”ART’s Quick Compiler:an unofficial overview“
Matteo Franchin LCA15, February 2015
看了这个关于ART的PPT,记录一下。
ART编译器有两种一种叫做Portable(后端好像是llvm),还一种就是常用quick,下文介绍基于quick。
ART不仅仅编译执行,也会解释执行(跟dalvik基本上一样把)
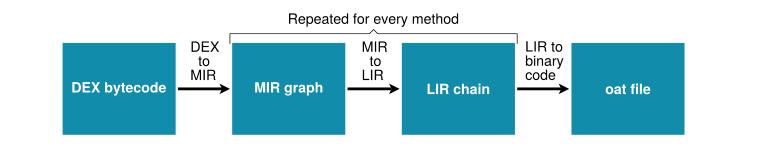
Java method is the compilation unit for the Quick Compiler.
Quick编译器的编译单元是一个java方法

dalvikvm64 calls the compiler, dex2oat, to generate OAT file in /data/dalvik-cache/arm64.
64位虚拟机调用编译 dex2oat方法 来生成一个oat文件,保存在/data/dalvik-cache/arm64目录下
dex2oat uses several threads to compile all the methods.
DEX bytecode:
register-based variable length instructions (≥ 2 bytes).
dex指令是基于寄存器的,可变长度的(>2字节,16位或32位)
32-bit, untyped virtual registers (vregs): v0-v65535.
dex文件使用的是32位的虚拟寄存器V0-V65535 与机器码使用的Rx物理寄存器不同
64-bit values stored in consecutive pairs of registers.
64位的值存储于2个相邻的32位虚拟寄存器中
See https://source.android.com/devices/tech/dalvik/dalvik-bytecode.html
MIR: Mid-level Intermediate Representation:
Methods as control-flow graphs made by sequences of MIR nodes
方法变成了由MIR序列组成的控制流程图?
(organised in basic blocks).组织形式是BB基本块,基本块==方法?
Faithful to DEX bytecode: 1 DEX op → 1 MIR node.
dex操作与MIR一一对应
+ pseudo MIR nodes for annotation purposes.
伪MIR节点为了注释的目的???
+ extended MIR nodes for optimisation purposes.
扩展的MIR节点为了优化的目的
MIR指令不过是把DEX指令给解释一下 拆分一下 包装一下,为了LIR服务
LIR: Low-level Intermediate representation:
Methods as sequences of LIR nodes.
Faithful to instruction set: 1 instruction → 1 LIR node.
+ pseudo LIR nodes for annotation purposes.
Different LIR enums for ARM, ARM64, x86, MIPS.
E.g. NewLIR2(kA64Mov2rr, rw0, rw1) for mov w0, w1.
LIR指令跟机器指令似乎就比较接近了
OAT file:
Cached in /data/dalvik-cache/arm64.
Contain binary executable code.
Contain source DEX bytecode.
包括了完整DEX代码,因为可能还会需要到?有些方法要解释执行。
Contain metadata for runtime (GC, deoptimization).
From DEX bytecode to MIR nodes:
DEX ops parsed and added as MIR nodes to blocks.
Blocks split at branches/labels: become basic blocks.
Middle-End passes: SSA, type inference, redundant checks elimination.
Pass engine to manage passes.
From MIR to LIR:
Physical regs are “assigned” at this stage.
virtual regs promoted to callee-saved physical regs.
虚拟寄存器变成了物理寄存器,Vx变成了Rx
MIR translated to LIR (big switch statement): caller-saved regs allocated for temps.
LIR optimisation passes:Load hoisting.Load-store elimination.
From LIR to native:
Fixups (branches resolved, instructions replaced if args out-of-range).
LIR translated to binary code.
Global (inter-method) fixups.
The good:
ART is typically 80% faster than Dalvik (Google I/O 2014 - The ART
Runtime).
Quick compiler is quick indeed (on target device must be able to produce
hundreds of MBs in minutes).
The bad:
LIR, MIR are sequences of nodes, rather than graphs:
Difficult to detect dead code and perform code motion.
Difficult to detect instructions sequences (and replace them with better ones).
MIR and LIR are quite different representations: difficult to share
optimisation passes among the two.
suspend-points

What are suspend-points?
1:Checks inserted in generated code to ensure Java threads stop executing
spontaneously when requested to do so.
2:Points of consistency between native-execution, runtime and
interpreted-execution.
好像就是主要用于GC和中断/debug分析
机器码实现:
