Request库
本节目标:掌握定向网页爬取和解析的基本能力
简单的概括Request库的作用:把网站看作是一个对象,发送一个request请求,这个请求可以用一些参数修饰(例如定制头部),返回一个response对象,接着可以用访问属性的方式获取网站的头部信息、编码格式、网页内容等,response对象是后续网页解析的基础。
一、Requests库的主要方法-get():
1、格式


2、Response对象的属性:
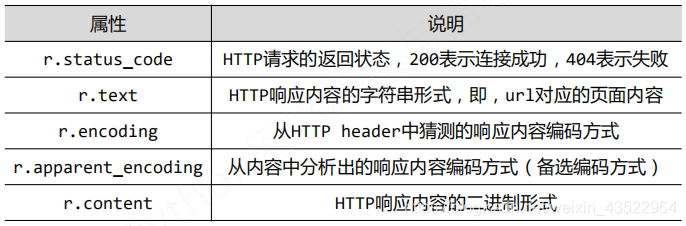
其中text返回的是字符串格式,content返回的是字节流。
补充:r.headers返回头部信息。
关于编码→r.encoding:如果header中不存在char-set,则认为编码为ISO‐8859‐1, r.text根据r.encoding显示网页内容。r.apparent_encoding:根据网页内容分析出的编码方式。
3、异常处理
Response.raise_for_status( )
4、通用代码框架

request库的其他方法简介
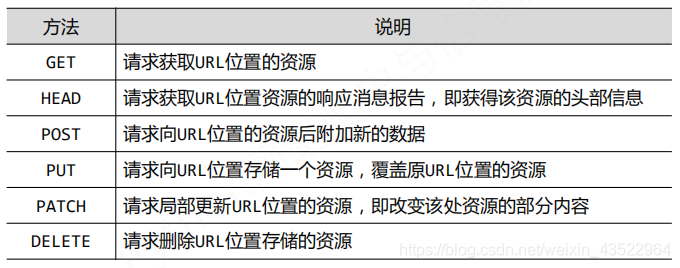
Patch局部更新解释:假设URL位置有一组数据UserInfo,包括UserID、UserName等20个字段需求:用户修改了UserName,其他不变。采用PATCH,仅向URL提交UserName的局部更新请求采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除。所以,PATCH的最主要好处是节省网络带宽。
二、request.post方法
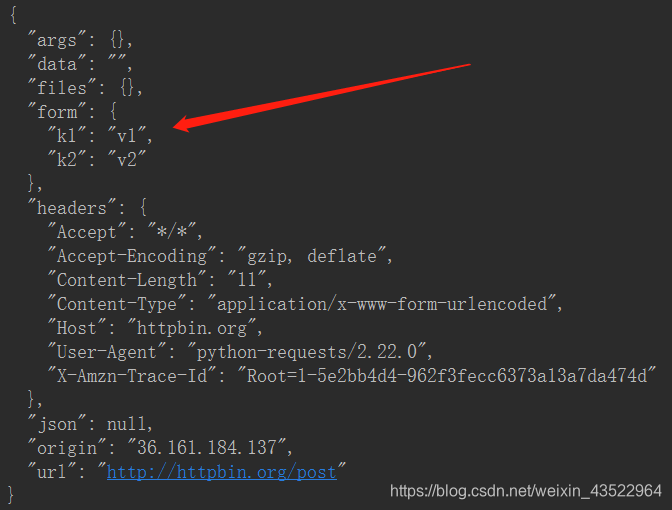
Post一个字典,自动编码成表单的形式。字符串编码成data属性:
payload={k1:”v1”, k2:”v2”}
r=request.post(url=’http://httpbin.org’, data=payload)
Print(r.text())
三、访问的控制参数
params:字典或者字节序列(字符串编码后就是字节序列,类型为bytes),作为参数追加到url中。
3.1 cert : 本地SSL证书路径.
3.2 data: 字典、字节序列或者文件对象,一般与post方法结合,作为推送的数据,若为字典则构成form域,若为str则构成response的data域.
3.3 json:json格式数据,和data类似都是作为response的一个域.
3.4 headers : 字典,用于定制http访问头部,例如设置代理名称.
3.5 cookies:字典格式.
3.6 auth:元组,支持认证.
3.7 files:字典类型,传输文件.
3.8 timeout:设定超时时间,单位为秒.
3.9 proxies:字典类型,设定访问代理服务器.
3.10 allow_redirects : True/False,默认为True,重定向开关.
3.11 stream : True/False,默认为True,获取内容立即下载开关.
3.12 verify : True/False,默认为True,认证SSL证书开关.
测试代码:request库学习
