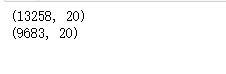import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
import seaborn as sns
import warnings
warnings. filterwarnings( "ignore" )
pd. options. display. max_columns = None
pd. set_option( 'display.float_format' , lambda x: '%.2f' % x)
train_data = pd. read_csv( 'training30.csv' )
test_data = pd. read_csv( 'test30.csv' )
total_data = pd. concat( [ train_data, test_data] , axis= 0 )
total_data. info( )
cdma = pd. read_csv( 'cdma.xls' , encoding= 'gbk' , sep= '\t' )
print ( cdma. shape)
cdma = cdma[ ( cdma[ '销售区局' ] == '浦东电信局' ) & ( cdma[ '渠道管理细分' ] . isin( [ '专营渠道' , '中小渠道' , '开放渠道' ] ) ) ]
print ( cdma. shape)
match_table = pd. read_excel( '数据说明与匹配公式.xlsx' , sheet_name= '部门匹配表' )
new_cdma = cdma. merge( match_table, how= 'left' , on= [ '发展部门名称' , '渠道管理细分' ] )
new_cdma = new_cdma[ new_cdma[ '渠道管理细分' ] == '专营渠道' ]
new_cdma[ [ '统计日期' , '订单号' , '所属部门' , '所属代理商' , '所属分局' , '渠道经理' ] ] . head( )
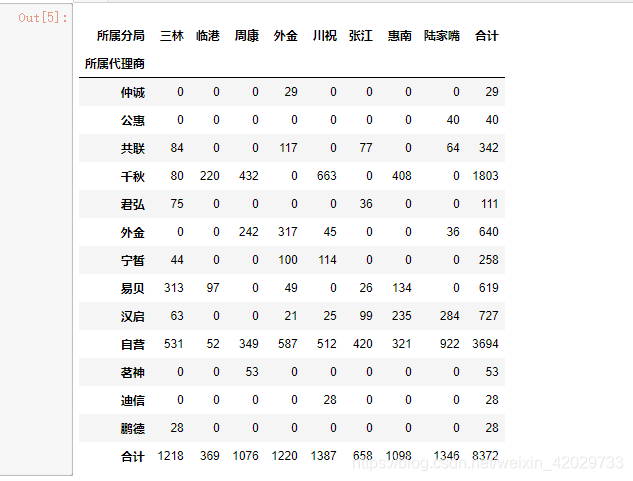
cdma_pivot = new_cdma. pivot_table( index= '所属代理商' , values= '订单号' , columns= '所属分局' , aggfunc= 'count' , fill_value= 0 , margins= True , margins_name= '合计' )
cdma_pivot
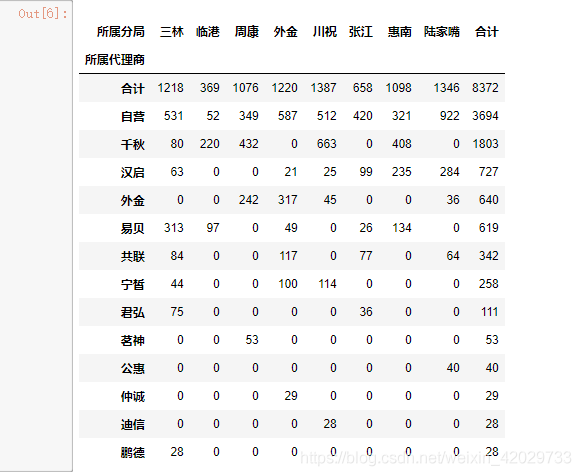
cdma_pivot. sort_values( by= '合计' , inplace= True , ascending= False )
cdma_pivot
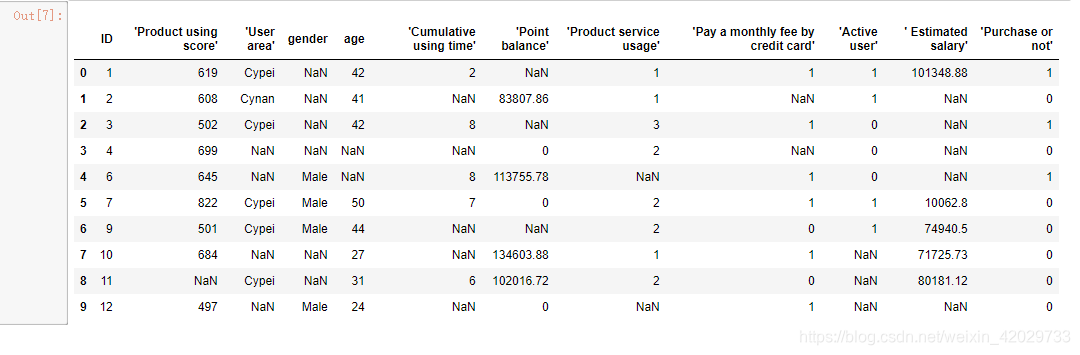
train_data = train_data. replace( '?' , np. nan)
train_data. head( 10 )
train_data2 = train_data. replace( 'Tai' , 'Cy' , regex= True )
train_data2. head( 10 )
print ( train_data. shape)
train_data3 = train_data. dropna( subset= [ 'gender' , 'age' ] )
print ( train_data3. shape)
def lower_sample_data ( df, labelname, percent= 1 ) :
'''
percent:多数类别下采样的数量相对于少数类别样本数量的比例
'''
data1 = df[ df[ labelname] == 1 ]
data0 = df[ df[ labelname] == 0 ]
index = np. random. randint(
len ( data0) , size= percent * ( len ( data1) ) )
lower_data0 = data0. iloc[ list ( index) ]
return ( pd. concat( [ lower_data0, data1] ) )
print ( train_data[ "'Purchase or not'" ] . value_counts( ) )
train_data4 = lower_sample_data( train_data, "'Purchase or not'" , percent= 1 )
print ( train_data4[ "'Purchase or not'" ] . value_counts( ) )
train_data5 = pd. read_csv( 'cs-training.csv' )
per_columns = set ( train_data5. columns) - set ( [ 'CustomerID' , 'SeriousDlqin2yrs' ] )
for column in per_columns:
temp_mean = train_data5[ column] . mean( )
train_data5[ column] = train_data5[ column] . fillna( temp_mean)
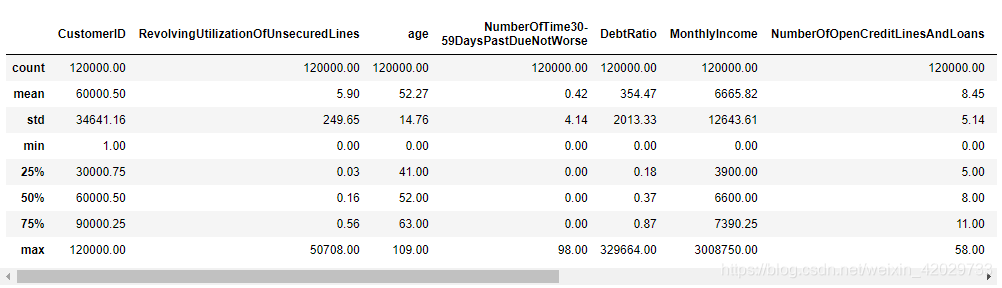
train_data5. describe( )
def cap ( x, quantile= [ 0.05 , 0.95 ] ) :
"""盖帽法处理异常值
Args:
x:pd.Series列,连续变量
quantile:指定盖帽法的上下分位数范围
"""
Q05, Q95= x. quantile( quantile) . values. tolist( )
if Q05 > x. min ( ) :
x = x. copy( )
x. loc[ x< Q05] = Q05
if Q95 < x. max ( ) :
x = x. copy( )
x. loc[ x> Q95] = Q95
return ( x)
train_data6 = train_data5[ per_columns]
train_data6 = train_data6. apply ( cap)
train_data7 = pd. concat( [ train_data5[ [ 'CustomerID' , 'SeriousDlqin2yrs' ] ] , train_data6] , axis= 1 )
train_data7 = train_data7[ train_data5. columns]
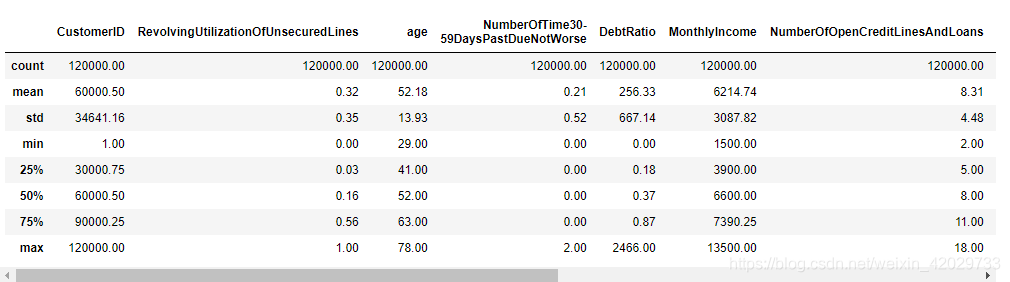
train_data7. describe( )
def cap_mean ( x) :
"""盖帽法处理异常值
Args:
x:pd.Series列,连续变量
"""
x_up = x. mean( ) + 3 * x. std( )
x_down = x. mean( ) - 3 * x. std( )
if x_down > x. min ( ) :
x = x. copy( )
x. loc[ x< x_down] = x_down
if x_up < x. max ( ) :
x = x. copy( )
x. loc[ x> x_up] = x_up
return ( x)
train_data8 = train_data5[ per_columns]
train_data8 = train_data8. apply ( cap_mean)
train_data9 = pd. concat( [ train_data5[ [ 'CustomerID' , 'SeriousDlqin2yrs' ] ] , train_data8] , axis= 1 )
train_data9 = train_data9[ train_data5. columns]
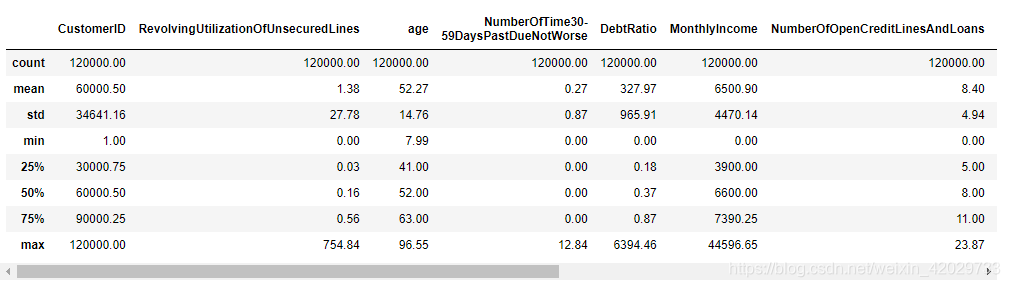
train_data9. describe( )
from sklearn. preprocessing import MinMaxScaler
from sklearn. preprocessing import StandardScaler
mm_scaler = MinMaxScaler( )
ss_scaler = StandardScaler( )
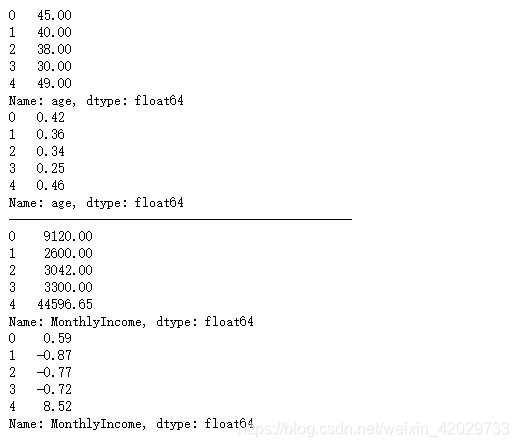
print ( train_data9[ 'age' ] . head( ) )
train_data9[ 'age' ] = mm_scaler. fit_transform( train_data9[ [ 'age' ] ] )
print ( train_data9[ 'age' ] . head( ) )
print ( '-------------------------------------------------' )
print ( train_data9[ 'MonthlyIncome' ] . head( ) )
train_data9[ 'MonthlyIncome' ] = ss_scaler. fit_transform( train_data9[ [ 'MonthlyIncome' ] ] )
print ( train_data9[ 'MonthlyIncome' ] . head( ) )
print ( cdma[ '发展渠道小类' ] . value_counts( ) )
qd_map = { '自营营业厅' : '自营渠道' , '专营店' : '专营渠道' , '合作营业厅' : '专营渠道' , '核心渠道专区专柜' : '专营渠道' , '天翼小店' : '中小渠道' ,
'外包营业厅' : '专营渠道' , '全国连锁卖场' : '开放渠道' , '全网通(专营)' : '专营渠道' , '商圈店' : '专营渠道' , '天翼合作店' : '中小渠道' , '终端零售店(开放)' : '中小渠道' }
cdma_2 = cdma. copy( )
cdma_2[ '渠道统计归类' ] = cdma_2[ '发展渠道小类' ] . map ( qd_map)
print ( cdma_2[ '渠道统计归类' ] . value_counts( ) )
from sklearn. preprocessing import LabelEncoder
le = LabelEncoder( )
cdma_2[ '渠道统计归类' ] = le. fit_transform( cdma_2[ [ '渠道统计归类' ] ] )
cdma_2[ '渠道统计归类' ] . value_counts( )
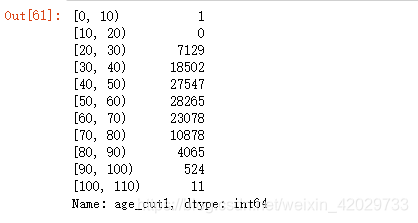
age_range = list ( range ( 0 , 111 , 10 ) )
train_data5[ 'age_cut1' ] = pd. cut( train_data5[ 'age' ] , age_range, include_lowest= True , right= False )
train_data5[ 'age_cut1' ] . value_counts( ) . sort_index( )
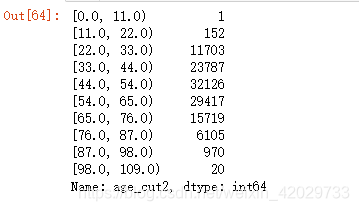
train_data5[ 'age_cut2' ] = pd. cut( train_data5[ 'age' ] , bins= 10 , include_lowest= True , right= False , precision= 0 )
train_data5[ 'age_cut2' ] . value_counts( ) . sort_index( )
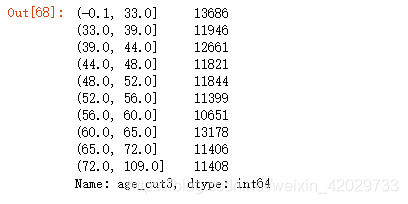
train_data5[ 'age_cut3' ] = pd. qcut( train_data5[ 'age' ] , 10 , precision= 1 )
train_data5[ 'age_cut3' ] . value_counts( ) . sort_index( )