和CPU类似,GPU是有各种不同的memory spaces,每种memory都有各自的特性,使用起来速度也不同,并且应用的范围也不同。这些memory按照等级会分成各种chunks,相信用过深度学习的小伙伴对chunks这个应该不陌生吧,如果网络结构比较大,batchsize设置也很大,超过了GPU的memory,经常汇报关于chunks的错误,最后加上out of memory的报错。
GPU的memory主要有一下几种,global memory,shared memory, local memory,constant memory和texture memory。

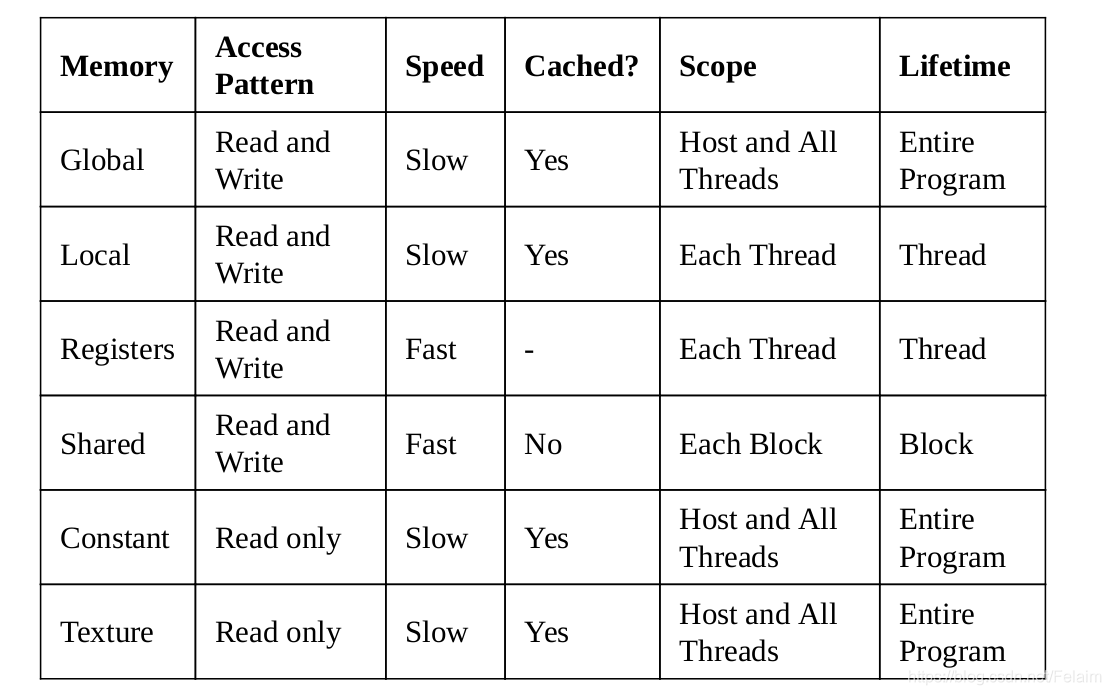
从上述图中,可以看到每隔thread有local memory和一个register file。与处理器不同的是,GPU内核有许多寄存器来存储本地数据。当线程的数据不适合寄存器文件时,将使用本地内存。 它们对于每个线程都是唯一的,需要了解一点的是register访问是最快的。
在图中也可以看到在同一个block中的thread有共同的shared memory,这个可以看成是所有thread都可以访问的memory,所以Shared memory是用来thread之间的数据通信的。
Global memory,顾名思义,就是所有的block和thread都可以访问的memory,global memory是存在较大的内存访问延迟,所以速度相对是比较慢的,所以为了加速,有添加了L1缓存和L2缓存,L2缓存是各个block和thread共有的,L1缓存是在每个block中都有的,在相同block中的thread共享同一个L1
最后,还有一个只读的constant memory用来存储常量和内核参数。 有一个texture memory,利用不同的二维或三维访问模式。原来GPU都是应用在游戏中,所以原始的texture memory的占比很高,后来用于GPGPU的发展,texture memory相对之前的占比有所下降。
所有的memory特性总结如下表所示:
 下面是使用shared memory的一个测试代码:
下面是使用shared memory的一个测试代码:
#include <cuda_runtime_api.h>
#include <iostream>
#include <stdio.h>
__global__ void gpu_shared_memory(float * d_a){
int index = threadIdx.x;
float average, sum = 0.0f;
// define shared memory
__shared__ float sh_arr[10];
sh_arr[index] = d_a[index];
// This directive ensure all the writes to shared memory have completed
__syncthreads();
for (int i = 0; i<=index; ++i){
sum += sh_arr[i];
}
average = sum/(index+1.0f);
d_a[index]= average;
// this statement is redundant and will have no effect on overall code execution
sh_arr[index] = average;
}
int main(){
float h_a[10];
float *e_a;
// initialize host array
for(int i = 0; i<10; ++i){
h_a[i] = i;
printf(" h_a[%d]: %f \n", i, h_a[i]);
}
// allocate global memory on the device
cudaMalloc((void **)&e_a,sizeof(float)*10);
// copy data from host memory to device memory
cudaError_t cudaStatus;
cudaStatus = cudaMemcpy((void *)e_a, (void *)h_a, sizeof(float)*10, cudaMemcpyHostToDevice);
if(cudaStatus != cudaSuccess){
std::cout <<"Cuda memory copy failed! " << std::endl;
}
gpu_shared_memory <<<1, 10 >>>(e_a);
// copy the modified array back to the host
cudaStatus = cudaMemcpy((void *)h_a, (void *)e_a, sizeof(float)*10, cudaMemcpyDeviceToHost);
if(cudaStatus != cudaSuccess){
std::cout <<"Cuda memory copy failed! " << std::endl;
}
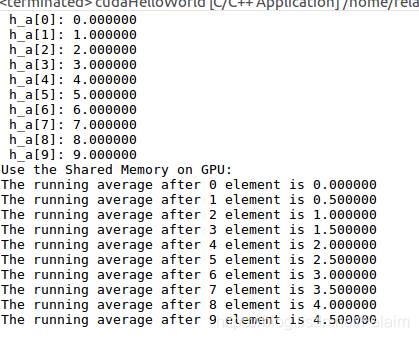
printf("Use the Shared Memory on GPU: \n");
for(int i = 0; i<10; i++){
printf("The running average after %d element is %f \n", i, h_a[i]);
}
return 0;
}
输出结果为:
参考书籍:
1.Hands-On GPU-Accelerated Computer Vision with OpenCV and CUDA
PS:
今日疫情:
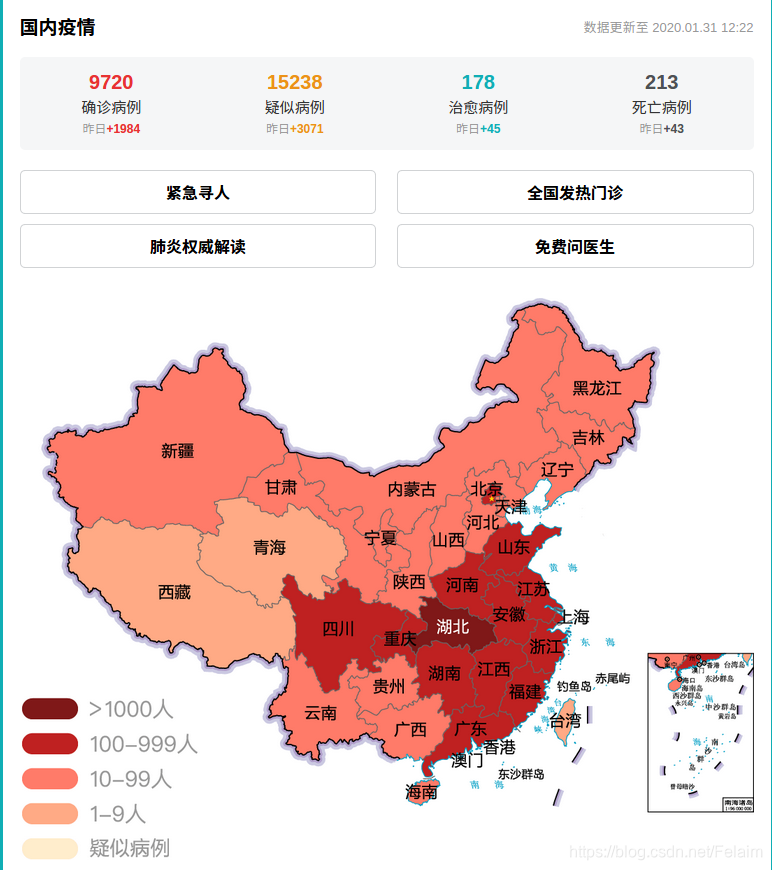

明天公布的确诊病例估计要破万了,爱国要理智,写公众号要对人民负责,在这个节骨眼上煽动人民的情绪是不是有点过了,作为一个公民,要有起码的辨别是非的能力,而不是被人一带节奏就跑偏了。
遇事冷静一下,要不自己核实下再喷呗。。。
