1.什么是letterbox?
款屏幕的视频,被显示出来,保持比例不变,上下需要填充黑色,每个黑色填充部分,称为letterbox, https://en.wikipedia.org/wiki/Letterboxing_(filming)
2. mediapipe,检测手掌,都包括什么信息,即检测到了什么?
包括手掌的图片中的rect box, 用x,y,w,h描述,和7个关键点,不是21个关键点,7个关键点,是手的最外围6个关键点,加中指第一关节关键点。后面利用腕关节和中指第一关节,成90度,来转正手掌。

https://github.com/google/mediapipe/blob/master/mediapipe/docs/hand_tracking_mobile_gpu.md
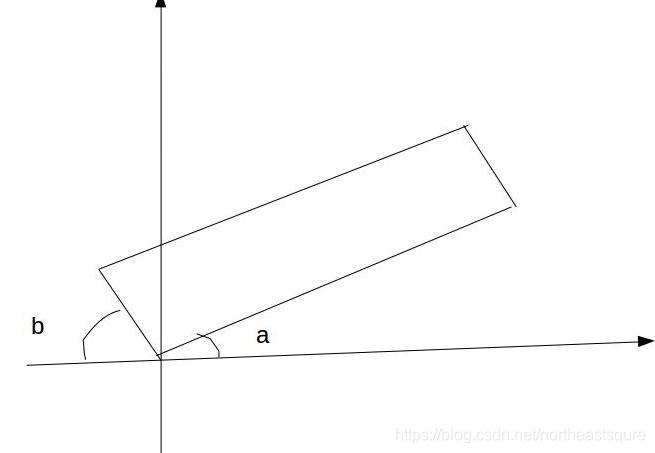
3.对比blazepalm的转正方式,在text detection任务中,east, https://github.com/argman/EAST, 中,angle是怎么产生的?
在east中,文本角度是直接预测的,范围是[-45, 45], 即(softmax-0.5)*PI/2, 那么这个角度是什么意思呢,没有大于45度的情况吗?
如果大于45度,就取取左边的角度。如下图,一般预测角度a, 如果a>45, 那么预测b, https://github.com/argman/EAST/blob/master/icdar.py#L371
4. mediapipe hand tracking 有很多误检,请估计原因,以及解决办法。
mediapipe 手势跟踪测试
我测试时候,mediapipe,经常把远处的脸检测成了手,造成误检,估计原因,是其训练集里面,没有加入不含手的图片,解决办法是,重新训练,增加不含手,但是有很多类似手的图片
5.mediapipe,里面有误检时候,没有把landmark画出来,为什么?似乎画出了手掌轮廓,还有绿色小矩形里面有绿色小圆圈,是怎么画出来的,是什么?
小矩形是手掌部分,不含手指,见上面图。
6. handtracking 里面每个关键点对应的关节名称是什么,怎么排列的?

7.mediapipe hand tracking, 使用了多少数据集训练?其中z坐标是什么?
3w张图片 ,z是hand landmark到镜头的距离
https://ai.googleblog.com/2019/08/on-device-real-time-hand-tracking-with.html (To obtain ground truth data, we have manually annotated ~30K real-world images with 21 3D coordinates, as shown below (we take Z-value from image depth map, if it exists per corresponding coordinate).)
8.预测的21 landmark是否有 score?
有score, 阈值用来判断,判断下一帧是否继续检测手
9. 对于landmark 的深度信息,在普通单目摄像机上,准确率如何?
非常不准,手放在一米的镜头前只要手背隆起:
I1228 15:18:42.683882 20126 landmarks_to_render_data_calculator.cc:222] z:14.1406
I1228 15:18:42.683890 20126 landmarks_to_render_data_calculator.cc:69] z_min:0.00139046 z_max:29.7969
I1228 15:18:42.683907 20126 landmarks_to_render_data_calculator.cc:328] thickness:4
I1228 15:18:42.683914 20126 landmarks_to_render_data_calculator.cc:222] z:19.2656
I1228 15:18:42.683923 20126 landmarks_to_render_data_calculator.cc:69] z_min:0.00139046 z_max:29.7969
I1228 15:18:42.683931 20126 landmarks_to_render_data_calculator.cc:328] thickness:4
I1228 15:18:42.683939 20126 landmarks_to_render_data_calculator.cc:222] z:23.5312
I1228 15:18:42.683948 20126 landmarks_to_render_data_calculator.cc:69] z_min:0.00139046 z_max:29.7969
I1228 15:18:42.683956 20126 landmarks_to_render_data_calculator.cc:328] thickness:4
I1228 15:18:42.683964 20126 landmarks_to_render_data_calculator.cc:222] z:27.0469
I1228 15:18:42.683972 20126 landmarks_to_render_data_calculator.cc:69] z_min:0.00139046 z_max:29.7969
I1228 15:18:42.683981 20126 landmarks_to_render_data_calculator.cc:328] thickness:4
I1228 15:18:42.683990 20126 landmarks_to_render_data_calculator.cc:222] z:14.4922
I1228 15:18:42.683997 20126 landmarks_to_render_data_calculator.cc:69] z_min:0.00139046 z_max:29.7969
I1228 15:18:42.684006 20126 landmarks_to_render_data_calculator.cc:328] thickness:4
I1228 15:18:42.684013 20126 landmarks_to_render_data_calculator.cc:222] z:19.1875
I1228 15:18:42.684028 20126 landmarks_to_render_data_calculator.cc:69] z_min:0.00139046 z_max:29.7969
I1228 15:18:42.684037 20126 landmarks_to_render_data_calculator.cc:328] thickness:4
I1228 15:18:42.684046 20126 landmarks_to_render_data_calculator.cc:222] z:21.4062
I1228 15:18:42.684053 20126 landmarks_to_render_data_calculator.cc:69] z_min:0.00139046 z_max:29.7969
I1228 15:18:42.684062 20126 landmarks_to_render_data_calculator.cc:328] thickness:4
I1228 15:18:42.684070 20126 landmarks_to_render_data_calculator.cc:222] z:23.0156
I1228 15:18:42.684077 20126 landmarks_to_render_data_calculator.cc:69] z_min:0.00139046 z_max:29.796911 背景复杂的话,mediapipe handtrack检测效果如何?
有很多误检
12 检测步骤,只检测手掌,不检测手指,为什么?
a) 因为手掌是刚性的,比起有关节的手指,用深度学习来检测要容易得多;b)手掌是小物体,所以使用nms是可以的,同时对于握手这种,也可以很好的检测到两个手;c)手掌可以认为是方形的anchor, 从而不需要考虑多种比例,这样极大地减少了anchor数量 1/3-1/5; d)使用了encoder-decoder的方式, 可以很好的利用周围信息,对于检测小目标很有用;d)我们优化focal loss, 这样,虽然有很多尺度的方框,也能很好的处理。
13 mediapipe hand detection, 使用focal loss + 解码器结构, 准确率是多少?而不用解码器,用普通方框最小均方误差,mse, 准确率是多少?
分别是:95.7%, 86.22%
14 什么是focalloss?
普通交叉熵损失如下,目标值为1, 如果预测趋近于1,那么误差很小,如果预测趋近于0,那么误差非常大;如果目标值为0,那么1-y=1, 1-p趋近于0,误差很小,如果p趋近于1,
如下两个式子,后面部分不管,只看前面,y=1,预测接近于1,那么是简单样本,降低损失,而对于难得样本,比如p=0.1, 那么(1-p)就提高了难样本的损失;同理对于y=0的样本,如果p接近0,那么是很简单的样本,乘以p降低损失,即简单的负样本,误差很小;如果p接近于1,那么是难得负样本,要加大它的权重,乘以p就加大了。
r=2,会更加大这种趋势
