(查阅网上相关资料的总结笔记)
前端学习建议
1. 夯实基础
基础一定要掌握牢固,基础知识一问三不知,就是贻笑大方。css,js基础知识一定要掌握得很熟练。
到什么程度可以称为熟练?你能使用css实现斑马条纹背景,毛玻璃效果吗?能给图片实现滤镜效果,能实现所有自适应布局效果吗?原型,原型链,闭包是实现设计模式的必备知识,你真的弄懂了吗?闭包导致内存泄漏的原因是什么,你弄明白了吗?ajax跨域的解决方案你可以说几种?http协议有了解过吗?
掌握好这些老掉牙的基础,就是很重要。上层的技术可以变更的很快,基础变动很慢,投入时间学好基础,性价比很高。
2. 深究原理
Angular,React,Vue框架和脚手架的普及,越来越多的前端工程师浮于表面,调用框架的API完成任务就完事。要成为一名优秀的前端,绝不能成为单纯的”API调用工程师”,一定要掌握框架背后的原理性知识。
Virtual DOM diff算法,双向绑定原理等等框架背后的机制都值得我们去学习。框架API可以更新很快,而他们背后的原理都是相似的,学好原理既可以让我们对框架底层了解更深入,又可以使我们迅速掌握不断更新的框架表层。只会用框架永远也成不了大神。
3. 注意细节
“代码能用就行”的认识往往是初级程序员的通病。作为有在技术道路上有理想的工程师,一定要对自己的代码严格要求,精益求精。
比如HTML一定要注意语义化以方便SEO优化,该用<section>,<head>,<foot>的地方不能一股脑儿用<div>完事;css中编写样式时不能页面上样式是有了,类名和属性排序写得一塌糊涂,建议大家按照BEM规范编写风格良好的代码;js中变量命名随意是很常见的不规范行为,一个不直观的变量名往往使同事看了脑袋大。
“代码千万行,注释第一行。命名不规范,同事两行泪。“一首流行诗,饱含了多少程序员的血与泪。
4. 登高见远
前端经历了这么多年的飞速发展,早已成为浩瀚的大海。如果闷着头独自钻研苦学,那无疑是很慢的。
技能图谱
如果我们直接去跟随大神学习,那将会使我们快速成长。github上有很多优秀的前端项目,仔细研读这些项目的代码,在commit记录中查看编程思想和逻辑的进化过程,就是一场与大神直接的面对面交流,是一场绝妙的学习之旅。

<一>Web发展史
互联网就是指通过TCP/IP协议族互相连接在一起的计算机网络。
Web是World Wide Web的简称,中文译为万维网。是运行在互联网上的一个超大规模的分布式系统。
Web设计初衷是一个静态信息资源发布媒介,通过超文本标记语言(HTML)描述信息资源,通过统一资源标识符(URI)定位信息资源,通过超文本转移协议(HTTP)请求信息资源。HTML、URL和HTTP三个规范构成了Web的核心体系结构,是支撑着Web运行的基石。用通俗的一点的话来说,客户端(一般为浏览器)通过URL找到网站(如www.google.com),发出HTTP请求,服务器收到请求后返回HTML页面。可见,Web是基于TCP/IP协议的,TCP/IP协议把计算机连接在一起,而Web在这个协议族之上,进一步将计算机的信息资源连接在一起,形成我们说的万维网。
参考链接:link
<二>前端开发中的MVC/MVP/MVVM
MVC,MVP和MVVM都是常见的软件架构设计模式(Architectural Pattern),它通过分离关注点来改进代码的组织方式。不同于设计模式(Design Pattern),只是为了解决一类问题而总结出的抽象方法,一种架构模式往往使用了多种设计模式。
MV*的目的是把应用程序的数据、业务逻辑和界面这三块解耦,分离关注点,不仅利于团队协作和测试,更有利于甩锅维护和管理。业务逻辑不再关心底层数据的读写,而这些数据又以对象的形式呈现给业务逻辑层。
从 MVC --> MVP --> MVVM,就像一个打怪升级的过程,它们都是在MVC的基础上随着时代和应用环境的发展衍变而来的。
参考链接:
link
link
link
<三>Vue
Vue就是基于MVVM模式实现的一套框架,在vue中:Model:指的是js中的数据,如对象,数组等等。View:指的是页面视图viewModel:指的是vue实例化对象
1.为什么说Vue是渐进式的框架?
- 如果你已经有一个现成的服务端应用,你可以将vue 作为该应用的一部分嵌入其中,带来更加丰富的交互体验;
- 如果你希望将更多业务逻辑放到前端来实现,那么VUE的核心库及其生态系统也可以满足你的各式需求(core+vuex+vue-route)。和其它前端框架一样,VUE允许你将一个网页分割成可复用的组件,每个组件都包含属于自己的HTML、CSS、JAVASCRIPT以用来渲染网页中相应的地方。
- 如果我们构建一个大型的应用,在这一点上,我们可能需要将东西分割成为各自的组件和文件,vue有一个命令行工具,使快速初始化一个真实的工程变得非常简单(vue init webpack my-project)。我们可以使用VUE的单文件组件,它包含了各自的HTML、JAVASCRIPT以及带作用域的CSS或SCSS。以上这三个例子,是一步步递进的,也就是说对VUE的使用可大可小,它都会有相应的方式来整合到你的项目中。所以说它是一个渐进式的框架。
2.Vue最独特的特点?
VUE最独特的特性:响应式系统VUE是响应式的(reactive),也就是说当我们的数据变更时,VUE会帮你更新所有网页中用到它的地方。关于这个响应式原理,官方已经讲得很清楚,可以参考link
3.主流框架实现双向绑定(响应式)的做法:
- 脏值检查:angular.js 是通过脏值检测的方式比对数据是否有变更,来决定是否更新视图,最简单的方式就是通过 setInterval() 定时轮询检测数据变动,当然Google不会这么low,angular只有在指定的事件触发时进入脏值检测,大致如下: DOM事件,譬如用户输入文本,点击按钮等。( ng-click ) XHR响应事件 ( $http ) 浏览器Location变更事件 ( $location ) Timer事件( $timeout , $interval ) 执行 $digest() 或 $apply()在 Angular 中组件是以树的形式组织起来的,相应地,检测器也是一棵树的形状。当一个异步事件发生时,脏检查会从根组件开始,自上而下对树上的所有子组件进行检查,这种检查方式的性能存在很大问题。
- 观察者-订阅者(数据劫持):vueObserver 数据监听器,把一个普通的 JavaScript 对象传给 Vue 实例的 data 选项,Vue 将遍历此对象所有的属性,并使用Object.defineProperty()方法把这些属性全部转成setter、getter方法。当data中的某个属性被访问时,则会调用getter方法,当data中的属性被改变时,则会调用setter方法。Compile指令解析器,它的作用对每个元素节点的指令进行解析,替换模板数据,并绑定对应的更新函数,初始化相应的订阅。Watcher 订阅者,作为连接 Observer 和 Compile 的桥梁,能够订阅并收到每个属性变动的通知,执行指令绑定的相应回调函数。Dep 消息订阅器,内部维护了一个数组,用来收集订阅者(Watcher),数据变动触发notify 函数,再调用订阅者的 update 方法。执行流程如下:
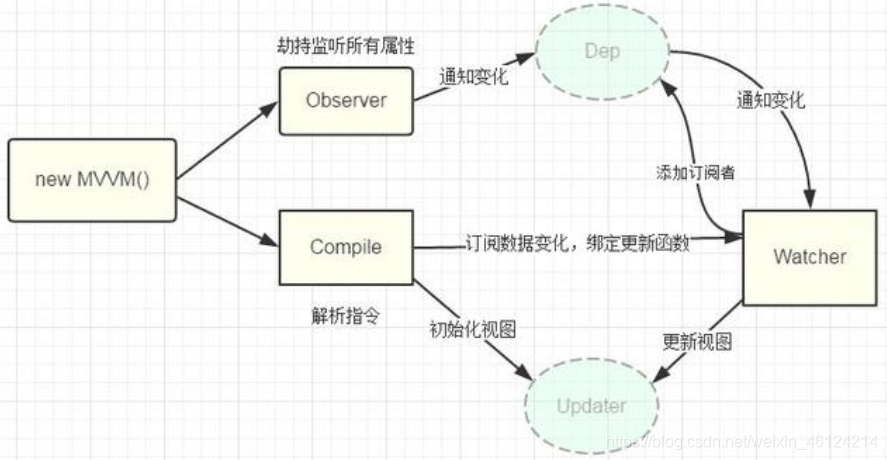
从图中可以看出,当执行 new Vue() 时,Vue 就进入了初始化阶段,一方面Vue 会遍历 data 选项中的属性,并用 Object.defineProperty 将它们转为 getter/setter,实现数据变化监听功能;另一方面,Vue 的指令编译器Compile 对元素节点的指令进行解析,初始化视图,并订阅Watcher 来更新视图, 此时Wather 会将自己添加到消息订阅器中(Dep),初始化完毕。当数据发生变化时,Observer 中的 setter 方法被触发,setter 会立即调用Dep.notify(),Dep 开始遍历所有的订阅者,并调用订阅者的 update 方法,订阅者收到通知后对视图进行相应的更新。因为VUE使用Object.defineProperty方法来做数据绑定,而这个方法又无法通过兼容性处理,所以Vue 不支持 IE8 以及更低版本浏览器。另外,查看vue原代码,发现在vue初始化实例时, 有一个proxy代理方法,它的作用就是遍历data中的属性,把它代理到vm的实例上,这也就是我们可以这样调用属性:vm.aaa等于vm.data.aaa。
<四>SPA
1.什么是单页面应用程序(SPA)
- SPA是一种Web开发方法,整个应用功能都存在于单个页面中。
- 在SPA应用中,应用加载之后就不会再有整页刷新。相反,展示逻辑预先加载,并有赖于内容Region(区域)中的视图切换来展示内容。
- SPA客户端与服务器端实行异步通信。常用的数据通信格式为JSON文本格式。
- MV*框架提供机制,让SPA应用绑定服务器端请求数据与视图(用户所见并与之交互)。
- 与依赖全局变量和函数不同的是,SPA中的JavaScript代码通过模块来组织。模块提供了状态和/或数据封装。模块还有助于代码解耦及维护。
- SPA的优势还包括类桌面应用的呈现效果、解耦的表现层、更快速轻量的符合、更少的用户等待时间以及更好的代码维护性等。
2.SPA与传统Web应用的区别
SPA:无需刷新浏览器,将需要操作的DOM的变化放在浏览器中,如果页面需要变化的时候,由操作这些变化的JavaScript(已经加载于浏览器中的)来实现操作。
SPA实现的视图的刷新,是局部子容器(Region)的变化,而不是页面的重新加载,无重载页面是单页面应用程序的关键
- 无需刷新浏览器
- 表现逻辑位于客户端
- 服务器端事务处理
3.关于SPA的使用
- 使用模块模式
利用模块模式限制变量和函数作用域为模块自身。避开全局作用域相关的各种陷阱。
模块模式结合其他相关技术管理模块以及其依赖的可行方式,使得程序员能够借助页面构架方法来设计大型、健壮的Web应用程序。 - 为了让用户掌握其导航位置,单页面应用程序通常会在设计中融入路由选择(Routing)的设计思路:接触MV*框架或第三方库的代码实现,将URL风格的路径与功能关联起来。路径通常看起来像相对URL,其充当用户导航时到达特定视图的触发因素。路由器可以动态更新浏览器URL,并允许用户使用前进和后退按钮。这就进一步强化了当屏幕某部分变化时会到达新位置的设计理念。
- SPA创建视图组成与布局
在单页面应用程序中,UI由视图而非新页面构成。内容Region的创建以及视图在这些Region中的位置,决定了应用程序的布局。客户端路由由于连接这些点。所有的这些要素有机结合起来就影响了应用程序的可用性和美感。 - 利用MV*框架实现SPA架构
- 一种架构。传统式的Web架构是前端交互,通过请求服务器获取处理好的新的HTML文件从而进行页面的重载刷新,而SPA式的Web架构设计是用户体验倾向于原生软件开发式的,是让用户决定我们用的就是一个原生开发式的程序应用,但是这个程序应用又不像软件一样需要下载,需要不断的更新,他就只是一个页面,通过路由器、AJAX等技术实现这样的用户体验的架构设计。
- SPA只是一种架构理念,是想要达到的某种Web应用的体验。最终实现这样的程序应用需要用到的技术有很多,诸如路由器、AJAX、客户端自动化等等的技术。
- MV框架就是集成了各种可以实现SPA架构理念的技术的程序集合,这些集合又体现了传统的MVC、MVP、MVVM等设计模式,但是又不局限于某种设计模式,是多种设计模式的集合体,因此我们称之为MV框架。
参考:link
<五>关注点分离
好的架构设计必须把变化点错落有致地封装到软件系统的不同部分。要做到这一点,必须进行关注点分离。Iuar Jacobson在《AOSD中文版》中写道:
“好的架构必须使每个关注点相互分离,也就是说系统中的一个部分发生了变化,不会影响其他部分。即使需要改变,也能够清晰地识别出那些部分需要改变。如果需要扩展架构,影响将会最小化,已经可以工作的每个部分都将继续工作。”
上述论述中的三句话:
“系统中的一个部分发生了变化,不会影响其他部分。”
“即使需要改变,也能够清晰地识别出那些部分需要改变。”
“如果需要扩展架构,将影响最小化,已经可以工作的每个部分都将继续工作。”
可以说是对软件开发者的奋斗目标的最精辟的论述。也是软件设计要达到的最高目标。
关注点分离是实现上述目标的基本方法。
关注点分离的基本方法有:
- 按职责分离关注点
将一个功能的实现分成展现层、业务层和数据层就是典型的按职责进行关注点分离的例子。 - 按通用性分离关注点
不同的通用程度意味着变化的可能性不同。可以将组成系统的元素分成技术通用部分、领域通用部分和特定应用部分。技术通用部分具有广泛的通用性,领域通用部分在对应领域具有普遍通用性。特定应用部分一般没有通用性。 - 按粒度级别分离关注点
在软件架构设计中,可以优先考虑大粒度的子系统和在集成系统中的互操作,忽略子系统的进一步分离。
参考:link
<六>前后端分离
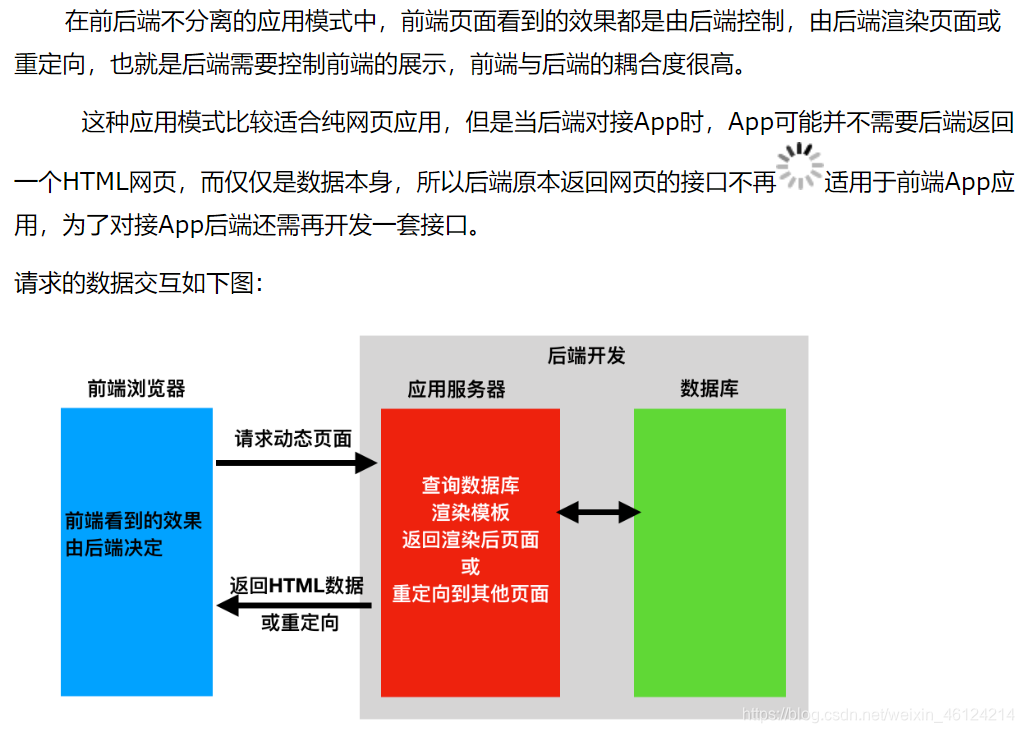
1.前后端不分离:
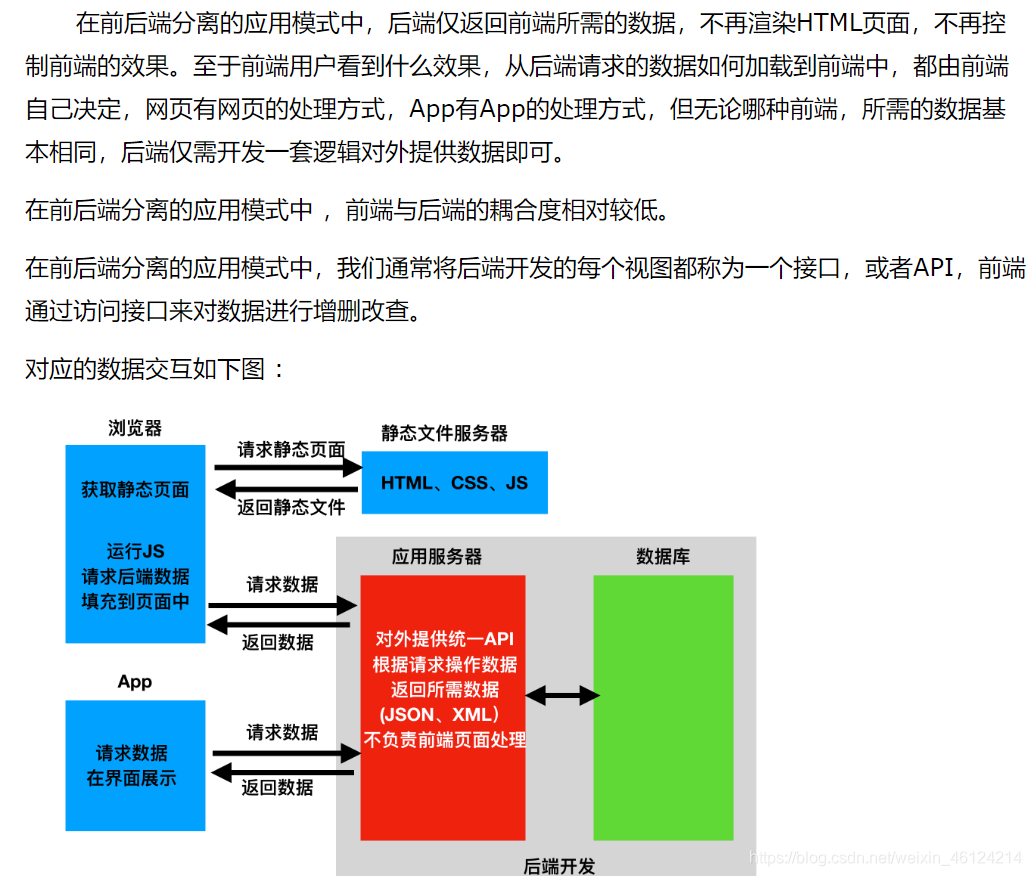
2.前后端分离:
<七>前端架构的工程化、模块化、组件化、规范化
一个项目组成分为 前端,服务端。传统的前端项目用三剑客 javascript html css 就传统的项目结构已经不能满足日益壮大的大型应用的需求了。现在前端的生态圈很繁荣,各种框架,组件的出现。让前端发展迅速,快速开发已经成为了前端的一个标准。如果你想构建一个易维护,代码简洁,性能优化程度高的项目就离不开前端的架构。这也就解疑了架构是不是必须的?
架构的目的是什么?答案是提升质量和效率。
那应该怎么进行架构呢?架构的目的是制定标准,提升质量和效率。
- 架构是一个抽象的过程,它是架构师根据自己的经验对大量具体的业务项目进行分析,发现其中的规律,抽象出具体的规范,最终又应用于具体的业务项目中去。比如常说的MVVM就是一种规范。
- 要把跟业务无关的问题都在架构层面处理掉。比如代码压缩,打包这种工程化的问题都要在架构层面统一解决的。要做到业务的归业务,架构的归架构。
- 架构要考虑到可以方便团队成员提供和使用通用技术解决方案。比如分页组件这种。
- 架构设计的时候要综合考虑当前的主流技术跟自己业务系统的实际情况。因为前端正处在高速发展,各种新技术,工具,插件,框架层出不穷,要结合项目实际情况运用已经成熟的技术,避免跳坑。。
合理的架构应该是怎么样的?
概括几点就是:模块化,组件化,工程化,规范化。
1. 浅谈工程化
将前端项目当成一项系统工程进行分析、组织和构建从而达到项目结构清晰、分工明确、团队配合默契、开发效率提高的目的.
工程化是一种思想而不是某种技术 (当然为了实现工程化我们会用一些技术)
前端工程化就是用做工程的思维看待和开发自己的项目,而不再是直接撸起袖子一个页面一个页面开写
工程化就像是百叶箱一样,减少人的操作,把工作所需要的工具做到的标准化,工作的流程做到的标准化。同时把很多重复的工作交给了代码来做,保证高质,标准统一。
先从工具入手,工程化包括哪些方面:
- 模块化与组件化: npm, es6,seajs, react/angularjs/Vue
- 代码版本管理: git
- 代码风格管理: jscs, editorconfig
- 代码编译: babel, less,sass,scss, imgmin, csssprit, inline-svg
- 代码质量管理 (QA): eslint, mocha
- 代码构建: webpack
- 项目脚手架: yeoman
- 持续集成/持续交付/持续部署: jenkins
- 本地化与国际化
进行工程化: - 在配置初始项目文件结构和基本文件依靠命令行(工具)自动生成。
- 确定代码规范,缩进,换行,以及各种预编译工具less,coffee,保证输出代码的标准一致
- 对JS文件是否规范化,进行单元测试,不用手动复制到jshint上去检测,现在配置grunt监听文件变动自动检验显示检验结果还可以通过配置构建工具自动刷新浏览器实现文件实时变动监听。
- 以前压缩合并文件用手工复制到压缩工具然后复制到一个文件里面,现在配置一下 grunt,gulp可以做自动任务,实时编译,并且监测文件改变而做出响应。
- 以前发布到服务器上,要手动使用 FTP 软件上传,现在也可以用工具自动打包上传。
2.浅谈模块化
前端工程化是一个高层次的思想,而模块化和组件化是为工程化思想下相对较具体的开发方式,因此可以简单的认为模块化和组件化是工程化的表现形式。
模块化开发,一个模块就是一个实现特定功能的文件,有了模块我们就可以更方便的使用别人的代码,要用什么功能就加载什么模块。
模块化方案需解决什么问题?
模块化要实现两个东西:模块加载与模块封装。
面临的具体问题包括:
- 如何定义模块以确保模块的作用域独立,避免命名冲突?
- 如何管理模块间的依赖关系,避免重复加载与循环引用?
- 模块化的代码如何部署,以降低HTTP请求数?
- 如何实现按需加载?
- 如何在解决上述问题之后,保证性能且不影响debug?
模块化开发的4点好处:
- 避免变量污染,命名冲突
- 提高代码复用率
- 提高维护性
- 依赖关系的管理
通行的JavaScript模块规范主要有两种:CommonJS和AMD
CommonJS
我们先从CommonJS谈起,因为在网页端没有模块化编程只是页面JavaScript逻辑复杂,但也可以工作下去,在服务器端却一定要有模块,所以虽然JavaScript在web端发展这么多年,第一个流行的模块化规范却由服务器端的JavaScript应用带来,CommonJS规范是由NodeJS发扬光大,这标志着JavaScript模块化编程正式登上舞台。
- 定义模块
根据CommonJS规范,一个单独的文件就是一个模块。每一个模块都是一个单独的作用域,也就是说,在该模块内部定义的变量,无法被其他模块读取,除非定义为global对象的属性。 - 模块输出
模块只有一个出口,module.exports对象,我们需要把模块希望输出的内容放入该对象。 - 加载模块使用require方法,该方法读取一个文件并执行,返回文件内部的module.exports对象。
不同的实现对require时的路径有不同要求,一般情况可以省略js拓展名,可以使用相对路径,也可以使用绝对路径,甚至可以省略路径直接使用模块名(前提是该模块是系统内置模块)
AMD
AMD 即Asynchronous Module Definition,中文名是异步模块定义的意思
requireJS主要解决两个问题
- 多个js文件可能有依赖关系,被依赖的文件需要早于依赖它的文件加载到浏览器
- js加载的时候浏览器会停止页面渲染,加载文件越多,页面失去响应时间越长
CMD
CMD 即Common Module Definition通用模块定义,CMD规范是国内发展出来的,就像AMD有个requireJS,CMD有个浏览器的实现SeaJS,SeaJS要解决的问题和requireJS一样,只不过在模块定义方式和模块加载(可以说运行、解析)时机上有所不同
AMD与CMD区别
最明显的区别就是在模块定义时对依赖的处理不同
- AMD推崇依赖前置,在定义模块的时候就要声明其依赖的模块
- CMD推崇异步依赖加载的,只有在用到某个模块的时候再去require
AMD和CMD最大的区别是对依赖模块的执行时机处理不同,注意不是加载的时机或者方式不同。很多人说requireJS是异步加载模块,SeaJS是同步加载模块,这么理解实际上是不准确的,其实加载模块都是异步的,只不过AMD依赖前置,js可以方便知道依赖模块是谁,立即加载,而CMD就近依赖,需要使用把模块变为字符串解析一遍才知道依赖了那些模块,这也是很多人诟病CMD的一点,牺牲性能来带来开发的便利性,实际上解析模块用的时间短到可以忽略。
具体模块化比较可以查看:
link
link
webpack时代
webpack的优点:
- 1require.js的所有功能它都有
- 编绎过程更快,因为require.js会去处理不需要的文件
- 还有一个额外的好处就是你不需要再做一个封装的函数,require.js中你得这样
define([‘jquery’], function(jquery){}) - 现在你需要一个很大的封装去定义每个模块,然后你需要在在require.js的配制文件中将每个模块的路径都配出来,用过requirejs都会遇到的好繁琐
对比requirejs seajs webpack特有的属性:
- 对 CommonJS 、 AMD 、ES6的语法做了兼容
- 对js、css、图片等资源文件都支持打包(css都可以合成多个css文件包,sass和less虽然也是模块化的加载合并,可是css和js分离的关联不大,这里的css可以和js有更大的关联,更细致区分加载的js)
- 串联式模块加载器以及插件机制,让其具有更好的灵活性和扩展性,例如提供对CoffeeScript、ES6的支持
- 有独立的配置文件webpack.config.js
- 可以将代码切割成不同的chunk,实现按需加载,降低了初始化时间
- 支持 SourceUrls 和 SourceMaps,易于调试
- 具有强大的Plugin接口,大多是内部插件,使用起来比较灵活
- webpack 使用异步 IO 并具有多级缓存。这使得 webpack 很快且在增量编译上更加快
- 双服务器模式
3.浅谈组件化
组件化也是工程化的表现形式。
- 页面上的每个独立的、可视/可交互区域视为一个组件;
- 每个组件对应一个工程目录,组件所需的各种资源都在这个目录下就近维护;
- 由于组件具有独立性,因此组件与组件之间可以 自由组合;
- 页面只不过是组件的容器,负责组合组件形成功能完整的界面;
- 当不需要某个组件,或者想要替换组件时,可以整个目录删除/替换。
组件化将页面视为一个容器,页面上各个独立部分例如:头部、导航、焦点图、侧边栏、底部等视为独立组件,不同的页面根据内容的需要,去盛放相关组件即可组成完整的页面。
PS:模块化和组件化一个最直接的好处就是复用,同时我们也应该有一个理念,模块化和组件化除了复用之外还有就是分治,我们能够在不影响其他代码的情况下按需修改某一独立的模块或是组件,因此很多地方我们及时没有很强烈的复用需要也可以根据分治需求进行模块化或组件化开发。
组件化设计就是为了增加复用性,灵活性,提高系统设计,从而提高开发效率。
保证组件的封闭性。因为JS方面是模块化的。组件的功能界限问题。也就是什么是应该在组件内部实现,什么是应该由组件的调用者来实现的。对组件功能界限的定义是只负责UI相关的功能,所有的业务逻辑都是从调用者传递过的。也即是写在param.js。所以param.js文件是非常重要的一个文件,里面基本包涵了这个页面所有业务处理逻辑。很显然,随着页面业务逻辑变的复杂,js文件将会变得越来越大。没关系,把不同的组件参数分拆到不同的js文件里面去实现,然后建个专门的文件夹把它们组织起来。
4.前端组件化与模块化之间的区别
组件化
- 就是"基础库"或者“基础组件",意思是把代码重复的部分提炼出一个个组件供给功能使用。
- 使用:Dialog,各种自定义的UI控件、能在项目或者不同项目重复应用的代码等等。
- 目的:复用,解耦。
- 依赖:组件之间低依赖,比较独立。
- 架构定位:纵向分层(位于架构底层,被其他层所依赖)。
模块化
- 就是"业务框架"或者“业务模块",也可以理解为“框架”,意思是把功能进行划分,将同一类型的代码整合在一起,所以模块的功能 相对复杂,但都同属于一个业务。
- 使用:按照项目功能需求划分成不同类型的业务框架(例如:注册、登录、外卖、直播…)
- 目的:隔离/封装 (高内聚)。
- 依赖:模块之间有依赖的关系,可通过路由器进行模块之间的耦合问题。
- 架构定位:横向分块(位于架构业务框架层)。
总结
- 其实组件相当于库,把一些能在项目里或者不同类型项目中可复用的代码进行工具性的封装。组件化更关注的是 UI 部分:弹出框、头部,内容区、按钮等,都可以编写成组件,然后在适用的地方进行引用。,组件化主要解决代码复用的问题。
- 而模块相应于业务逻辑模块,把同一类型项目里的功能逻辑进行进行需求性的封装。而模块化更侧重于功能或者数据的封装,比如全局的 JSON 配置文件,比如通用的验证方法,比如规范时间戳等。模块化能将复杂系统解耦。
5.浅谈规范化
项目目录结构非常清晰。当进行开发的时候,哪些代码应该放到哪里都进行了明确的规定,并且每个文件的功能都尽量清晰并且单一。
架构是个不断完善的过程,而把架构尤其是跟规范相关的部分落实到具体业务系统里面更是个团队不断磨合的过程。它最终考验的,同时也是最终磨合出来的是团队的成熟度。
