需要解析httpd的日志
107.106.8.237.145 - - [12/Feb/2020:15:09:52 +0800] "GET /noindex/css/fonts/Light/OpenSans-Light.ttf HTTP/1.1" 404 240 "http://39.96.45.213/noindex/css/open-sans.css" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
fluentd配置
<source>
@id httpd
@type tail
path /data/logs/kim-todo-api-prod/log/statistics.log
pos_file /home/web_server/ingress-nginx/statistics.log.pos
tag *
read_from_head true
format /^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^ ]*) +\S*)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$/
</source>解析后的效果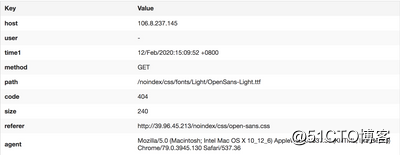
1、其中format 后面是正则匹配语句,
2、()表示捕获分组,()会把每个分组里的匹配的值保存起来,不难看出尖括号<>里面是一个key,圆括号()里的正则匹配出想要的value
3、(?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来,这里大家会有疑问 (?:) 里的字符照样被匹配出来里啊,这里有几个特殊用法
非捕获数组不参与编号分配但参与匹配
A:形如 (?: (exp))
也就是说exp中按照正常的分组逻辑进行分组
B:形如(?: ()|())
严格说这样写是解决选择缓存问题的写法(直接用圆括号会有一个副作用,是相关的匹配会被缓存,此时可用?:放在第一个选项前来消除这种副作用。)
C:形如 ((?: exp))
这种写法我认为等价于(exp)
4、圆括号外的中括号 []是去除一些无用字符
5、右斜杠 \ 是转义字符
6、\S 表示非空白就匹配 +表示 匹配前面的子表达式一次或多次
7、[^ ]* 表示匹配掉所有的空字符
8、?表示非贪婪匹配,即匹配到一个符合的就ok,不再继续匹配
9、表达式首尾有 " 表示匹配的是 "" 里的内容
10、+ 表示匹配前面的子表达式一次或多次