代码很简单,实现一个学习
y= ax + b 的过程 其中 a=1.1 b=3,但是只许运用一个densy节点,2个权重
原来学 tensorflow 感觉学的很粗糙,下边一句一句来理解,
import tensorflow as tf
xlist=[[0],[1],[2],[3],[4],[5]]
ylist=[]
for item in xlist:
ylist.append(item[0]*1.1+3)
print(xlist)
print(ylist)
#截止到这里,我们只是在准备数据集
#搭建神经网络
model =tf.keras.Sequential(
tf.keras.layers.Dense(1,input_shape=(1,))
)
#中的网络结构图
model.summary()
# mse 均方差
model.compile(optimzer="adam",loss='mse')
# model.fit 的返回值 是一个 history对象
# history对象包含两个参数
#fitres.history 它是一个损失函数列表
#fitres.epoch 是一个训练步数的列表
#下边实现的功能就是当 loss 小于 0.01的时候才停止训练
fitres =model.fit(xlist,ylist,epochs=100)
while history.history["loss"][-1]>0.01:
history = model.fit(xlist, ylist, epochs=100)
print("fit的返回值",(history.history["loss"]))
print("fit的返回值",(history.epoch))
res=model.predict((5,))
print(res)
当只有一个节点时训练了
训练的总次数 2900
1, 2900
10, 2900
当我们增加模型的复杂度时,会让训练的步数相应减少,但是每一步的耗时又回增加,自然而然,复杂的模型,能够表示的 知识越多
更复杂的网络
#关于 densy 层 全连接层的介绍
#一般情况下第一层是 全连接层 或,平铺层, 第一层需要指明输入参数的形状
#当 sequenial 的层数 大于 1层的时候, 需要使用 [] 列表来存放层 ,间隔
#除了 最后一层不需要加激活函数外,其他层都需要加激活函数,来提升网络拟合能力
model =tf.keras.Sequential([
tf.keras.layers.Dense(10,input_shape=(1,),activation='relu'),
tf.keras.layers.Dense(10,activation='relu'),
tf.keras.layers.Dense(1)
]
)
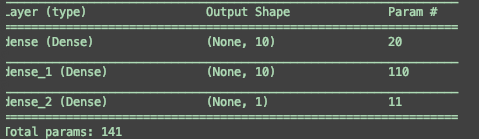
神经网络中总的权重个数 等于
求和count(n-1)count(n) + count(n)
count(0)= 输入数据的维度dim, 在本例中为1
所以 这个神经网络中的
参数个数为 (101+10 )+ 1010+10 + 101+1 =141 个参数
#mse 是均方差 损失函数
model.compile(optimzer="adam",loss='mse')
#当我们求的值很小的时候,我们应该考虑扩大 损失函数
#采取交叉熵, 通常当输出是一个概率值的时候采用 交叉熵最好
model.compile(optimzer="adam",loss='binary_crossentropy')
当然了损失函数通常只会影响收缩的快慢,而对最终的结果影响较小
下边我们自定义一个问题
输入一个【x,y】 当x y都是奇数的时候,输出【1,0】
否则输出【0,1】
import tensorflow as tf
tf.__version__
#我们来实现一个 判别奇偶数的判别器(0到10000),当数组中的数字两个都是奇数的时候我们就判断它是 1
#否则就判断他是 0
#数据举例
train_data=[[1,1],[3,2]]
train_aim=[[1,0],[0,1]]
import random
#生成更多的随机数
for index1 in range(1000):
data1=random.randint(0,10000)
data2=random.randint(0,10000)
aim1=[0,1]
if data1%2!=0 and data1%2!=0:
aim1=[1,0]
data1=data1/10000
data2=data2/10000
train_data.append([data1,data2])
train_aim.append(aim1)
showlist=[train_data[:10],train_aim[:10]]
showlist
# In[11]:
# sigmoid 可以把输出激活到 0 到 1之间
model=tf.keras.Sequential([
tf.keras.layers.Dense(100,input_shape=(2,),activation='relu'),
tf.keras.layers.Dense(300,activation='relu'),
tf.keras.layers.Dense(300,activation='relu'),
tf.keras.layers.Dense(300,activation='relu'),
tf.keras.layers.Dense(2,activation="softmax")
])
#模型超参数 选择,
#优化器 亚当
#损失函数 binary_crossentropy 交叉熵损失函数,通常用来 计算 输出在0到1 之间
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc'])
# In[ ]:
hisres=model.fit(train_data,train_aim,epochs=10)
while hisres.history['acc'][-1]<0.9:
hisres=model.fit(train_data,train_aim,epochs=100)
model.save("/Users/limengkai/Downloads/classjiou.h5")
need_be_predict=[[11,12],[11,10],[2,2],[1,1],[11,11],[99,99]]
res=model.predict(need_be_predict)
print("预测结果是",res)
# In[ ]:
如果没有
data1=data1/10000
data2=data2/10000
则会造成,acc无法提高,训练无效
原因,由于神经网络是基于误差反馈迭代的,当输入很大,但是输出很小的时候,输出的误差相应也会很小,这样就会造成每次纠正的误差及其小,
最后导致神经网络无法正常迭代
修改后可以正常训练
#训练模型
hisres=model.fit(train_data,train_aim,epochs=10)
#指定条件终止模型
while hisres.history['loss'][-1]>0.001:
hisres=model.fit(train_data,train_aim,epochs=100)
#保存模型
model.save("/Users/limengkai/Downloads/classjiou.h5")
#使用模型预测
res=model.predict(need_be_predict)
#加载训练好的模型
model=tf.keras.models.load_model("/Users/limengkai/Downloads/classjiou.h5")
当这个
~/.keras/datasets/fashion-mnist
目录下存在文件的时候,就 不会 再去网上下载
ps -ef | grep python
pkill -9 python
#在测试集上测试 模型
res=model.evaluate(test_image,test_lable)
#返回值是一个 list [loss,acc]
while res[-1]<0.95:
model=train_model(model)
res=model.evaluate(test_image,test_lable)
#在这个函数下边可以查看所有的 tensorflow的优化器
tf.keras.optimizers
tf.keras.optimizers.Adam(并且可以为他设置参数)
还有很多优化器
shiht+tab 查看方法提示
直接在训练过程中加入验证
model.fit(train_image,
train_lable,epochs=1
validation_data=(test_image,test_lable)
)
也可以 不手动 区分测试集合,直接从train中按照比例划分出测试集合
#选取百分之20来作为训练的测试集
fitres=model.fit(train_image,
train_lable,epochs=1,
validation_split=0.2
)
fitres是一个history对象,包含两个属性
fitres.history 又包含很多属性最基础的是一个 loss,还会根据compile的不同,增加 acc 以及 val_loss ,val_acc
fitres.epochs是一个训练次数的列表,不累计,每次调用fit,该值都会重置
可视化
res=model.evaluate(test_image,test_lable)
plt.plot(fitres.epoch,fitres.history['acc'],label='acc')
plt.plot(fitres.epoch,fitres.history['val_acc'],label='val_acc')
plt.legend()
fitres.history.items()
output:
dict_items([('loss', [0.4265994958480199]), ('acc', [0.84933335]), ('val_loss', [0.403786190700531]), ('val_acc', [0.8566])])
以上我们主要是介绍了,sequential
我们可以清晰的看到sequential是一个顺序模型
但是当我们计算图不是顺序的,而是图结构的时候,sequential模型,就不是那么适合了
如果我们要判断两个图片是不是同一个类型,那么这个神经网络应该得到两个图片输入,一个逻辑返回值,那么我们应该怎么做呢,
下边让我们来看看api式模型结构,
import tensorflow as tf
from tensorflow.keras.layers import *
#接下来,我们搭建一个神经网络,来判断两个图片是不是同一个类型
#很明显,这个神经网络应该具有两个图片的输入,和一个逻辑判断值,
#但是我们之前讲过的sequential模型,只有一个输入,这个时候可能会有小伙伴说,我们先把图片进行拼接
#然后再进行学习不就可以了嘛,但是随之情况越来越复杂,手动拼接输入输出,会变得十分麻烦,
#这时候 tensorflow 为我们提供了,api式的网络模型,每一层都可以多次和其他层进行运算
#创建两个图片输入
imginput1=tf.keras.Input(shape=(28,28))
imginput2=tf.keras.Input(shape=(28,28))
#通过平铺层,把图片展开
flatten1,flatten2=Flatten()(imginput1),Flatten()(imginput2)
#连接两个 输入
connect_img1_2=concatenate([flatten1,flatten2])
d1=Dense(32,activation='relu')(connect_img1_2)
d1=Dense(32,activation='relu')(d1)
d1=Dense(32,activation='relu')(d1)
output1=Dense(1,activation='sigmoid')(d1)
model=tf.keras.Model(inputs=[imginput1,imginput2],outputs=output1)
model.summary()
#至此一个 api tensorflow模型就被搭建好了
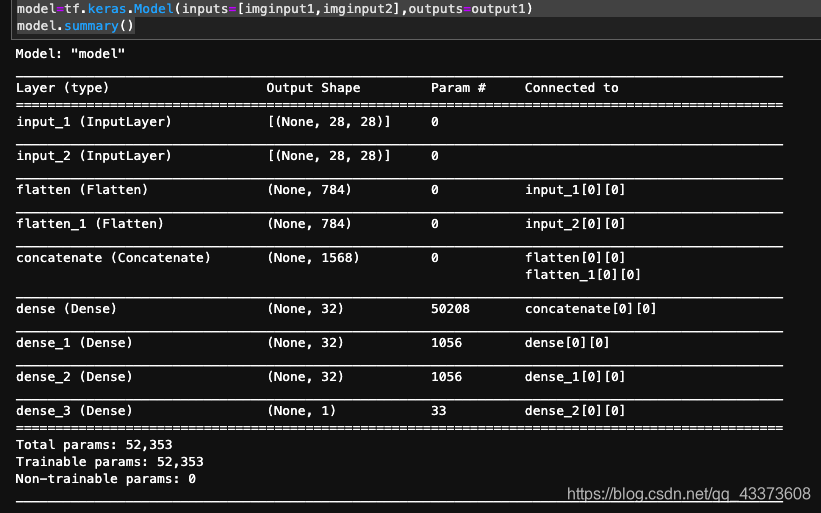
这就是一个简单的,tensorflow api模型,希望读者,至此可以好好体会一下 sequential 与api的区别,并在以后的实际运用中选择自己需要怎样的模型。
tensorflow拥有什么样的优点呢,cpu,gpu 移动设备手机tubor加速,
不只是适用于深度学习,对于各种各样的数值计算来讲都是很棒的工具。
通常情况下,集成度越高的软件,运行效率越低,
在一开始tf 低版本,确实存在这样的问题,后来tf 优化了计算编译器, XLA (accelerate linear algebra) 加速线性代数,整体提高训练速度 58 倍,
即便我们是使用 python 书写低速的代码, 也只是脚本部分会缓慢一点点, 真正的计算部分,效率是基本上不输与大牛写的c语言代码的。更别提是我们直接用c写的低效率代码了.
tf1 架构

tf2 架构
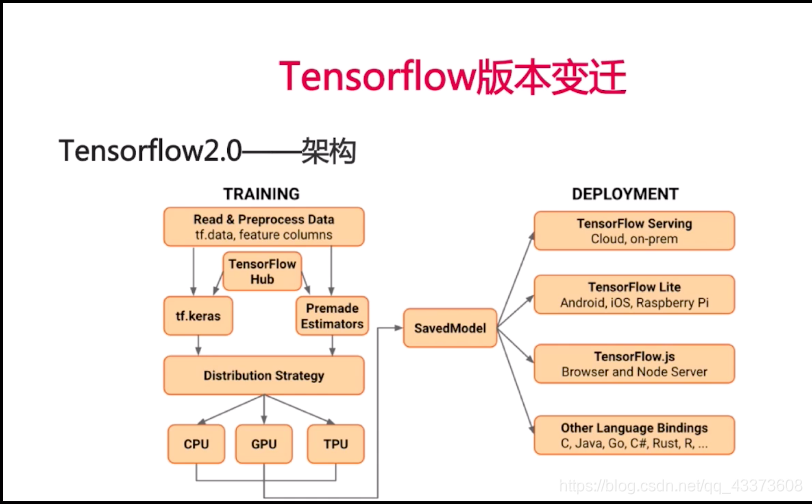
2.0的架构图,不仅仅是一个软件架构图,更是指导人工智能产品开发的一个规范图,
对比与1.0架构图,很明显,cpu gpu tpu 旁边没有了,手机以及,js,而是移动到了右侧,因为我们是不需要在手机端以及网页上进行训练的,
从左上角开始看,
training :
tf.hub -> tf.keras -> distribution -> cpu gpu tpg -> savemodel
deployment:
savemodel -> tf server ,tf lite ,tf js ,other language
tfhub是一个模型市场,会用各种科研工作者把自己的训练好的model 放在上面,我们只需要利用 tf.keras加载模型,二次训练模型迁移,减少训练时间,即可进行部署.


1.0是默认静态图,
2.0是默认动态图
静态图训练速度略快,但也不是很强的优势
但是动态图支持在训练过程中修改图结构,所以2.0强于1.0,在入门中2.0调理更清晰
2.0中添加了新型的激活函数,以及droupout,
selu 以及alphadroupout
selu 自带参数批归一化
一层相当于两层
model.add(Dense(nodelist[layerindex%len(nodelist)],activation='relu'))
model.add(BatchNormalization())```bash
基本相当于,
但是selu内部做了更多的优化,所以我们还是直接使用selu更好
model.add(Dense(nodelist[layerindex%len(nodelist)],activation='selu'))
另一个新型激活函数 swish
alphadroupout 1.保证均值和方差不发生改变,2.归一化性质不再改变
