本人最近用python开发着爬虫相关的项目,在上个月就已经把爬虫的相关代码写得差不多了,因为春节,项目停滞了十多天。最近,当我再次运行之前的爬虫项目的时候,What?怎么不行了??本来好好的,报了521错误。我只是一个爬虫菜鸟,还是第一次接触到这个错误。然后我就去百度了。百度一圈后,发现这是一个js设置cookie的反爬方式。于是乎我将521返回的内容写到了txt文件里,显示出来是这样的结果。

太乱了,这样子啥也看不出来呀。后来突然想到,这就是js代码呀,写到html文件里再排版不就行了吗。这里说一下我用的编辑器是pycharm,打开了html代码后,使用快捷键'crtl+alt+l'一键排版,就好看多了。
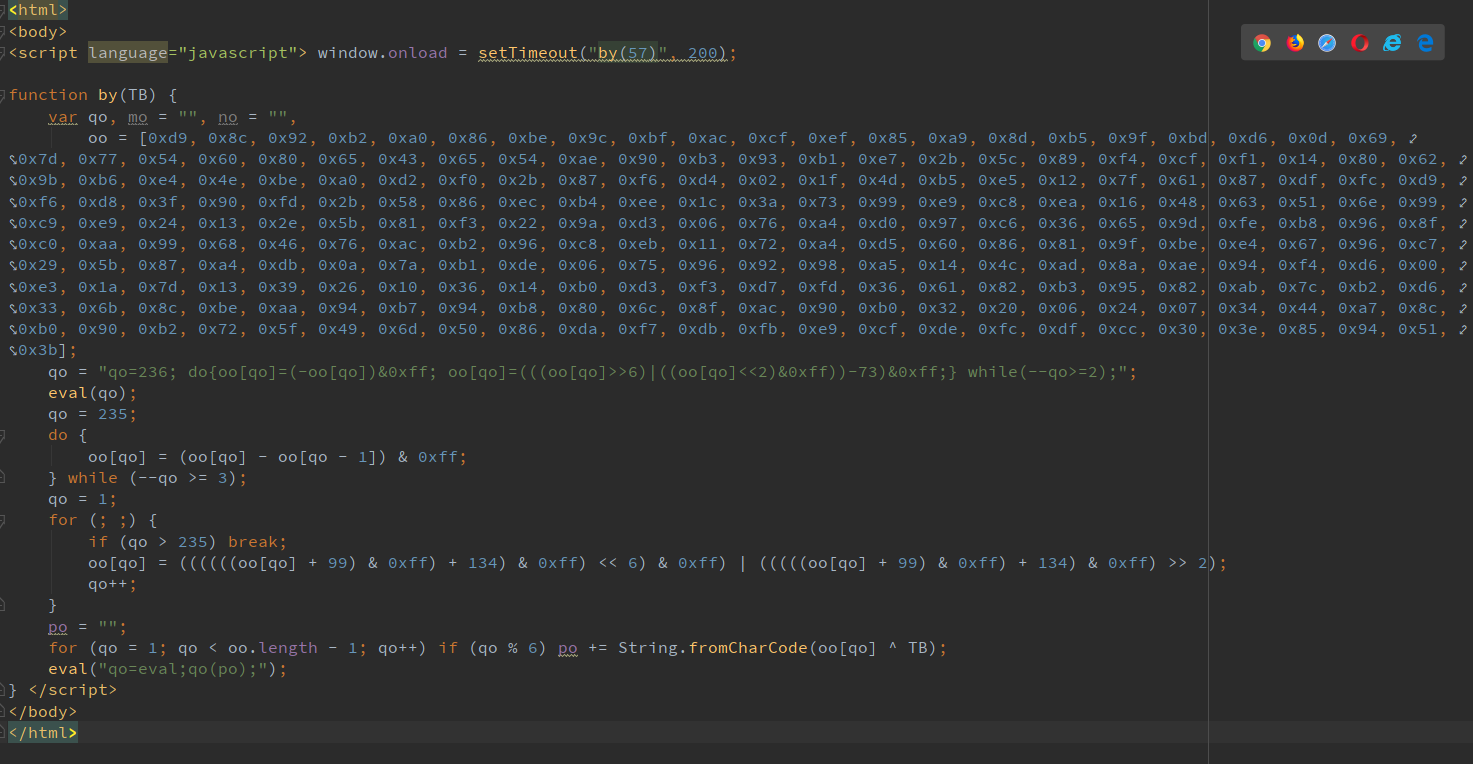
随后,我百度到,把这一串代码的js部分复制到Console中,将eval改成console.log运行。
 结果出现了这个错误,没怎么接触前端的我就傻逼了,这啥错啊。
结果出现了这个错误,没怎么接触前端的我就傻逼了,这啥错啊。
又百度了一会才发现,原来在后面的</script>前还有一个‘}’,写上去之后,可以正常运行了。得到了这个结果。

一看,怎么这么眼熟,这就是js里面的代码呀。然后我就想,打印出了这个结果,那是不是执行过程中,js会将这两行代码替换上去再执行的呢。然后我就将两行eval替换成打印出来这两行后再去执行。突然页面就直接跳转了一下。嗯?怎么就跳转了呢?后来想到,这是一个获取cookie的代码,那js是不是已经成功返回了cookie,所以直接就跳转了呢?因为在这里看不到最后的返回值是什么,所以我选择先用python执行一下再看结果。
到这里,我选择直接js代码的第三方库是pyexecjs,直接pip install PyExecJS就可以了。结果万万没想到,pip这一步竟然出错了。
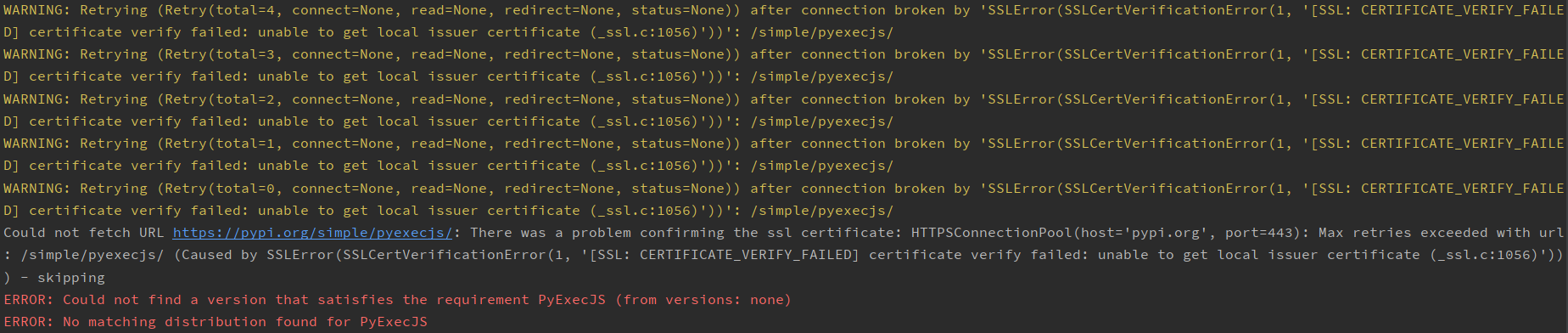
然后我突然想起,之前开的fidder代理开着,关了之后,就可以正常安装了。
好回归正题,准备好环境之后,也通过正则,将两个eval的地方,换成了console得到的代码,然后我开始运行这一段js代码。
'''python
ctx = execjs.compile(js)
result = ctx.call('by', 57)
print(result)
'''
这里解释一下,execjs.complie(js)返回的是ctx上下文对象,call()方法就是调用里面的某个函数。通过观察,发现里面的函数名和传的参数,每次都是不一样的,所以我通过正则,获取到函数名和参数,填进call里面。(如果每次返回的函数名和参数都不一样,可以用变量接收,再传参)
运行之后,不出意外,报错了。

 execjs._exceptions.ProcessExitedWithNonZeroStatus: (1, '', "[stdin]:24\n}, function(program).......
execjs._exceptions.ProcessExitedWithNonZeroStatus: (1, '', "[stdin]:24\n}, function(program).......
这个错误我也不知道啥错呀。后来留意到,我的js代码又少了括号了,加上去后,错误就换了。。。
execjs._exceptions.ProgramError: ReferenceError: window is not defined
这个错误说是window没有定义,我看了下js代码中,就一开头有一个windows呀,我想,那个window应该是调用函数和提供参数的吧,我已经直接call那个函数了,索性我就将前面的window那一句给去掉了。只剩函数部分。运行后,又出错了。
execjs._exceptions.ProgramError: ReferenceError: document is not defined
然后,这怎么又出错了啊。百度之后,我也没怎么看懂。然后我就留意到了,在整个js代码的最后是qo = eval;qo(po);我理解的是eval是返回一个结果,所以我直接将qo(po)换成return(po),再看运行的结果。然后惊喜的发现,结果出来了。哇!心里一个激动啊!
document.cookie='_ydclearance=046fa7a8f53a1e92e4d5374...
但是,这还没有结束,拿到了这一个结果而已,我又要怎么去用呢?然后我开始对比,跳转到请求页面的cookie和跳转前页面的cookie,我发现,请求页面的cookie只是多了_ydclearance的值,所以我大胆猜测,直接往请求头中的cookie加上这一个字段就行了吧。然后一试,成功访问!
好了,我的第一篇博客写完了,这只是希望和大家分享一下我处理这个521错误的过程,前辈们的分享。
最好,在这个关头,再说一句,武汉加油!中国加油!