1、在前面restTemplate的坑过后,问题又来了,因为数据量并发上去,数据库压力很大。cpu相对于之前的压力一直飙升不下。
在Linux服务器中定位问题
ps -ef | grep 服务名 查看pid
查看整个JVM内存状态
jmap -heap [pid]
要注意的是在使用CMS GC 情况下,jmap -heap的执行有可能会导致JAVA 进程挂起
查看JVM堆中对象详细占用情况
jmap -histo [pid]
导出整个JVM 中内存信息
jmap -dump:format=b,file=文件名 [pid]
dump 这一步很关键
jhat是sun 1.6及以上版本中自带的一个用于分析JVM 堆DUMP 文件的工具,基于此工具可分析JVM HEAP 中对象的内存占用情况
jhat -J-Xmx1024M [file]
执行后等待console 中输入start HTTP server on port 7000 即可使用浏览器访问 IP:7000
eclipse Memory Analyzer
Eclipse 提供的一个用于分析JVM 堆Dump文件的插件。借助这个插件可查看对象的内存占用状况,引用关系,分析内存泄露等。
采集下来的文件需要为bin类型,在分析的过程中,使用了Windows的电脑打开,直接报错,仔细查看了后,怀疑是内存溢出,直接放到mac打开,则等了十来分钟才能打开。具体的操作待我详细的整理后再提供参考。
当定位到问题后,发现是配置链接数过多。默认的database已经吃不下这么多链接数。
当时的配置为:
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="${DB.JDBC.DRIVER}" />
<property name="url" value="${DB.JDBC.URL}" />
<property name="username" value="${DB.USERNAME}" />
<property name="password" value="${DB.PASSWORD}" />
</bean>
查看了源码也是没有相关链接数的配置
因此选择了阿里的druid修改,代码量改动控制在最小范围内。
maven 引用
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.29</version>
</dependency>
<bean id="dataSource"
class="com.alibaba.druid.pool.DruidDataSource">
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="${DB.JDBC.INITIALSIZE}" />
<property name="minIdle" value="${DB.JDBC.MINLDLE}" />
<property name="maxActive" value="${DB.JDBC.MAXACTIVE}" />
<property name="driverClassName" value="${DB.JDBC.DRIVER}" />
<property name="url" value="${DB.JDBC.URL}" />
<property name="username" value="${DB.USERNAME}" />
<property name="password" value="${DB.PASSWORD}" />
</bean>
而且druid也配置了一些监控的事项,具体可以参考wiki
当配置完成后,上线。发现cpu效率提高了50%以上且内存也降低了50%。
有图有真相
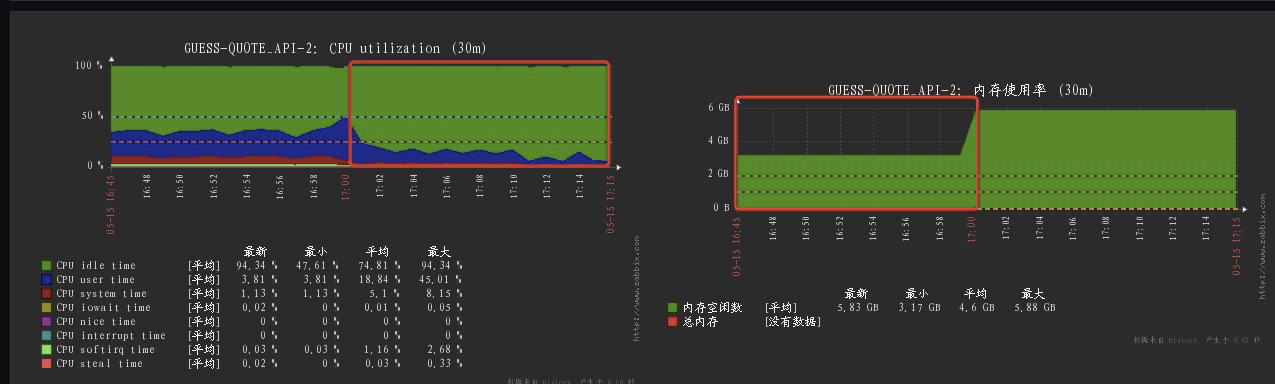
由此总结,将测试环境上的demo代码放到生产,需要对相应项目的承压能力以及配置信息进行评估,在合理的条件下进行压测,以便后续遇到不必要的八阿哥缠绕。
这个坑又顺利的抗过去了啦。