1、isin()
作用:isin()接受一个列表,判断该列中元素是否在列表中。
(1)如果是一个序列或者数组,那么判断该位置的值,是否在整个序列或者数组中
import pandas as pd
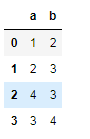
df = pd.DataFrame({'A':[1,2,3],'B':['a','b','f']})
df.isin([1,'2','5','f'])
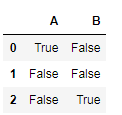
(2)对pd中某一列的值做判断
df['C'] = [7,8,9]
df.C.isin([7,9,10])

2、Numpy常见运算 - np.around、np.floor、np.ceil、np.where
np.where()
(1)np.where(condition,x,y):满足条件(condition),输出x,不满足输出y。
import numpy as np
condition = np.arange(10)
np.where(condition>5,1,0)
>>>
array([0, 0, 0, 0, 0, 0, 1, 1, 1, 1])
(2)np.where(condition):只有条件 (condition),没有x和y,则输出满足条件 (即非0) 元素的坐标。
import numpy as np
a = np.array([2,4,6,8,10,11])
np.where(a>5) #返回索引
>>>
(array([2, 3, 4, 5]),)
a[np.where(a>5)] #等价于a[a>5]
>>>
array([ 6, 8, 10, 11])
np.around: 返回四舍五入后的值,可指定精度。
用法:around(a, decimals=0, out=None)
参数;a 输入数组,decimals 要舍入的小数位数。 默认值为0。 如果为负,整数将四舍五入到小数点左侧的位置
n = np.array([-0.746, 4.6, 9.4, 7.447, 10.455, 11.555])
np.around(n,decimals = 1)
>>>
array([-0.7, 4.6, 9.4, 7.4, 10.5, 11.6])
np.floor : 返回不大于输入参数的最大整数。 即对于输入值 x ,将返回最大的整数 i ,使得 i <= x。 注意在Python中,向下取整总是从 0 舍入。
n = np.array([-1.7, -2.5, -0.2, 0.6, 1.2, 2.7, 11])
np.floor(n)
>>>
array([-2., -3., -1., 0., 1., 2., 11.])
np.ceil 函数返回输入值的上限,即对于输入 x ,返回最小的整数 i ,使得 i> = x。
n = np.array([-1.7, -2.5, -0.2, 0.6, 1.2, 2.7, 11])
np.ceil(n)
>>>
array([-1., -2., -0., 1., 2., 3., 11.])
3、tqdm():进度条配置
import time
from tqdm import tqdm
for i in tqdm(range(100)):
time.sleep(0.01)
4、unique()与nunique()
(1)unique()
统计list、series中的不同值的个数,返回的是list.
(2) nunique()
可直接统计dataframe中每列的不同值的个数,也可用于series,但不能用于list.返回的是不同值的个数.
df=pd.DataFrame({'A':[0,1,1],'B':[0,5,6]})
print(df.nunique())
5、sort_values()函数用途
pandas中的sort_values()函数原理类似于SQL中的order by,可以将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序。
用法:DataFrame.sort_values(by=‘##’,axis=0,ascending=True, inplace=False, na_position=‘last’)
df=pd.DataFrame({'col1':['A','A','B',np.nan,'D','C'],
'col2':[2,1,9,8,7,7],
'col3':[0,1,9,4,2,8]
})
print(df)
df.sort_values(by=['col1'],na_position='first')
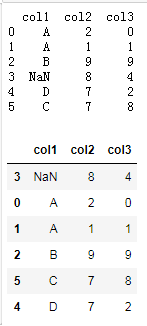
6、enumerate
用法:enumerate(sequence, [start=0])
参数:sequence – 一个序列、迭代器或其他支持迭代对象。start – 下标起始位置。
返回值:返回 enumerate(枚举) 对象。
seq = ['one', 'two', 'three']
for i, element in enumerate(seq):
print(i,element)
>>>
0 one
1 two
2 three
7、广义表head与tail的用法
df = pd.DataFrame({'A':[1,2,3],'B':[4,5,6]})
print(df.head(1))
print(df.tail(1))

8、pd.drop_duplicates()
通过SQL中关键字distinct的用法来理解,根据指定的字段对数据集进行去重处理。
用法:DataFrame.drop_duplicates(subset=None, keep=‘first’, inplace=False)
参数:
subset–根据指定的列名进行去重,默认整个数据集
keep–可选{‘first’, ‘last’, False},默认first,即默认保留第一次出现的重复值,并删去其他重复的数据,False是指删去所有重复数据。
inplace–是否对数据集本身进行修改,默认False
df=pd.DataFrame({
'a':[1,2,4,3,3,3,4],
'b':[2,3,3,4,4,5,3]
})
df.drop_duplicates(['a'],keep='first') #根据a列进行去重