一、检索
查找表所有的记录,*代表所有记录,2019jw__kscj是我的表名,一个记录学生成绩的表
navicat结果

SELECT * FROM `2019jw__kscj`
查找某列,例如学号xh
SELECT xh FROM 2019jw__kscj
查找某列的前几行,例如学号xh的前五行
SELECT xh FROM 2019jw__kscj LIMIT 5
也可以从任意行开始选取,例如:从第5行起的5条记录
SELECT xh FROM 2019jw__kscj LIMIT 5 OFFSET 4
展示某列的唯一值,例如课程名kcm
SELECT DISTINCT kcm FROM 2019jw__kscj
结果展示
二、mysql排序
根据某列进行排序,例如成绩cj
SELECT * FROM 2019jw__kscj ORDER BY cj
默认是升序,如图所示

如果想倒序,添加参数,DESC倒序
SELECT *FROM 2019jw__kscj ORDER BY cj DESC
三、过滤WHERE
选择某列等于某值
例如筛选课程名为公共管理学的记录
不等于用 !=
SELECT xh,hg FROM 2019jw__kscj WHERE kcm = "公共管理学"
筛选BETWEEN 介于
对于数值型变量而言
SELECT xh FROM 2019jw__kscj WHERE xh BETWEEN 17000000 AND 18000000
## %百分号 _下划线的用法
_下划线代表任意字符
某字段的值是以什么开头
例如查找学号以17开头的所有记录,即2017级学生

SELECT xh FROM 2019jw__kscj WHERE xh LIKE "17%"
某字段的值是包含指定字符
例如查找所有课程性质包含必修的记录
SELECT kclx FROM 2019jw__kscj WHERE kclx LIKE "%必修%"
选取某列的特定行 对于分类型变量
例如查找所有“高等数学”,"线性代数"课程的记录
SELECT xh,kcm FROM 2019jw__kscj WHERE kcm IN ("高等数学","线性代数")
四、函数
计数
SELECT COUNT(kcm) FROM 2019jw__kscj
最大值max 最小值min
SELECT xh,MAX(cj) FROM 2019jw__kscj
平均值avg
SELECT avg(cj) FROM 2019jw__kscj
根据某列平均值avg 即类似于python的分类汇总groupby
这里还添加了一个条件学号xh是17开头的
SELECT xh,AVG(cj) FROM 2019jw__kscj WHERE xh LIKE "17%"GROUP BY xh
连接函数CONCAT 将两列用字符串形式连接
jw_t_bzks_jbxx是原始表,xy,zy是其两列对应学院和专业,将其连接成为一个新列,列名为xyzy
SELECT CONCAT(xy,zy) AS xyzy FROM jw_t_bzks_jbxx
#SELECT DISTINCT CONCAT(xy,zy) AS xyzy FROM jw_t_bzks_jbxx ORDER BY xyzy DESC
#SELECT xh,sum(xf) FROM 2019jw__kscj WHERE xh = 18150055
#SELECT xh,sum(xf) FROM 2019jw__kscj WHERE xh = 18150055 AND hg = "是"
效果如下

五、联结
最后,我们试着解决一个问题。
表2019jw__kscj中有学号(xh)和绩点(jd),表mjcs中有学号(xh)和进图书馆次数(cs)。两个表的数据都非常大,如果要将它们都放入一个表内,将会占用大量储蓄空间,所以我们应该怎么匹配这些数据呢?
#利用xh列联结两个表的jd和cs
SELECT 2019jw__kscj.xh,jd,cs FROM 2019jw__kscj,mjcs WHERE 2019jw__kscj.xh = mjcs.xh
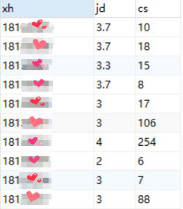
这里首先请大家关注WHERE子句的条件是两个表中共同列xh相等,写做(表.xh),xh的前面要标注出处。第二点关注前面的列名要对称,jd对应第一个表2019jw__kscj,cs对应表mjcs。
