前面的几篇文写得有点快了,有些地方囫囵吞枣的划过去。等停下来一段时间,我会慢慢去修改和补充。
现在放慢脚步来一点点的写。
XSS(Cross Site Scripting),又称跨站脚本攻击。看英文,缩写应该是CSS,但是为了区别前端的CSS(Cascading Style Sheets)层叠样式表,改名为XSS。这也算是“晚辈”对“长辈”的尊敬吧,何况你还属于“暗”,人家在“明”,总不能抢名字抢的明目张胆。
XSS漏洞的存在的原因,和sql注入在本质上是相同的,都是因为没有对用户的输入进行检验和过滤,而产生攻击者可能嵌入恶意脚本(主要是JavaScript)的隐患。
XSS从攻击代码的工作方式上可以分为三类:1.反射型XSS(又称非持久型);2.存储型XSS(又称持久型);3.DOM型XSS(Document object model)。
我们会一一提到。
首先说反射型。我的五毛钱特效解释图:
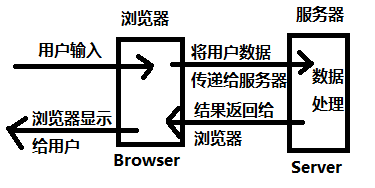
用户在浏览器的输入数据会提交给服务器,服务器对数据进行处理,返回在页面上。如果服务器处理不当,就会出现问题。
理论归理论,还是直接把DVWA调出来。![]()

这个界面里有一个输入框,还有一个提交按钮。右键查看下源码(Ctrl + u),使用我教你的英语阅读法,迅速定位主要内容(要学会用搜索Ctrl + f)。

<h1>Vulnerability: Reflected Cross Site Scripting (XSS)</h1>
<div class="vulnerable_code_area">
<form name="XSS" action="#" method="GET">
<p>
What's your name?
<input type="text" name="name">
<input type="submit" value="Submit">
</p>
</form>
</div>
这时我们在输入框中随便输入点什么,点击提交。
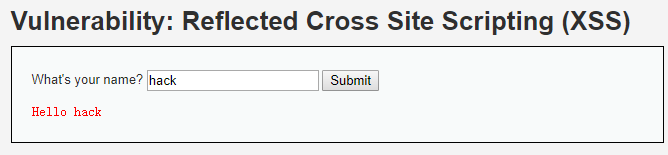
页面显示出Hello XX,XX就是你的输入内容。这里的显示,就是讲解图中的最后一步。
打开源码:

<h1>Vulnerability: Reflected Cross Site Scripting (XSS)</h1>
<div class="vulnerable_code_area">
<form name="XSS" action="#" method="GET">
<p>
What's your name?
<input type="text" name="name">
<input type="submit" value="Submit">
</p>
</form>
<pre>Hello hack</pre>
</div>
我们看到hack被嵌入到了界面中。
这时我们就可以猜想,服务器做的处理是什么呢?甚至不用想,就是把输入内容嵌入到网页上。
view source下:
<?php
header ("X-XSS-Protection: 0");
// Is there any input?
if( array_key_exists( "name", $_GET ) && $_GET[ 'name' ] != NULL ) {
// Feedback for end user
echo '<pre>Hello ' . $_GET[ 'name' ] . '</pre>';
}
?> 果不其然,if条件从参数中拿出name的值,直接echo出来。
头部的header函数,它是向用户发送最原始请求头的。不是本文的重要内容,我举个简单的例子,感兴趣的要学会去查(包括什么是请求头,请求头的作用是什么,header具体怎么使用等等)。
例如用户浏览器的默认设置,在加载数据的时候会进行缓存。如果服务器并不希望给你提供完服务后,还让你保存着它的数据,它的后台处理代码中就可能有这么一句:
header("Cache-Control: no-cache");
header("Pragma: no-cache");如此就会强制浏览器不进行缓存。
而此例中的 X-XSS-Protection: 0 的功能是不启用XSS保护,如果值为1的话,即为启用XSS保护,这时XSS注入就没用了。
我们还没学怎么用XSS,就不能用了,太扯了。所以这里设了个零。(听不懂也没关系,它对本文的理解没什么影响,出来刷波存在感。)
我们通过输入猜到了服务器的处理功能,并且通过查看代码,也证实了我们的猜想。可以看到,后台没有对我们的输入进行任何过滤,就直接echo了出来。
这,就是XSS需要的。
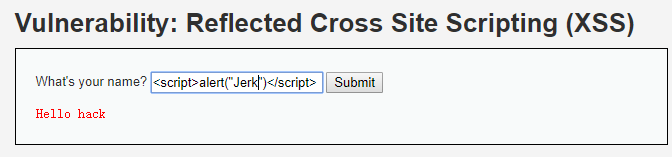
试想,我们输入<script>alert("jerk")</script>,会发生什么结果?(默认你有html和js基础,不对标签基础功能进行讲解。)

Ohhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh,怎么会这样。
查看网页源码:

服务器没对我们的输入进行过滤,直接将内容传给了浏览器,浏览器将<script></script>解析成脚本标签,alert当成js脚本代码执行了。
XSS原理就是这么简单,仅此而已。
太无聊了,我们将安全等级提高。不再LOW了:
同样的XSS脚本:
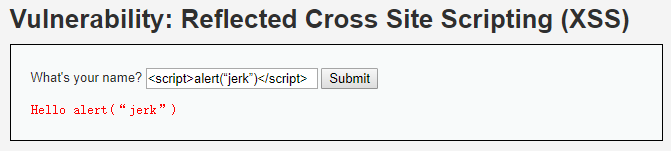
咦,脚本没有执行,还把内容显示了出来,虽然并没有标签。猜猜看后台干了什么?
对的,过滤"<script>":
<?php
header ("X-XSS-Protection: 0");
// Is there any input?
if( array_key_exists( "name", $_GET ) && $_GET[ 'name' ] != NULL ) {
// Get input
$name = str_replace( '<script>', '', $_GET[ 'name' ] );
// Feedback for end user
echo "<pre>Hello ${name}</pre>";
}
?> 我们可以瞅见,多了一句str_replace。它将内容中的“<script>”去掉了(替换为空),我们的输入从<script>alert</script>变成了alert()</script>。
那为什么</script>没有显示出来呢?因为他会被浏览器当成标签,而不是显示内容。又因为浏览器没有找到</script>的前端<script>,标签没有闭合,所以<script>标签并没有起作用。alert被当做文本显示了出来。
查看网页源码:

后半个的确还在,前半个没了。
那,怎么搞定他呢?其实方法有很多,你会接触到很多很多的绕过姿势,这里说两个最简单的。
1.调整大小写,后台中过滤的是“<script>”,字符串是不可变的,亲!你换成<SCRIPT>不就完了?
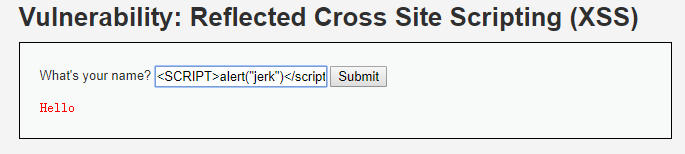
提交:

完美。
调整大小写的方式很多,如somethingwithouttitle:
1.标题式调整:SomethingWithoutTitle
2.完全式调整:SOMETHINGWITHOUTTITLE
3.神经式调整:sOmeTHinGWithOutTiTle(随机调整)。
(上面这三个是我胡扯的,小声BB)
2.复写。这个方法在sql注入中有提到,例如你过滤script,我就在script中间任意位置再插入一个script。

将script过滤后,我前后的内容仍旧是一个script。
构造XSS:<scr<script>ipt>alert("jerk")</script>

提交:

没问题。
唉,这个也没意思。再提高个难度:换成high。

这时你去尝试之前的所有方法,全部废掉。为什么呢?来看看后台怎么处理的:
<?php
header ("X-XSS-Protection: 0");
// Is there any input?
if( array_key_exists( "name", $_GET ) && $_GET[ 'name' ] != NULL ) {
// Get input
$name = preg_replace( '/<(.*)s(.*)c(.*)r(.*)i(.*)p(.*)t/i', '', $_GET[ 'name' ] );
// Feedback for end user
echo "<pre>Hello ${name}</pre>";
}
?>str_replace换成了preg_replace。正则匹配,看正则表达式:/<(.*)s(.*)c(.*)r(.*)i(.*)p(.*)t/i
()内部为一个整体, 其中的.* 点代表任意字符,星表示将前一单位重复0或多次。最后的/i表示不区分大小写。
这属于正则内容,想深入了解的就需要你去STW和RTM了。
简单说,它过滤掉了所有包含<script的数据,无论你怎样复写,而且还不区分大小写。
跪了,没办法了,high就是high,玩不了。
其实不然,还是那句话,你的姿势不对。
<script>标签被过滤了,你就换个标签嘛。用<img>标签,在它的src中写脚本。
哈?img的src不是图片路径吗,还能写脚本?
这个可能不常见,我们常见的是在<a>标签的href写脚本的,比如:
<a href="javascript:void(0);" ></a>
<a href="javascript:;" ></a>
<a href="#" ></a>这些可能大家常见,但是不晓得什么意思。其实他要达到的功能就是,当你点击这个超链接时,不做任何功能性处理,仅此而已。最后的那种href="#"的超链接,功能是“回到顶部”。
换句话说我们可以这样写:<a href="javascript:alert('jerk');"></a>,然后点击页面上的超链接来达到目的。img的src中也可以这样写。
那为什么要讲img呢,因为script被过滤了呀。href="javascript:alert('jerk');"里面的存在script会被过滤掉。
也就是说,我们的方法里不应该和script字符串有关系。
img标签里有个onerror函数,在src给的路径错误,图片显示不出来时,界面就会显示:
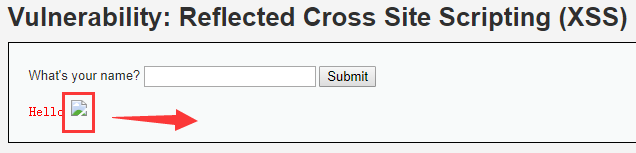
太丑了,为了处理这种情况,img有了onerror函数,当src有误时,执行处理函数,即onerror指定的函数。
这个功能太棒了,我们构造的XSS就故意给个无效的src,然后将脚本交给onerror。
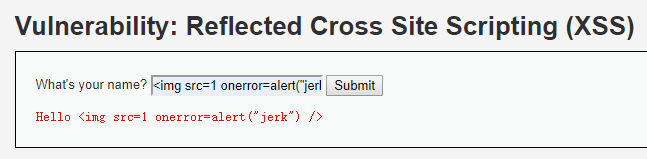
构造:<img src=1 οnerrοr=alert("jerk") />
显然,src=1是个锤子语法,妥妥的有问题,嗳,巧了,要的就是有问题。
提交!!!

秀~
还有其他方法吗?有!
利用body标签的onload函数。此函数在页面加载完成后立即执行指定的函数功能。
构造:<body οnlοad=alert("jerk")>,提交:

结果没啥问题。
我倒是有个理解上的问题,本来页面的结构是:
<html>
<head></head>
<body></body>
</html>
现在结构是:
<html>
<head></head>
<body><body></body>
</html><body>中间有<body>,这个在浏览器解析的时候是怎么处理的?为何不会错误?我查了些资料,没找到原理性的解释,这个问题先留在这里吧,后面再补回来。如果有了解的小伙伴,欢迎评论指出,我会将您的评论贴进来。
全部说完,最后看看impossible安全级别的:
![]()
无论你怎样XSS,都不会有问题:
输入内容原封不动的给你输出了。怎么做到的呢?
view source:
<?php
// Is there any input?
if( array_key_exists( "name", $_GET ) && $_GET[ 'name' ] != NULL ) {
// Check Anti-CSRF token
checkToken( $_REQUEST[ 'user_token' ], $_SESSION[ 'session_token' ], 'index.php' );
// Get input
$name = htmlspecialchars( $_GET[ 'name' ] );
// Feedback for end user
echo "<pre>Hello ${name}</pre>";
}
// Generate Anti-CSRF token
generateSessionToken();
?>能迅速找到核心语句吗?
没错,就是:$name = htmlspecialchars( $_GET[ 'name' ] )
htmlspecialchars函数什么作用?我们从另一个角度出发。
在C语言中,输出是要进行格式化的,比如输出整数一,printf( "%d", 1)。输出换行,printf("\n")。
我们知道%和\在输出格式化中是有特殊用处的,那如果我想让它输出“%”和“\n”这个字符串怎么办呢?printf("%%"),printf("\\n")。即对转移字符本身进行处理。
类比,在html中<>不是会被解释成标签吗?那如果我想在网页上显示<>呢?这些有特殊作用的符号,我们叫做预留字符(像C中的百分号和转义符)。如果想要输出预留字符,必须使用字符实体,而这个过程,又叫“实体化”。
比如如果网页上显示<>,你的html中的实体字符为:<>
代码中&标记的,就是实体化字符。(你现在就可以查看源码,看看这里的<>,是什么东西。)
而htmlspecialchars这个函数,就是做实体化用的,它会将你输入的数据中预留字符全部转换,从而可以直接显示到界面上。不过仅此而已,但你的渗透也到此而已了,因为你所有的输入都没有被执行的机会了。
反射型,说完了。还剩下存储型和DOM型,我们下篇谈。XSS构造原理都是一样的,剩下的两个我们会很快的理解并解决掉它们。
后记:文章遗留问题测试。
<html>
<head></head>
<body onload=alert("first")>
<body onload=alert("second")></body>
</body>
</htlml>外层body加载函数输出first,内层body加载函数输出second。

点击确定后,second并没有输出,也就是说,onload只执行一次。如果把外层去掉:
<html>
<head></head>
<body>
<body onload=alert("second")></body>
</body>
</htlml>就输出了second。
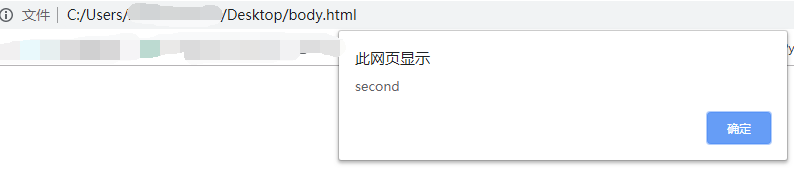
如果内层body标签没闭合:
<html>
<head></head>
<body>
<body onload=alert("second")>
</body>
</htlml>依旧可以输出:
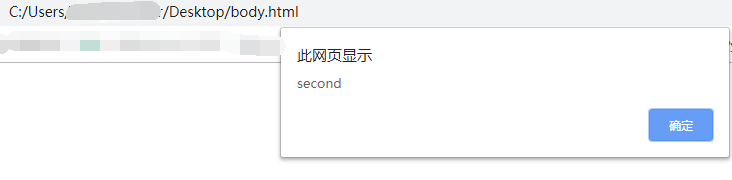
一个标签,如果只有前标签(如<body>),大部分浏览器解析时会给你补充完整,它会认为你忘记了闭合。如果只有后标签(如</body>),浏览器没找到你的前标签,就认为你写错了,标签就会作废。这是浏览器的容错性,记住这个特性,在渗透中,也是可以被利用的点。
下一个问题,一个html文本中,有多个body是怎么回事?其实html规范是head和body是只允许有一个的,但是html的解析归浏览器管,也就是说,有没问题,浏览器说的算(测试的例子使用的浏览器是chrome)。
而大部分浏览器对多个body的处理是进行拼接,即将两个body的内容合并成一个显示。例:
<html>
<head></head>
<body>
This is first body
<body>Another</body>
</body>
</htlml>内外层body写上不同的内容:
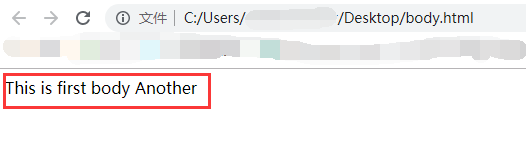
网页的显示丝毫不受影响。
