正则表达式是用来匹配字符串的,针对文本内容的文本过滤工具里所使用的.
例如 grep sed awk等等
通配符: 针对文件名称
正则表达式: 针对文本内容
基本正则表达式
-
字符匹配
[:alnum:]:字母与数字字符
[:alpha:]:字母
[:ascii:]:ASCII字符
[:blank:]:空格或制表符
[:cntrl:]:ASCII控制字符
[:digit:]:数字
[:graph:]:非控制、非空格字符
[:lower:]:小写字母
[:print:]:可打印字符
[:punct:]:标点符号字符
[:space:]:空白字符,包括垂直制表符
[:upper:]:大写字母
[:xdigit:]:十六进制数字 -
匹配次数
* : 匹配前面的字符任意次数
.* : 匹配任意长度的字符
\? : 匹配前面的字符0或1次
\+ : 匹配前面的字符至少1次
\{m\} : 匹配前面的字符m次
\{m,n\} : 匹配前面的字符至少m次,最大n次
\{0,n\}: 匹配前面的字符至多n次
\{m,\}: 匹配前面的字符至少m次 -
位置锚定
^:行首锚定,用于模式的最左侧
$: 行尾锚定,用于模式的最右侧
^PATTERN$ :用于模式匹配整行内容
^$ : 匹配空行
\b | \< : 词首锚定,用于单词模式的左侧
\b | \> : 词尾锚定,用于单词模式的右侧
\<PATTERN\> : 匹配整个单词
针对文本:
#
# /etc/fstab
# Created by anaconda on Wed Feb 5 10:47:08 2020
#
# Accessible filesystems, by reference, are maintained under ‘/dev/disk’
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=f0bd0552-b73f-48cb-aef2-1a1ca6bdc06f /boot xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
grep命令:文本过滤工具
grep [reg] object
-
匹配空行: ^$
[root@test tmp]# grep “^$” 11.txt -
匹配以#开头的行 : ^#
[root@test tmp]# grep “^#” 11.txt -
匹配包含数字的行: [1-9]* | [[:digit:]*]
[root@test tmp]# grep “[1-9]+” 11.txt
- 分组
\(gp\) : 将一个或多个字符捆绑在一起;当作一个字符
\(xy\)*ab --> 文本中xy出现任意次数和ab字符
[root@test tmp]# grep "\(xy\)*ab" 12.txt
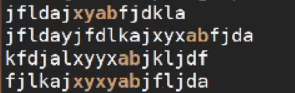
\(xy\)\+ab --> 文本中xy出现至少一次和ab字符
[root@test tmp]# grep "\(xy\)\+ab" 12.txt

Note:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部变量中,
这些变量存储在 \1 \2 \3 … 并且可以在本次正则中进行引用
\1 : 从最左侧起,第一个括号中匹配到的内容
\(ab\+\(xy\)\)
\1: ab\+\(xy\)
\2: xy
扩展的正则表达式
-
字符匹配
-
次数匹配
* : 匹配前面的字符任意次数
.* : 匹配任意长度的字符
? : 匹配前面的字符0或1次
+ : 匹配前面的字符至少1次
{m} : 匹配前面的字符m次
{m,n} : 匹配前面的字符至少m次,最大n次
{0,n}: 匹配前面的字符至多n次
{m,}: 匹配前面的字符至少m次 -
位置锚定:
^:行首锚定,用于模式的最左侧
$: 行尾锚定,用于模式的最右侧
^PATTERN$ :用于模式匹配整行内容
^$ : 匹配空行
\b | < : 词首锚定,用于单词模式的左侧
\b | > : 词尾锚定,用于单词模式的右侧
<PATTERN> : 匹配整个单词 -
(gp) : 将一个或多个字符捆绑在一起;当作一个字符
(xy)*ab --> 文本中xy出现任意次数和ab字符Note:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部变量中,
这些变量存储在 \1 \2 \3 … 并且可以在本次正则中进行引用\1 : 从最左侧起,第一个括号中匹配到的内容 (ab+(xy)) \1: ab+(xy) \2: xy
练习题
1.显示/proc/meminfo文件中以大小s开头的行(2种方式)
2.显示/etc/passwd文件中不以/bin/bash结尾的行
4.如果root用户存在,显示其默认的shell程序
5.找出/etc/passwd中的两位或三位数
6.显示/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面存非空白字符行
7.找出“netstat -tan"命令的结果中以’LISTEN’后跟0、1或多个空白字符结尾的行
8.添加用户bash、testbash以及nologin(其shell为/sbin/nologin),然后找
出/etc/passwd文件中用户名同shell名的行
9.显示/etc/passwd文件中ID号最大用户的用户名
答案在下一章
