首先,我们先建立一个有3000000条数据的数据库文件,格式如下
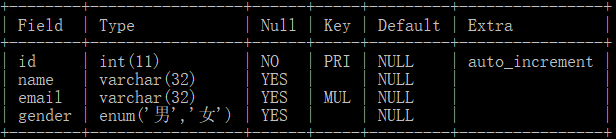
为了操作的便利,我们用Python代码来创建数据文件,py代码如下:


import pymysql import random conn = pymysql.connect( host = 'localhost', database = 'userinfo', user = 'root', password='', charset='utf8' ) cursor = conn.cursor() for i in range(1000001,3000000): name = str(i) emaile = str(i)+'@qq.com' gender = random.choice(['男','女']) sql="insert into user(name,emaile,gender) values('%s','%s','%s');"%(name,emaile,gender) print(i) cursor.execute(sql) conn.commit() cursor.close() conn.close()
索引
索引是一个表的目录,在查找目标前可以现在目录文件中查找索引的位置,以此快速定位查询数据。对于索引来说,会保存在另外的文件当中。
索引的种类
- 普通索引:仅仅加速查询
- 唯一索引:加速查询,但值是唯一的(可以为null)
- 主键索引:减速查询+唯一值+不能为null
- 组合索引:多个字段组成一个索引,专门用于组合搜索,效率要大于索引合并(后面会说到)
- 全文索引:对文本内容进行分词,进行搜索。
索引的增、删、改、查
下面的语句是MySQL里如何创建、删除和查询已有的索引
还可以创建唯一索引,就是把index前增加关键字unique就可以了
create unique index 索引名 on table(字段); drop unique index 索引名 on table;
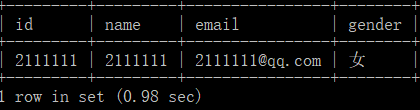
我们先看一下没有建立所以的时候的效果,执行一下下面的代码

select * from user where email='[email protected]';
看看时间
如果我们对emaii字段添加一个索引,重新进行查询
create index ix_email on user(email); select * from user where email='[email protected]';
再看看时间
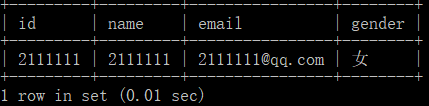
是不是快的多(这个0.01已经是大概的时间了),并且数据的子样也不是非常多。如果数据量非常大的话,效果会好得多。
索引形式
我们常用的索引的类型有两种:Hash和Btree:InnoDB和MyISAM默认的索引是Btree索引,而Memory默认的索引是Hash索引。
Hash索引是把字段里的数据经过hash转换后放新的文件中,hash值对应的还有数据的存储地址,我们在搜索数据的时候先从hash中定位到数据的地址然后从数据库中取出相应数据。但是Hash表中数据的存储顺序和数据库中的存储顺序是不一定相同的,所以在相较于取但一值来说,进行一个区间数据的索引就会耗时比较长。
Btree索引是以一种类似于二叉树的方式来进行数据存储,所以如果是2**(i-1)个数据最多只需要i次索引就可以获得所需要的数据。
二者的区别
1. hash索引查找数据基本上能一次定位数据,当然有大量碰撞的话性能也会下降。而btree索引就得在节点上挨着查找了,很明显在数据精确查找方面hash索引的效率是要高于btree的;
2. 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;
3. 对于btree支持的联合索引的最优前缀,hash也是无法支持的,联合索引中的字段要么全用要么全不用。提起最优前缀居然都泛起迷糊了,看来有时候放空得太厉害;
4. hash不支持索引排序,索引值和计算出来的hash值大小并不一定一致。
覆盖索引
我们在上面的user表里已经存在了两个索引:id和email,我们进行下面的索引
select id from user where id =111; select email from user where email='111';
在这里我们只是使用索引文件而没有进行数据库的访问,这个过程就叫做覆盖索引。
当发起一个索引覆盖查询时,在explain的extra列可以看到using index的信息。
索引合并
我们的user表里存在id和email两个索引,那么可以把这两个索引联合起来使用
select * from user where id=111 and email = '[email protected]';
索引合并就是把单个字段的索引合并起来来使用。如果是联合索引,会有一个叫最左前缀匹配的现象。这个最左前缀匹配我们在后面会讲到。但是索引合并的效率没有联合索引高。至于要用联合索引还是索引合并就要以具体的使用环境来定。
索引可以提高命中的效率,但是并不是创建的索引越多越好,因为虽然能提高查询的消耗时间,但是对于增、删、改的时候,都会增加消耗的时间。所以,具体怎么创建索引好以业务为主。如果某一个自动需要频繁的查询操作,就可以创建索引。
索引的命中
------------恢复内容开始------------
今天我们来学习一下MySQL的索引
首先,我们先建立一个有3000000条数据的数据库文件,格式如下
为了操作的便利,我们用Python代码来创建数据文件,py代码如下:
import pymysql import random conn = pymysql.connect( host = 'localhost', database = 'userinfo', user = 'root', password='', charset='utf8' ) cursor = conn.cursor() for i in range(1000001,3000000): name = str(i) emaile = str(i)+'@qq.com' gender = random.choice(['男','女']) sql="insert into user(name,emaile,gender) values('%s','%s','%s');"%(name,emaile,gender) print(i) cursor.execute(sql) conn.commit() cursor.close() conn.close()
索引
索引是一个表的目录,在查找目标前可以现在目录文件中查找索引的位置,以此快速定位查询数据。对于索引来说,会保存在另外的文件当中。
索引的种类
- 普通索引:仅仅加速查询
- 唯一索引:加速查询,但值是唯一的(可以为null)
- 主键索引:减速查询+唯一值+不能为null
- 组合索引:多个字段组成一个索引,专门用于组合搜索,效率要大于索引合并(后面会说到)
- 全文索引:对文本内容进行分词,进行搜索。
索引的增、删、改、查
下面的语句是MySQL里如何创建、删除和查询已有的索引
还可以创建唯一索引,就是把index前增加关键字unique就可以了
create unique index 索引名 on table(字段); drop unique index 索引名 on table;
我们先看一下没有建立所以的时候的效果,执行一下下面的代码
select * from user where email='[email protected]';
看看时间
如果我们对emaii字段添加一个索引,重新进行查询
create index ix_email on user(email); select * from user where email='[email protected]';
再看看时间
是不是快的多(这个0.01已经是大概的时间了),并且数据的子样也不是非常多。如果数据量非常大的话,效果会好得多。
索引形式
我们常用的索引的类型有两种:Hash和Btree:InnoDB和MyISAM默认的索引是Btree索引,而Memory默认的索引是Hash索引。
Hash索引是把字段里的数据经过hash转换后放新的文件中,hash值对应的还有数据的存储地址,我们在搜索数据的时候先从hash中定位到数据的地址然后从数据库中取出相应数据。但是Hash表中数据的存储顺序和数据库中的存储顺序是不一定相同的,所以在相较于取但一值来说,进行一个区间数据的索引就会耗时比较长。
Btree索引是以一种类似于二叉树的方式来进行数据存储,所以如果是2**(i-1)个数据最多只需要i次索引就可以获得所需要的数据。
二者的区别
1. hash索引查找数据基本上能一次定位数据,当然有大量碰撞的话性能也会下降。而btree索引就得在节点上挨着查找了,很明显在数据精确查找方面hash索引的效率是要高于btree的;
2. 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;
3. 对于btree支持的联合索引的最优前缀,hash也是无法支持的,联合索引中的字段要么全用要么全不用。提起最优前缀居然都泛起迷糊了,看来有时候放空得太厉害;
4. hash不支持索引排序,索引值和计算出来的hash值大小并不一定一致。
覆盖索引
我们在上面的user表里已经存在了两个索引:id和email,我们进行下面的索引
select id from user where id =111; select email from user where email='111';
在这里我们只是使用索引文件而没有进行数据库的访问,这个过程就叫做覆盖索引。
当发起一个索引覆盖查询时,在explain的extra列可以看到using index的信息。
索引合并
我们的user表里存在id和email两个索引,那么可以把这两个索引联合起来使用
select * from user where id=111 and email = '[email protected]';
索引合并就是把单个字段的索引合并起来来使用。如果是联合索引,会有一个叫最左前缀匹配的现象。这个最左前缀匹配我们在后面会讲到。但是索引合并的效率没有联合索引高。至于要用联合索引还是索引合并就要以具体的使用环境来定。
索引可以提高命中的效率,但是并不是创建的索引越多越好,因为虽然能提高查询的消耗时间,但是对于增、删、改的时候,都会增加消耗的时间。所以,具体怎么创建索引好以业务为主。如果某一个自动需要频繁的查询操作,就可以创建索引。
索引的命中
索引是否命中决定了能否快速的获取搜索对象。如果没有命中索引,是达不到索引的效果的,我们要先看看前面提到的最左前缀匹配
最左前缀匹配
如果我们把多个字段联合成为一个索引,比方执行一下下面的代码建立一个name和email的联合索引
create index ix_name_emaile on user(name,email)
注意上面的代码里,name是在email的前面,如果用下面的索引方法是可以走索引的
select * from user where name='111'; select * from user where name='111' and email='[email protected]';
但是直接用email是不行的。
select * from user where email='[email protected]';
如果是多个字段(超过两个)的联合索引呢?比方是(列1,列2,列3),那么有下面几种情形:
where 1,2,3 where 1,3 where 1
上面三种情形是可以命中索引的,但是下面的就不行
where 2,3 where 3
所以,如果有些时候就需要用索引合并来替代联合索引。
影响到索引命中的几种情形
like通配符的使用
在条件中添加了通配符会影响到索引的使用
索引中添加函数
在条件中添加了函数,也会影响到索引的效率,如果必须通过一些函数来实现功能,可以将函数放在类似于Python的代码中操作sql语句来实现。
使用or
当or条件中有未建立索引的字段才索引失效,下面的几种情形还是会使用索引的
select * from user where id = 1 or email ='1'; select * from user where id = 1 or name= '1' and emaile= '1';
上面的第二条语句,因为id是索引,就会忽略掉第二条name不是索引,所以也是可以使用索引的。
类型不一致
索引字段对应的数据类型要和搜索的数据类型一致,(例子中的name不是索引,来演示下)
因为我们在定义表的时候规定了name是char类型,但是如果我们使用下面的语句也是可以的
select * from user where name=2222222;
我们在查询的时候把name给的条件是int,但是也是能查到相对应的数据的。
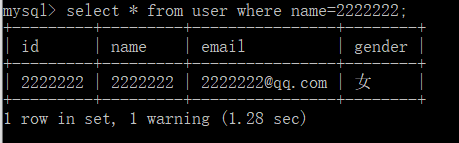
所以在使用检索的时候,一定要注意数据类型的一致性,即便不是索引,也会对遍历的时间有影响。
!= 、>的使用
如果在条件中用了上面的符号,也是不走索引的(主键除外)
order by
对索引列使用了排序,不走索引(主键除外)
其他注意事项
- 避免使用select *
- 尽量使用count(1)来替代count(*)
- 创建表的时候用char,不要用varchar(字符长度已知)
- 创建表的时候固定长度的字段放在前面
- 用组合索引来替代多个单列的索引(经常使用多个条件查询时)
- 对于散列值的情况(比方性别,只有两个值),不适合使用索引
- 在join连表的时候,也要类型一致(不一致的时候也是可以连上的,比方一个int,一个char)
- 尽量使用短索引
上面说的短索引点一下,比方是一个text类型,有非常多的字符,这个字段每行数据都做成索引是不现实的,常用的方法是把关键字提出来做成索引,整个过程是通过第三方工具来完成的。
如果一个列是text的话,直接创对这个字段建索引是会直接报错的,可以指定前多少个字符
create index xxx on tb(text(15));
就是把前15个字符提出来做成索引。
分页是个基本都要遇到的问题,在数据量比较大的时候不可能一次把所有的数据读上来,现在有几种常见的分页效果,为了简化流程,我们下面把id作为分页的依据。
方法一
最简单,只显示上一页和下一页,效果大概就是下面这样的,实际场所应该比较少见

这种方式最简单,只要知道当前页面的最大id和最小id,比方每页都显示20条数据,那么前一页后后一页的思路就是这样的(伪代码,,只说一下思路)
select * from table where id in(select id from table limit idmax,20); select * from table where id in(select * from table limit idmin-20,20);
方式二
只显示前几页,

在点击了某一页以后会出现下面的效果(百度上的效果)

这种方式就是固定显示10页,进可能保证当前页前面有5个button,后面有4个
方法三
显示前几页和最后一页(博客园首页)

后两种方法的实现思路差不多,都是在当前的maxId和minId基础上加上每页的id总数和页码差的乘积。然后再进行相关跳转
配合py代码,假设现在显示的是从200000开始的10条数据, select * from user where id>200000 limit 10; 就是记录好当前页的最大id或最小id max_id,min_id 下一页 select * from user where id>max_id limit 10 上一页 select * from user where id <min_id order by id desc limit 10 要是是那种 1.2.3.4........200的页面按钮,在第一页点击了第4个要怎么办 就要从上位的代码实现 if 跳转页面>现在页面 (跳转页面-现在页面)*页面显示条数 +id_max= 跳转数 select.....where id >跳转数 limit 10 还是基于当前页面的id来显示的分页方式。 如果是往前面跳转就是把上面的方式反过来
我们还可以通过执行计划来预判sql代码的执行效率在select的前面加上explain
explain select * from user;
返回了一个表

我们主要关注的是那个type的字段
性能从低到高一次为性能:all<index<range<index_merge<ref_or_null_ref_eq_ref<system/const
all 全表扫描 特别的如果有limit限制,则在赵奥后不再向下扫描 index 全索引扫描,对索引从头到尾进行扫描 其实index和all的速度差不多,但是如果索引列有重复的值,新建的索引文件行数就会略少一点,就能快一些 但是all如果扫第三列的话不光要在行上移动,还要在列上扫描 range 对索引列进行范围查找 注意这里是索引列 select * from t where name<111 range 包括 between and in > >= < <= 特别要注意!=和> index_merge 索引合并,使用多个单列索引进行搜索 select * from t where name ='111' or id in (11,12,13) ref 根据所索引查找一个或多个值 select * from user where email = '111' EQ_REF 连接使用主键或unique类型EQ这的就是唯一 const 常量 表最多有一个匹配行,因为只有一行,在这行的列值可以被优化器剩余部分认为是常数,const表很快,因为他们只读取一次。 system 系统,表只有一行数据(系统表),这是const链接类型的一个特例
我们在上一章大概提到过,MySQL有个功能,叫做慢日志记录,可以记录执行时间超过指定时长的sql代码
配置方法
直接改参数
先查一下变量
show variables like '%query%';
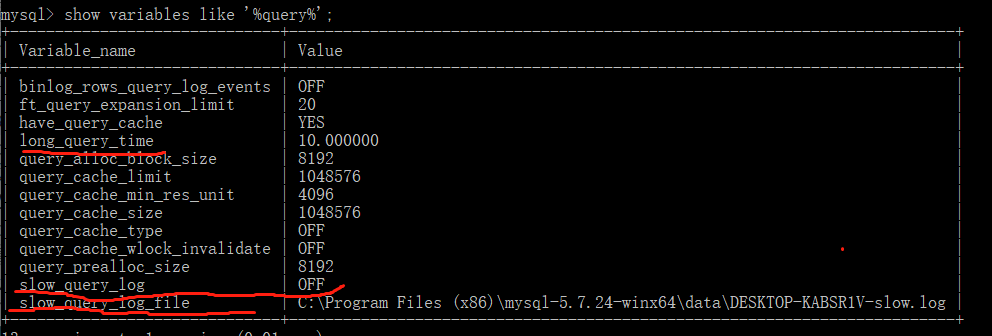
关注一下标出来的三个变量
long_query_time 表示指定时长,超过该时长的指令会被记录在日志中
slow_query_log 表示是否开启慢日志记录
slow_query_log_file 表示日志存储路径
我们把时长设置为1.0,并且启用日志记录
set global long_query_time=1.0; set global long_query_log=ON;
然后做一个超过1s的搜索
select * from user where name='1234567';
执行时间大概是1.7s

然后我们看一看日志文件
MySQL, Version: 5.7.24 (MySQL Community Server (GPL)). started with: TCP Port: 3306, Named Pipe: MySQL Time Id Command Argument MySQL, Version: 5.7.24 (MySQL Community Server (GPL)). started with: TCP Port: 3306, Named Pipe: MySQL Time Id Command Argument # Time: 2020-02-14T10:09:48.175254Z # User@Host: root[root] @ localhost [::1] Id: 6 # Query_time: 1.725777 Lock_time: 0.000797 Rows_sent: 1 Rows_examined: 3000000 use userinfo; SET timestamp=1581674988; select * from user where name='1234567';
可以发现有相关记录。
或者我们直接把配置文件里写上相关配置
long_query_time=1.0
slow_query_log=ON
slow_query_log_file=path
然后在启动MySQL服务时指定好相关配置文件的路径
mysqld --default-file='path'
也是可以的。
对了,在修改配置文件之前一定要记得先备份文件,修改以后要重启服务。