解决这类问题:
• 可传递数组的指针
• 使用数组的 slice 类型
以下示例将使用第一种方法.
例 7.6 array_sum.go


上述方法并不是 Go 语言的推荐方式, 可选择第 2 种解决方法, 即 slice 类型, 参见 7.2.2 节.
7.2 slice
7.2.1 概念
一个 slice 可引用数组的连续单元 (它必须基于数组, 且通常是匿名), 所以 slice 是一种引用类型 (其实它更类似于 C/C++ 的数组类型, 或是 Python 的 list 类型),slice 可以包含整个数组, 也可使用自定义的起始索引和结束索引, 设定数组的一个子集 (slice 结束索引的元素值, 不会包含在 slice 中), 同时 slice 可基于数组类型, 实现动态操作. 使用 len() 函数也可获取 slice 的长度 (元素个数).
同一元素的 slice 索引值, 将小于数组索引值, 与数组不同,slice 的长度可在代码执行过程中发生变化, 其最小长度可为 0, 最大长度可为数组长度, 因此 slice 是一个变长数组.
cap() 内建函数可获取 slice 的最大长度, 假定 s 是一个 slice,cap(s) 将基于 slice 在下层数组所处的位置, 计算slice 起始索引与下层数组末尾索引值之间的长度, 而 slice 长度无法超过 cap(s), 因此以下的判断条件都为真:0 <= len(s) <= cap(s).
如果多个 slice 来自于同一个数组, 它们之间可共享数据, 而多个数组之间不可能共享数据, 所以来自于同一个数组的多个 slice, 将给出相同的存储数据, 而数组之间的存储数据都是独立的.
由于 slice 是引用类型, 因此不会消耗额外的内存, 所以它比数组的效率更高, 同时 Go 代码将会更多地使用slice.
slice 的声明格式:
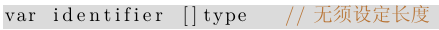
未初始化的 slice 将设定为 nil 值 (默认值), 同时它的初始长度为 0.
slice 的初始化格式:

它可表示数组 arr1 的一个切片 (从索引值 start 开始, 到 end-1 结束), 而 start:end 被称为切片表达式, 如果slice1[0] == arr1[start] 的比较结果为真, slice 可包含整个数组,slice 无法获取 slice1[0] 之前的内存数据, 这也是非法的!
声明语句var slice1 []type = arr1[:] 表示 slice1 将包含整个 arr1 数组, 而 arr1[:] 为 arr1[0:len(arr1)] 的简写, 也可使用另一种初始化方式, 实现相同的功能, slice1 = &arr1. arr1[2:] 等同于 arr1[2:len(arr1)], arr1[:3] 等同于arr1[0:3], 如果 slice1 只需保存最后一个元素, 可使用 slice1 = slice1[:len(slice1)-1], 基于包含三个元素的数组,
而创建一个 slice, 可使用 s := [3]int1,2,3[:] 或是 s := […]int1,2,3[:], 也可简化为 s := []int1,2,3.s2 := s[:] 可基于一个 slice 创建一个新 slice, 这两个 slice 将包含相同的元素, 并会引用同一个数组. 同时一个slice 可扩展到最大尺寸,s = s[:cap(s)], 如果设定的最大尺寸高于基础数组的长度, 将产生一个运行时错误, 参见例 7.7. 任意 slice(包括字符串 slice) 都满足以下条件:
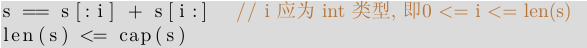
同时 slice 也可使用与数组一样的初始化方法:var x = []int{2, 3, 5, 7, 11}, 上述语句将创建一个包含 5 个元素的数组, 之后再创建一个引用该数组的 slice.
在内存中,slice 将给出 3 个数据域, 首个数据域将指向下层数组, 其次是 slice 的长度, 之后是 slice 的容量, 如果 slice 为var x := []int{2, 3, 5, 7, 11} 和 y := x[1:3], 可得到以下的存储格式:
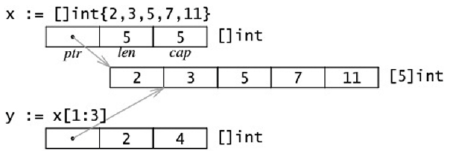
例 7.7 array_slices.go



如果 s2 是一个 slice, 如果需要去除 s2 的首个元素, 可使用 s2 = s2[1:], 这时 s2 的结尾元素不会变化, 同时 s2的长度将减 1,slice 只能实现正向移动, 如果使用 s2 = s2[-1:] 语句, 将产生一个编译错误. 因此 slice 无法给出一个负值, 以访问 slice 在初始化时, 所隐藏的数组元素. 注意, 无法在 slice 中使用指针, 因为它已经是一个引用类型, 也就是一个指针.
7.2.2 将 slice 传递给函数
如果函数需要处理一个数组, 通常情况下, 应当选择 slice, 当函数调用时, 将创建一个数组切片, 并将该 slice传递给函数, 比如在函数中, 实现数组元素的累加和.

7.2.3 使用 make() 创建 slice
如果未定义下层数组, 这时可使用 make() 函数, 同时创建下层数组和 slice, 如:

len 为数组长度, 也是 slice 的初始长度, 使用上述方法, 可创建一个 slice s2, s2 := make([]int, 10), 并能满足条件cap(s2) == len(s2) == 10. make 函数包含了两个形参, 一是 slice 的数值类型, 二是 slice 的长度.
如果 slice 并未包含整个数组, 可增加一个形参 cap, 以确定 slice 的最大长度, 如:

下图描述了 make 函数创建的 slice 的存储格式:
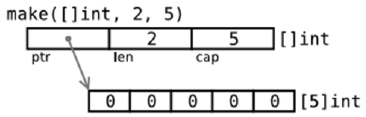
例 7.8 make_slice.go


由于字符串本身就是一个字节数组, 因此也给出 slice 类型.
7.2.4 new() 与 make() 的区别
这两个函数都可在分配堆 (heap) 内存, 并可用于不同任务和使用不同类型.
• new(T) 可为 T 类型的一个元素, 分配存储空间 (初始值为 0), 并返回存储地址, 其中的类型为 *T, 可表
示一个指针, 将指向新分配的 T 类型存储空间, 这类分配可用于数组和结构 (参见第 10 章), 并可等价于&T{}.
• make(T) 它可返回 T 类型的初始值, 只能用于 3 种引用类型:slice,map 和 channel, 参见第 8 章和第 13 章.
下图将给出上述两种函数的分配结果:

与上图对应的代码如下:

上述用法在 Go 代码很少见到, 而p := make([]int, 0) 将创建一个已初始化的 slice, 该 slice 将指向一个为空的数组. 但 make 函数的常见用法如下:
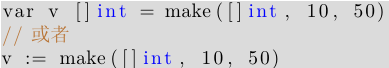
上述代码可分配一个包含 50 个 int 元素的数组, 并创建一个 slice v, 它的长度为 10, 容量为 50, 且引用了下层数组的前 10 个元素.
7.2.5 多维 slice
除了使用一维数组和 slice 之外, 还将其组合成多维数组和 slice, 那么这种类型的长度变化更大, 所以 Go 语言中多维 slice 的维度变化, 将呈现逐步增大的态势, 同时内层 slice 必须单独分配 (使用 make).
7.2.6 bytes 包
在 bytes 包中, 字节 slice 是一种常见类型, 其中的函数都会使用这种类型, 这与 strings 包很相似 (参见 4.7节), 同时还包含了一种更方便的类型 Buffer:

在 Read 和 Write 方法中, 需要一个尺寸可变的缓冲, 因为读写操作中, 需要处理的字节数据的长度, 无法事先知道.
• 创建一个 Buffer 变量: var buffer bytes.Buffer
• 使用 new 函数, 创建一个 Buffer 变量指针: var r *bytes.Buffer = new(bytes.Buffer)
• 缓冲空间的创建函数: func NewBuffer(buf []byte) *Buffer
使用上述操作, 都可创建和初始化一个新的 Buffer 变量, 同时变量还可包含初始值, 使用 NewBuffer 创建的缓冲, 最好只用于读取操作.
使用缓冲, 实现字符串的合并
这类功能与 Java 语言的 StringBuilder 类很相似, 创建一个缓冲, 使用 buffer.WriteString(s) 方法, 可将每个字符串都附加到缓冲中, 之后可使用 buffer.String(), 将缓冲内容转换成一个字符串, 如下:

上述操作相比于 +=, 需要较多的内存, 同时对 CPU 性能也有要求, 尤其是需合并的字符串较多时.
7.3 for-range 控制结构
该结构可用于数组和 slice:

ix 为数组或 slice 的索引值,value 为索引对应的存储值, 在 for 语句的程序块中, ix 和 value 将视为本地变量,同时 value 将会给出一个副本, 因此 for 语句无法对 value 进行修改.
例 7.9 slices_forrange.go

例 7.10 slices_forrange2.go, 其中将对字符串进行处理

上例中, _ 可弃用索引值, 如果只需要索引值, 可忽略之后的存储值, 如下:

如果需要对 seasons[ix] 进行修改, 可使用上述代码. 使用嵌套的 for 循环, 可简单实现矩阵结构的处理, 如下:

7.4 slice 变量的尺寸修改
从之前的讨论中可知,slice 通常比下层数组更小, 如:

其中 start_length 为 slice 的长度, 而 capacity 通常是下层数组的长度, 这里有一种方法, 可使 slice 变更为最大尺寸 (capacity). 例如 slice1 = slice1[0:end], 其中 end 表示结束索引值 (下层数组的长度).
sl = sl[0:len(sl)+1] 可使 slice 尺寸加 1, 但 slice 尺寸的扩展, 不能超过下层数组的长度.
例 7.11 reslicing.go


另一个常见的示例:

7.5 slice 类型的复制与合并
为了给出 slice 的最大长度, 必须创建一个新的更大的 slice, 并可复制原始 slice 的数据, 以下代码将创建的一个副本, 同时新值将附加到原有值之后.
例 7.12 copy_append_slice.go

func append(s[]T, x …T) []T
append 函数可将零个或多个数值, 附加到 slice 中, 之后可返回实现合并的 slice, 同时类型也为 s 相同, 元素值类型也与 T 相同, 如果 s 的容量导致无法包含更多的数值, 则会分配一个新的更大的 slice, 并会将原有数值和附加值, 放入新 slice 中, 而新 slice 将引用另一个下层数组,append 函数通常都会成功, 除非 PC 机产生内存不足的问题.
如果需要将 slice y 附加到 slice x 上, 则需在 append 的形参列表中, 扩展出第二个形参, 如x = append(x, y…).
append 的应用很广泛, 如果需要完全控制相关处理, 可使用 AppendByte 函数:

func copy(dst, src []T) int
copy 函数可将一组类型为 T 的 slice 元素, 从源 slice 复制到目的 slice, 并覆盖掉目的 slice 的原有元素, 并能返回完成复制的元素个数, 这时源 slice 和目的 slice 的元素将重叠在一起, 而可复制的元素个数, 必须是源slice 和目的 slice 的最小存储单位, 如果源 slice 是一个字符串, 那么元素值的类型应为 byte, 如果需要对源slice 实现连续处理, 可在复制后, 给出 src = dst 语句.
7.6 字符串, 数组与 slice 的用法
7.6.1 从字符串中创建 slice
如果 s 是一个字符串 (等同于一个 byte 数组),c 是一个 byte slice, 可使用 c:=[]byte(s) 创建 c, 同时也可使用copy 函数,copy(dst []byte, src string), 甚至可使用 for-range 结构:
例 7.13 for_string.go

从上例可知,Unicode 字符将包含了 2 个字节, 而有些字符则会包含 3 个或 4 个字节, 如果出现错误的 UTF-8编码, 即使字符将设定为 U+FFFD, 但索引值只能提供一个字节的数据, 因此需进行转换 c:=[]int(s), 以使每个 int 类型中, 都可提供 Unicode 码, 即字符串的每个字符都可获得对应的整型值, 同时也可转换成 rune 格式r:=[]rune(s).
使用 len([]int(s)) 可获取字符串的字符个数, 但 utf8.RuneCountInString(s) 的执行速度更快.
一个字符串也可附加到一个 byte 类型的 slice 中, 如下:
7.6.2 从字符串中创建子串
substr := str[start:end] 可从 str 字符串中, 创建一个子串, 同时 start 和 end 提供了 str 字节数据的索引值,而 str[start:] 将使用 start 索引值至末尾索引值 (len(str)–1) 之间的字节数据, 创建一个子串,str[:end], 则可使用起始索引值 (0) 至 end 索引值之间的字节数据, 创建一个子串.
7.6.3 字符串与 slice 的存储
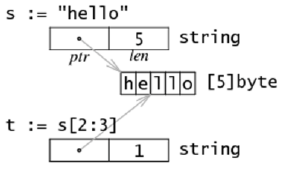
在内存中, 一个字符串将包含两个 word(16 个字节), 其中一个 word 包含了字串指针, 另一个 word 提供了字串长度, 如下图, 而字串指针在 Go 代码中不可见, 因此在大多数情况下,string 被视为一种数值类型, 也就是一个字符数组, 下图给出了字符串 string s = ”hello” 和子串 t = s[2:3] 的存储格式:
7.6.4 修改字符串的字符
在 Go 代码中, 字符串无法直接修改, 这意味着无法利用索引值, 对字符串进行左侧赋值, str[i] = ‘D’, 这时即使 i 是一个有效索引值, 也将产生一个错误:cannot assign to str[i].
为了实现字符串的修改, 首先需将字符串转换成一个 byte 数组, 之后基于索引值, 对数组进行修改, 再后 byte数组必须转换成一个新的字符串, 如下代码可将”hello” 修改为”cello”,
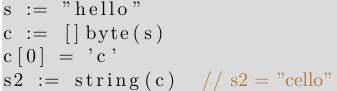
因此 slice 类型的字符串更容易使用.
7.6.5 byte 数组的比较函数
以下的 Compare 函数可返回两个 byte 数组的比较结果, 两个 byte 数组将以字母次序逐个比较元素值. 而返回结果为:
• 如果 a == b, 将返回 0
• 如果 a < b, 将返回-1
• 如果 a > b, 将返回 1

7.6.6 slice 和数组的搜索和排序
sort 包提供了搜索和排序的常用功能, 为了实现 int 类型 slice 的排序, 可导入 sort 包, 并调用函数 sort.Ints(arri),即 func Ints(a []int), 而 arri 为数组或 slice,Ints 函数可实现数组或 slice 的升序排列, 为测试排序结果, 可使用func IntsAreSorted(a []int) bool, 基于该函数的返回值 (true,false), 可判断排序是否成功.
如果元素类型为 float64, 可选择 func Float64s(a []float64), 如果元素类型为字符串, 可选择 func Strings(a []string).
为实现数组或 slice 的搜索, 必须首先完成数组或 slice 的排序 (因为搜索函数使用了二分搜索算法), 之后可选择 SearchInts(a []int, n int) int, 它可在 slice a 中搜索 n, 并可返回 n 的索引值, 而 float64 和 string 类型都有对应的函数:
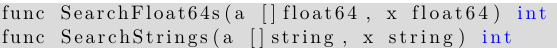
sort 包的更多细节, 可查看网页http://golang.org/pkg/sort/. 同时在 11.6 节中, 还将讨论 sort 包的用法, 以及自行实现一个搜索函数.
7.6.7 append 函数
在 7.5 节中引入了 append 函数, 以下将给出 append 的不同用法:


使用 slice 和 append 函数, 可调整元素的次序, 一个 slice 经常被称为矢量, 以适应数学应用的语境, 为了简化代码, 可为 slice 定义一个假名 vector, 例 10.11(method2.go) 给出了一个简单示例.
如果读者需要了解 Go 语言的复杂应用, 可查看 Eleanor McHugh 编写的包文件, 在以下网页中可找到这些包文件:
• http://github.com/feyeleanor/slices
• http://github.com/feyeleanor/chain
• http://github.com/feyeleanor/lists
7.6.8 slice 与垃圾收集
slice 需指向下层数组, 在之前的示例中, 下层数组都比 slice 大得多, 当 slice 与下层数组建立引用关系后, 下层数组将保存在内存中, 直到它不再需要, 因此有时会出现一类情况, 即程序存储的所有数据中, 只有一小部分被使用.
比如 FindDigits 函数, 它可将一个文件载入内存, 并搜索第一个出现的连续数字, 还可基于这些数字生成一个新 slice 并返回.

上述代码可返回, 文件包含的 []byte, 这是一个 slice, 由于 slice 需引用原始的下层数组, 这时 slice 的引用, 将导致垃圾收集器无法释放该数组, 同时之前的整个文件也必须保存在内存中.
为了处理该问题, 需在返回之前, 将有用信息复制到一个新 slice 中, 如下:


