数据挖掘十大经典算法之–ID3
1.算法介绍
ID3是Quinlan提出的一个著名的决策树生成方法。
ID3的基本概念如下:
1.决策树中的每一个非叶子节点对应着一个非类别属性,树枝代表这个属性的值,一个叶子结点代表从树根到叶子结点之间的路径对应的记录所属类别的属性值。
2.每一个非叶子结点都将与属性中具有最大信息量的非类别属性相关联。
3.采用信息增益来选择出能够最好的将样本分类的属性。
2.信息增益
信息增益(Kullback–Leibler divergence)又叫做information divergence,relative entropy 或者KLIC。信息增益基于信息论中熵(Entropy)的概念。熵是对应的属性的不确定性的度量。一个属性的熵越大,它蕴含的不确定信息越大。
在概率论和信息论中,信息增益是非对称的,用以度量两种概率分布P和Q的差异。信息增益描述了当使用Q进行编码时,再使用P进行编码的差异。通常P代表样本或观察值的分布,也有可能是精确计算的理论分布。Q代表一种理论,模型,描述或者对P的近似。
计算公式如下:
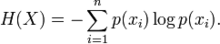
3.具体方法
从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该结点的不同取值建立子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一个决策树
