环境如下:
Hadoop 2.6.0以上
java JDK 1.7以上
Spark 3.0.0-preview2
一、Scala独立应用编程
1、安装sbt
sbt是一款Spark用来对scala编写程序进行打包的工具,这里简单介绍sbt的安装过程,感兴趣的读者可以参考官网资料了解更多关于sbt的内容。
Spark 中没有自带 sbt,这里直接给出sbt-launch.jar的下载地址,直接点击下载即可。
我们选择安装在 /usr/local/sbt 中:

sudo mkdir /usr/local/sbt

sudo chown -R hadoop /usr/local/sbt # 此处的 hadoop 为你的用户名

cd /usr/local/sbt
下载后,执行如下命令拷贝至 /usr/local/sbt 中(本人没有使用本步操作 因为本人不是在虚拟机中下载的sbt-launch.jar包,所以在Windows机中下载好后直接拖拽到了Linux机中的 /usr/local/sbt 文件夹中):

cp ~/下载/sbt-launch.jar .
接着在 /usr/local/sbt 中创建 sbt 脚本(vim ./sbt),添加如下内容(进入vim后输入 “ i ”进入编辑插入模式 ):

#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
保存后(复制本内容(Ctrl+V)粘贴到虚拟机中(Ctrl+Shift+V),退出编辑模式(Esc),保存并退出(:wq 注意:w前的冒号也要输入)),为 ./sbt 脚本增加可执行权限:

chmod u+x ./sbt
最后运行如下命令,检验 sbt 是否可用(请确保电脑处于联网状态(网速会十分影响下载速度),首次运行会处于 “Getting org.scala-sbt sbt 0.13.11 …” 的下载状态,请耐心等待。笔者等待了5分钟才出现第一条下载提示,全部下载下来笔者大约用了4-5个小时(受网速影响)):

./sbt sbt-version
只要能得到如下图的版本信息就没问题:

2、Scala应用程序代码
在终端中执行如下命令创建一个文件夹 sparkapp 作为应用程序根目录:
cd ~ # 进入用户主文件夹

mkdir ./sparkapp # 创建应用程序根目录

mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构
在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件(vim ./sparkapp/src/main/scala/SimpleApp.scala),添加代码如下:

/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
该程序计算 /usr/local/spark/README 文件中包含 “a” 的行数 和包含 “b” 的行数。代码第8行的 /usr/local/spark 为 Spark 的安装目录,如果不是该目录请自行修改。不同于 Spark shell,独立应用程序需要通过 val sc = new SparkContext(conf) 初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息。
该程序依赖 Spark API,因此我们需要通过 sbt 进行编译打包。 ./sparkapp 中新建文件 simple.sbt(vim ./sparkapp/simple.sbt),添加内容如下,声明该独立应用程序的信息以及与 Spark 的依赖关系:

name := "Simple Project"
version := "1.0"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.0.0-preview2"
文件 simple.sbt 需要指明 Spark 和 Scala 的版本。在上面的配置信息中,scalaVersion用来指定scala的版本,sparkcore用来指定spark的版本,这两个版本信息都可以在之前的启动 Spark shell 的过程中,从屏幕的显示信息中找到(如果忘记了可以重新启动一下spark :
 (进入spark的安装目录)
(进入spark的安装目录)
 (启动spark)
(启动spark)
再回看一下,(退出spark输入 “ :quit ”,注意q前面的冒号要一同输入))。下面就是笔者在启动过程当中,看到的相关版本信息。
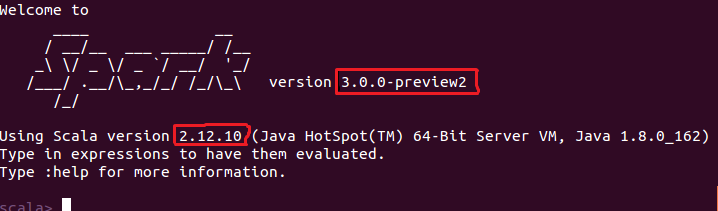
3.使用 sbt 打包 Scala 程序
为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构:

cd ~/sparkapp
find .
文件结构应如下图所示:

接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 ,笔者用了大约2-3个小时(由下载依赖包时的网速决定)):

/usr/local/sbt/sbt package
打包成功的话,会输出如下图内容:

生成的 jar 包的位置为 ~/sparkapp/target/scala-2.12/simple-project_2.12-1.0.jar。(其中两个版本可能有所不同,读者只需要到对应的文件夹下对应查找即可)(~为主文件夹:点击虚拟机的![]() 进入就是主文件夹)
进入就是主文件夹)
4、通过 spark-submit 运行程序
最后,我们就可以将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下:(红线部分就是上边说的生成的jar包的位置)

/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.12/simple-project_2.12-1.0.jar(笔者未使用此命令,不建议使用)
# 上面命令执行后会输出太多信息,可以不使用上面命令,而使用下面命令查看想要的结果
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.12/simple-project_2.12-1.0.jar 2>&1 | grep "Lines with a:"(此命令为笔者所使用的命令,方便查看,推荐使用)
最终得到的结果如下:

自此,你就完成了你的第一个 Spark 应用程序了。
本博客参考了林子雨的大数据原理与应用 第十六章 Spark 学习指南 http://dblab.xmu.edu.cn/blog/804-2/