华为2019算法大赛CTR预估数据探索
训练集
这个训练集有159837655个样本,负样本1.5亿,剩下的是正样本;比例约为15:1
时间信息
时间信息有很多杂乱值,主要是2019年三月26到31日的信息,
train['operTime'] = pd.to_datetime(train['operTime'])
conf = (train['operTime'].dt.year==2019)&(train['operTime'].dt.month==3)
train[conf]['operTime'].dt.day.value_counts()
'''
30 28043936
31 28028243
29 27794906
26 25583297
27 25300266
28 24807386
'''
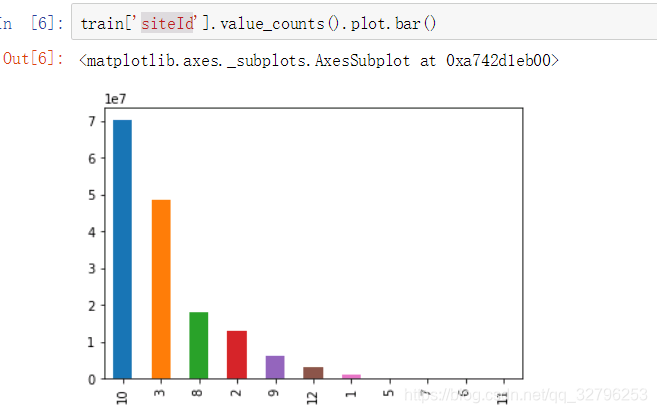
siteId(媒体Id)
媒体Id 的数量分布

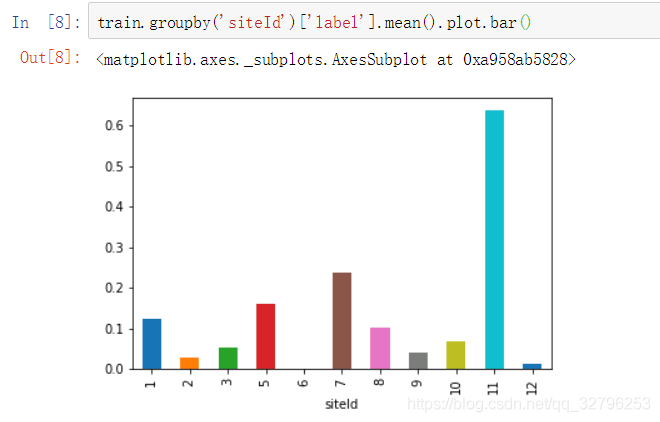
对label的贡献度
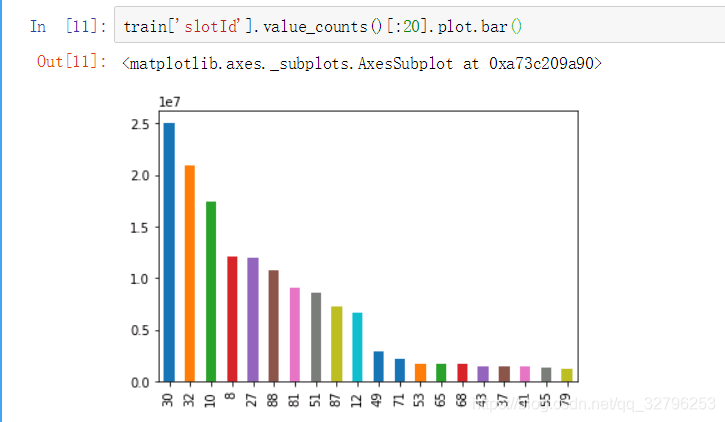
slotId(广告位Id)
前20的个数数量分布
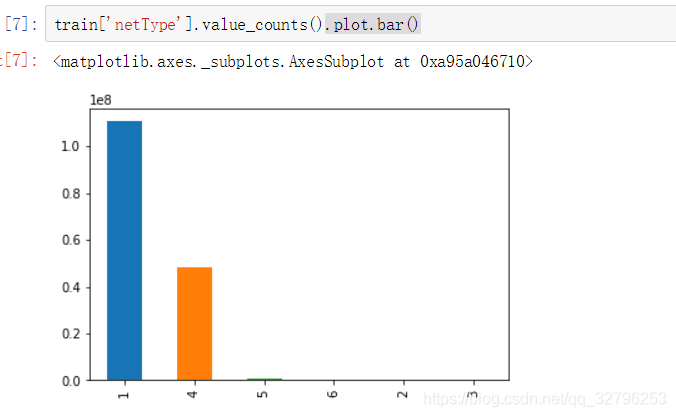
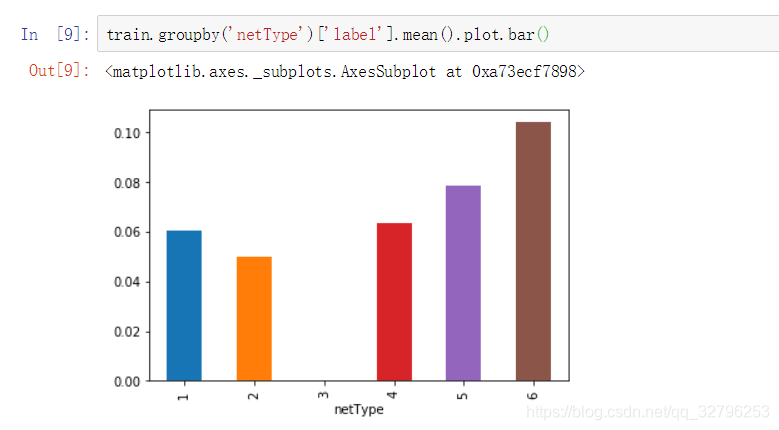
netType(网络连接类型)
对label的贡献度
id类信息
广告id 3111 素材id4236 useid 30846341
测试集
媒体id

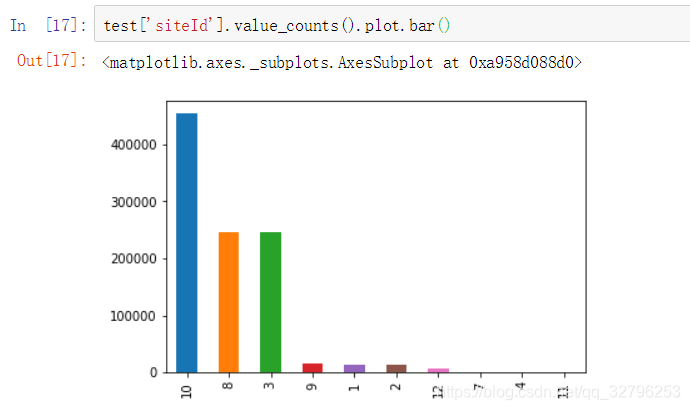
网络型号
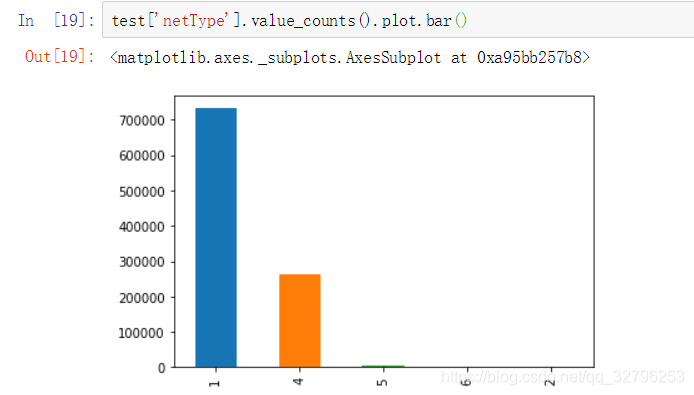
测试集与训练集分布
adID
train_user = train['uId'].unique()
train_ad = train['adId'].unique()
test_user = test['uId'].unique()
test_ad = test['adId'].unique()
ad_rate = len([i for i in test_ad if i in train_ad])/len(test_ad)
user_rate = len([i for i in test_user if i in train_user])/len(test_user)
发现ad的重复率为0.4左右,不太适合作为特征,或者建立含ID模型和不含ID模型
(后期会修改和更新)
而用户信息和其重合的个数很多,几乎没有新用户,那么用户id的使用就极为关键。
