Evicted pod大量创建问题解决方案
1. 文档目的
集群某一节点磁盘或者内存压力较大时,会出现pod创建失败的情况,该失败pod会被立即驱逐但不会被k8s回收;由于deploy未被删除,k8s会一直处于创建pod,驱逐pod的死循环状态,这会产生大量的未被回收的pod,针对该问题提出解决方案
2. 场景复现
2.1 环境准备
实验集群:master:10.1.11.129 node:10.1.11.130
130节点,磁盘使用到80%以上

创建pod的deploy.yaml内容如下(需要指定nodeName为130):

启动该deploy,观察pod情况如下(随着时间的增长evicted pod会越来越多,理论上最多12500个):

说明:该图指截取了部分pod
3.解决方案
3.1 修改master节点中kube-contoller-manager.yaml配置参数,设置evcited的阀值如下:

说明:该阀值的含义是:节点中可存在状态为evicted的pod的数量,默认是12500,超过该阀值的pod就会被删除,如果该值为0,则代表着不做限制,evicted的pod可以有很多。最小设置为1。
修改完毕执行systemctl daemon -reload && systemctl restart kubelet,再查看pod情况如下:

说明:通过对比上文第三张图,可以看出状态为evicted的pod数量已经很少了,但是我们在kube-controller-manager.yaml中设置的阀值为1,为什么现在不是1个呢?
推测原因是:deploy中指定的replicas为4,pod的创建速度大于删除速度,所以会出现这种问题。
3.2 验证节点恢复正常后pod是否恢复正常:
环境准备:
130节点减小磁盘压力:

在不重启deploy的前提下,持续观察pod状态,经过3次测试,得到结果是:5分钟内,pod状态会恢复正常(前提是deploy指定的实例不是很大) 如图:
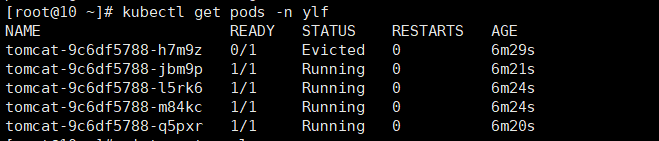
说明:此时节点中仍存在一个evicted状态的pod,手动删除该pod。
