原文链接UFLDL Tutorial PCA
PCA主成分分析(Principal Components Analysis)是重要的降低维度的方法,可以大大提高算法运行的速度。PCA更是应用白化(whiten)的基础,而whiten是许多算法中重要的预处理步骤。
当你在对图片进行算法训练时,图片的像素一般都有许多冗余,因为相邻像素的关联度很高,比如你训练的图片是16 x 16大小,那么你的数据维度就达到16x16 = 256维,而PCA能将你的数据降维,而且几乎不会带来多少误差。
实例
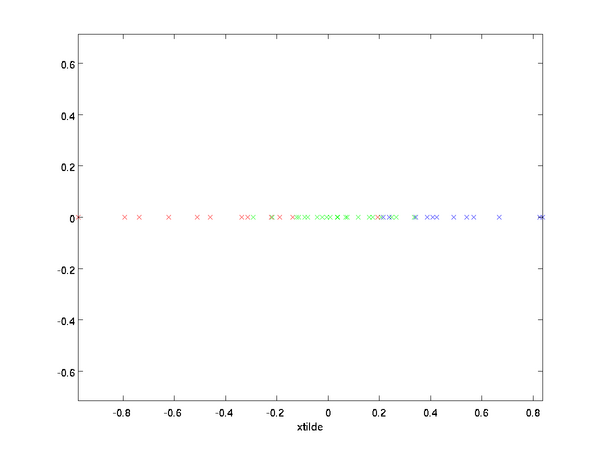
我们这里的例子用的数据集是两维的,我们将利用PCA将数据从2维降到1维(实际中是一般为256维降到50维..为了可视化方便我们采用2维数据),如下图所示
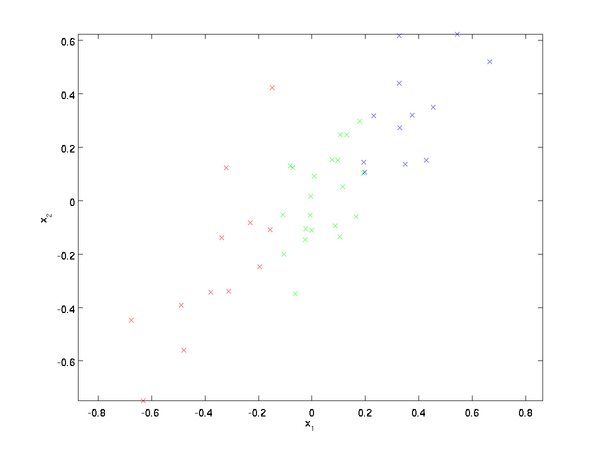
这里用的数据x1 和 x2都经过预处理,使其有相同的均值(0)和方差.为了描述方便,我们也人工地将数据进行了分类(不是采用机器学习分类方法)
,PCA算法将我们的数据投影到一个低维子空间中,从可视化的角度看,下图中u1代表数据变量的主方向,u2代表次方向。
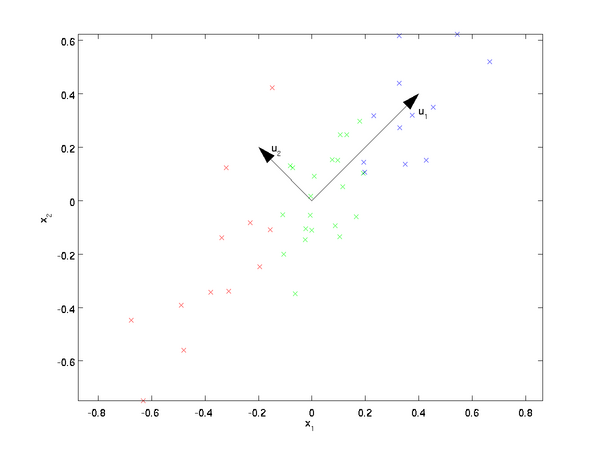
也就是说,变量主要在u1和u2方向变化。为了更加正式地表达如何计算u1和u2,我们首先计算矩阵
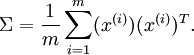
如果x的均值为0,那么
u1和u2分别是协方差矩阵的第一和第二特征向量。
可以用一些做线性代数运算的软件求协方差矩阵的特征向量。具体来说,我们可以利用计算得到的特征向量形成特征向量矩阵:
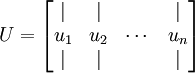
式中,u1、u2…un 都是矩阵的特征向量,其中u1是第一特征向量。令
在我们这个二维数据的例子中,可以重新以u1、u2作为基准坐标系来表示数据。
旋转数据
因此,我们可以将
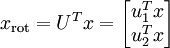
我们对每个训练数据都进行旋转变换,可以得到如下图所示数据:
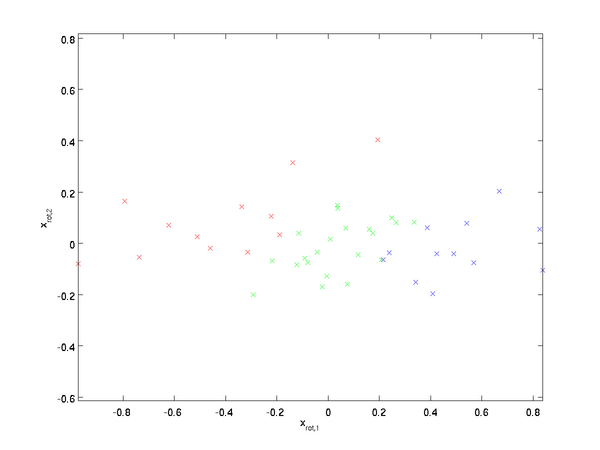
这是训练集在旋转到
数据的降维
我们可以看到变量的主方向是
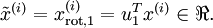
更一般的来说,如果数据
另一种对PCA的解释是,
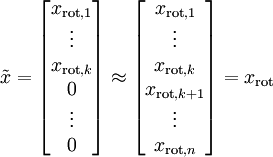
我们这个例子中,可以绘出
然而,因为最后n-k 维总是0,所以也没必要保留这些数据,我们就令
* 恢复数据的近似值*
现在,我们将
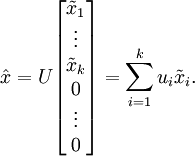
实际应用中,我们不会真的用0扩展剩余的n-k维,而是直接将
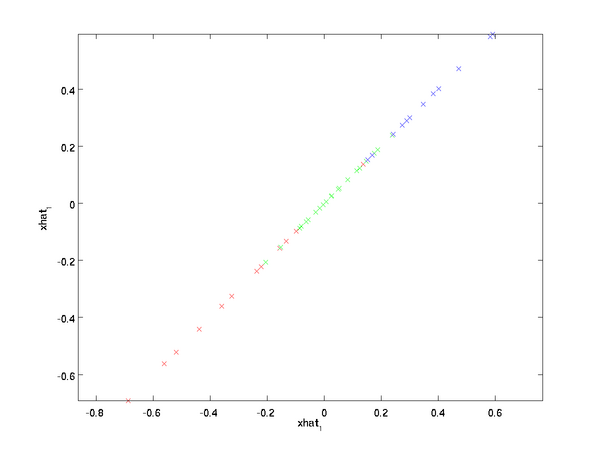
我们利用1维数据近似表示了原始的2维数据。
如果你在训练一个自编码器或者其他的非监督特征学习算法,你的算法运行 时间会依赖于你的输入维度大小。如果把数据从n降维到k,你的算法运行速度会有很大的提高。对于许多数据集来说,
应该剩下多少成分?
我们如何选择k的值呢,需要留下多少成分呢? 本例的二维数据似乎显然是选择k=1,但是这不具有一般性,无法推广到多维数据。如果k太大,我们压缩不了多少数据, 极限状态下,若k = n则我们就没有对数据进行压缩;如果k太小,我们就不能对原始数据有个很好的近似。
为了确定k的值,我们一般看不同k情况下的变量留存百分比(percentage of variance retained )。对于k = n,则我们对 原始数据有100%的近似,数据的变化都留存下来了。相反如果k=0,则我们近似数据都是0,因此0%的变化留存下来了。
更一般有,令
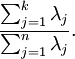
在我们这个2D的例子中,
变量留存百分比更正式的定义超出了本教程的内容。但是式子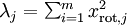 可以解释一些内容,如果
可以解释一些内容,如果
对于图像的处理,一种通常的启发式做法是选择k保留99%的变化。也就是说,我们选择最小的k,满足:
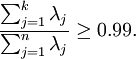
根据不同的应用,如果对图片精度要求不高的话,也能取90~98%。当你向他人描述PCA的应用时说选择k值保留95%的变化要比说保留120(无论是多少个)个成分要清楚明了得多。
PCA 在图像中的应用
为了让PCA有效,我们一般希望每个特征有相似的取值范围(且均值接近于0)。如果你使用PCA在其他应用中,通过归一化可以将每个特征的均值为0 方差为1。但是对于绝大多种类的图片来说,不进行这样的预处理。特别地,假设我们在训练我们的算法应用于自然图片,
注意:通常我们用的图片都是户外的,有草地、树木等,然后从图片中随机的裁剪小尺寸(比如16 X 16 )的图片进行训练。但是实际中 大多数特征学习算法对于训练的特定种类图片有足够的鲁棒性,只要图片不是太模糊,或者有什么奇怪的人造物,算法都能工作。
训练自然图片时,对于每一个像素分别计算平均值和方差意义不大,因为统计上来说,图片的一部分应该(理论上)和其他任何一部分一样。这种图片的属性称为平稳性(stationarity)。
细节上来说,为了让PCA工作有效,我们要求两点:
1. 特征均值近似为0;
2. 不同特征方差近似;
对于一般的自然图片,无需方差正规化,要求2自然满足。(如果你在训练音频,或者是光谱图,或者一些文本,我们一般也不会进行方差正规化。)。事实上,PCA与数据的缩放无关,它会返回相同的特征向量。
所以我们不会进行方差正规化,我们唯一需要正规化的是均值,来确保特征的均值大约为0。对于大部分应用来说我们不关心图片整体是否明亮,比如说对于物体类别识别任务,图片整体的明亮与否不会影响物品的种类。更正式的说法是,我们不关心一个图片的平均亮度。因此我们可以直接 减去这个值,这也就是均值正规化的方法。具体的,如果
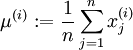
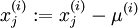
注意:这两步是对每一个图片
如果你不是训练自然图片,而是训练手写数字之类的图片。可以考虑一些其他的正规化方法,根据不同应用要选择不同的方法。但是当你训练自然图片时,上述方法是最常用的合理方法。