在本文中,我们将深入探讨Solidity事件 。 在野外,事件日志主要有三种用途:
- 由于事务不记录方法的返回值,因此ersatz返回值。
- 作为一种更便宜的替代数据存储,只要合同不需要访问它。
- 最后,作为DApp客户可以订阅的事件。
事件记录是一种相对复杂的语言功能。 但是就像方法一样,它们映射到更简单的EVM记录原语。
通过理解低级别EVM指令如何实现事件以及它们花费多少,我们将更有效地使用事件的直觉。
如果你是这个系列的新手,以前的文章:
固体事件
一个Solidity事件看起来像这样:
活动存款( 地址索引_from, bytes32索引_id, uint _value );
- 它有名称
Deposit。 - 它有三个不同类型的参数。
- 其中两种类型是“索引”的。
- 一个参数不是“索引的”。
Solidity事件有两个古怪的限制:
- 最多可能有3个索引参数。
- 如果索引参数的类型大于32字节(即字符串和字节),则实际数据不会被存储,而是存储数据的KECCAK256摘要。
这是为什么? 索引和非索引参数有什么区别?
EVM日志基元
要开始了解log0事件的这些怪癖和局限性,我们来看看log0 , log1 ,..., log4 EVM指令。
EVM日志记录工具使用与Solidity不同的术语:
- “主题”:最多可能有4个主题。 每个主题完全是32个字节。
- “数据”:数据是事件的有效载荷。 它可以是任意数量的字节。
Solidity事件如何映射到日志原语?
- 事件的所有“非索引参数”均作为数据存储。
- 事件的每个“索引参数”都存储为32字节的主题。
由于字符串和字节的长度可能超过32个字节,因此如果索引它们,则Solidity将存储KECCAK256摘要而不是实际数据。
Solidity可让您至多拥有3个索引参数,但EVM可让您至多拥有4个主题。 事实证明,Solidity为该活动的签名消耗了一个主题。
log0原始
最简单的日志记录是log0 。 这将创建一个只有数据但没有主题的日志项目。 日志的数据可以是任意数量的字节。
我们可以直接在log0中使用log0 。 在这个例子中,我们将存储一个32字节的数字:
杂注扎实度0.4.18;
合同记录器{ 函数Logger()public { log0(0xc0fefe); } }
生成的程序集可以分为两部分。 前半部分将堆栈中的日志数据( 0xc0fefe )复制到内存中。 第二部分将参数放在堆栈中,用于log0指令,告诉它在内存中的哪个位置加载数据。
注释的程序集:
内存:{0x40 => 0x60}
TAG_1: //将数据复制到内存中 0xc0fefe [0xc0fefe] MLOAD(0x40的) [0x60 0xc0fefe] swap1 [0xc0fefe 0x60] DUP2 [0x60 0xc0fefe 0x60] mstore [0X60] 记忆:{ 0x40 => 0x60 0x60 => 0xc0fefe }
//计算数据的开始位置和大小 为0x20 [0x20 0x60] 加 [0x80的] MLOAD(0x40的) [0x60 0x80] DUP1 [0x60 0x60 0x80] swap2 [0x60 0x80 0x60] 子 [0x20 0x60] swap1 [0x60 0x20]
log0
就在执行log0之前,堆栈中有两个参数: [0x60 0x20] 。
-
start:0x60是内存中加载数据的位置。 -
size:0x20(或32)指定要加载的数据的字节数。
log0的go-ethereum实现看起来像这样:
func log0(pc * uint64,evm * EVM,contract * Contract,memory * Memory,stack * Stack)([] byte,error){ mStart,mSize:= stack.pop(),stack.pop()
data:= memory.Get(mStart.Int64(),mSize.Int64())
evm.StateDB.AddLog(types.Log { 地址:contract.Address(), 数据:数据, //这是一个非共识字段,但在此分配是因为 //核心/状态不知道当前的块号。 BlockNumber:evm.BlockNumber.Uint64(), })
evm.interpreter.intPool.put(mStart,mSize) 返回零,零 }
你可以在这段代码中看到log0从栈中弹出两个参数,然后从内存中复制数据。 然后它调用StateDB.AddLog将日志与合约相关联。
记录与主题
主题是32个字节的任意数据。 以太坊实施将使用这些主题来为日志记录高效的事件日志查询和过滤。
这个例子使用log2原语。 第一个参数是数据(任意数量的字节),后面是2个主题(32个字节的eacb):
// log-2.sol 杂注扎实度0.4.18;
合同记录器{ 函数Logger()public { log2(0xc0fefe,0xaaaa1111,0xbbbb2222); } }
该组件非常相似。 唯一的区别是两个主题( 0xaaaa1111 )在开始时被压入堆栈:
TAG_1: //推送主题 0xbbbb2222 0xaaaa1111
//将数据复制到内存中 0xc0fefe MLOAD(0x40的) swap1 DUP2 mstore 为0x20 加 MLOAD(0x40的) DUP1 swap2 子 swap1
//创建日志 LOG2
数据仍然是0xc0fefe ,复制到内存中。 在执行log2之前,EVM的状态如下所示:
堆栈:[0x60 0x20 0xaaaa1111 0xbbbb2222] 记忆:{ 0x60:0xc0fefe }
LOG2
前两个参数指定要用作日志数据的内存区域。 两个额外的堆栈参数是两个32字节的主题。
所有EVM记录基元
EVM支持5个日志记录原语:
0xa0 LOG0 0xa1 LOG1 0xa2 LOG2 0xa3 LOG3 0xa4 LOG4
除了使用的主题数量之外,它们都是一样的。 以太坊实现实际上使用相同的代码生成这些指令,只是size不同,指定从堆栈弹出的主题数量。
func makeLog(size int)executionFunc { 返回func(pc * uint64,evm * EVM,合同*合同,内存*内存,堆栈*堆栈)([]字节,错误){ 主题:= make([] common.Hash,size) mStart,mSize:= stack.pop(),stack.pop() 对于i:= 0; 我<size; 我++ { topics [i] = common.BigToHash(stack.pop()) }
d:= memory.Get(mStart.Int64(),mSize.Int64()) evm.StateDB.AddLog(types.Log { 地址:contract.Address(), 主题:主题, 数据:d, //这是一个非共识字段,但在此分配是因为 //核心/状态不知道当前的块号。 BlockNumber:evm.BlockNumber.Uint64(), })
evm.interpreter.intPool.put(mStart,mSize) 返回零,零 } }
随意在sourcegraph上查看代码:
记录Testnet演示
我们尝试使用已部署的合约生成一些日志。 合同记录5次,使用不同的数据和主题:
杂注扎实度0.4.18;
合同记录器{ 函数Logger()public { log0(为0x0); log1(0x1,0xa); log2(0x2,0xa,0xb); log3(0x3,0xa,0xb,0xc); log4(0x4,0xa,0xb,0xc,0xd); } }
该合同部署在Rinkeby测试网络上。 创建此合同的交易是:
https://rinkeby.etherscan.io/tx/0x0e88c5281bb38290ae2e9cd8588cd979bc92755605021e78550fbc4d130053d1
点击“事件日志”标签,你会看到5个日志项目的原始数据:

主题全部是32个字节。 我们作为数据登录的编号被编码为32个字节的编号。
查询日志
让我们使用以太坊的JSON RPC来查询这些日志。 以太坊API节点将创建索引,以便通过匹配主题来查找日志,或查找由合同地址生成的日志。
我们将使用infura.io中友善的人提供的托管RPC节点。 您可以通过注册一个免费帐户来获取API密钥。
一旦获得密钥,请设置shell变量INFURA_KEY以使以下curl示例正常工作:
INFURA_KEY = my_infura_key_blah_blah_blah
举一个简单的例子,让我们调用eth_getLogs来获取与契约关联的所有日志:
卷曲“ https://rinkeby.infura.io/$INFURA_KEY ”\ -X POST \ -H“Content-Type:application / json”\ --data' { “jsonrpc”:“2.0”, “id”:1, “method”:“eth_getLogs”, “params”:[{ “fromBlock”:“0x0”, “地址”:“0x507e86b11541bcb1f3fe200b2f10ed8fd9413bd0” }] } “
-
fromBlock:从哪个块开始查找日志。 默认情况下,它开始查看区块链的顶端。 我们需要所有日志,所以我们从第一个块开始。 -
address:日志通过合同地址进行索引,所以这实际上非常有效。
输出是etherscan为“事件日志”选项卡显示的基础数据。 查看完整输出: evmlog.json 。
由JSON API返回的日志项目如下所示:
{ “地址”:“0x507e86b11541bcb1f3fe200b2f10ed8fd9413bd0”, “主题”: [ “0x000000000000000000000000000000000000000000000000000000000000000a” ] “数据”:“0x0000000000000000000000000000000000000000000000000000000000000001”, “blockNumber”:“0x179097”, “transactionHash”:“0x0e88c5281bb38290ae2e9cd8588cd979bc92755605021e78550fbc4d130053d1”, “transactionIndex”:“0x1”, “blockHash”:“0x541bb92d8de24cad637717cdc43ae5e66d9d6193b9f964fbb6461f6727eb9e57”, “logIndex”:“0x2”, “删除”:错误 }
接下来,我们可以查询与主题“0xc”匹配的日志:
卷曲“ https://rinkeby.infura.io/$INFURA_KEY ”\ -X POST \ -H“Content-Type:application / json”\ --data' { “jsonrpc”:“2.0”, “id”:1, “method”:“eth_getLogs”, “params”:[{ “fromBlock”:“0x179097”, “toBlock”:“0x179097”, “地址”:“0x507e86b11541bcb1f3fe200b2f10ed8fd9413bd0”, “主题”:[null,null,“0x000000000000000000000000000000000000000000000000000000000000000C”] }] } “
-
topics:要匹配的主题数组。null匹配任何内容。 查看详情 。
应该有两个匹配的日志:
{ “地址”:“0x507e86b11541bcb1f3fe200b2f10ed8fd9413bd0”, “主题”: [ “0x000000000000000000000000000000000000000000000000000000000000000a” “0x000000000000000000000000000000000000000000000000000000000000000b” “0x000000000000000000000000000000000000000000000000000000000000000c” ] “data”:“0x0000000000000000000000000000000000000000000000000000000000000003”, “blockNumber”:“0x179097”, “transactionHash”:“0x0e88c5281bb38290ae2e9cd8588cd979bc92755605021e78550fbc4d130053d1”, “transactionIndex”:“0x1”, “blockHash”:“0x541bb92d8de24cad637717cdc43ae5e66d9d6193b9f964fbb6461f6727eb9e57”, “logIndex”:“0x4”, “删除”:错误 }, { “地址”:“0x507e86b11541bcb1f3fe200b2f10ed8fd9413bd0”, “主题”: [ “0x000000000000000000000000000000000000000000000000000000000000000a” “0x000000000000000000000000000000000000000000000000000000000000000b” “0x000000000000000000000000000000000000000000000000000000000000000c” “0x000000000000000000000000000000000000000000000000000000000000000d” ] “数据”:“0x0000000000000000000000000000000000000000000000000000000000000004”, “blockNumber”:“0x179097”, “transactionHash”:“0x0e88c5281bb38290ae2e9cd8588cd979bc92755605021e78550fbc4d130053d1”, “transactionIndex”:“0x1”, “blockHash”:“0x541bb92d8de24cad637717cdc43ae5e66d9d6193b9f964fbb6461f6727eb9e57”, “logIndex”:“0x5”, “删除”:错误 }
记录燃气成本
记录原语的天然气成本取决于您拥有多少个主题以及您记录的数据量:
// LOG操作数据中的每个字节 LogDataGas uint64 = 8 //每个日志 topicLogTopicGas uint64 = 375 //每个LOG操作。 LogGas uint64 = 375
这些常量在protocol_params中定义。
不要忘记使用的内存,每个字节是3个气体:
MemoryGas uint64 = 3
等什么? 每个字节的日志数据只需要8个气体? 这是32个字节的256个气体,而内存使用的是96个气体。 因此,322个气体与20000个气体存储相同数量的数据,仅占成本的1.7%!

但是请等待,如果您将日志数据作为calldata传递给交易,则您还需要为交易数据付款。 卡尔达塔的天然气成本为:
TxDataZeroGas uint64 = 4 // zero tx data abyte TxDataNonZeroGas uint64 = 68 //非零tx数据字节
假设所有的32个字节都是非零的,这仍然比存储便宜很多:
// 32字节日志数据的成本 32 * 68 = 2176 // tx数据成本 32 * 8 = 256 //日志数据成本 32 * 3 = 96 //内存使用成本 375 //日志通话成本 ---- 总数(2176 + 256 + 96 + 375)
〜32%的sstore的14%
大部分的天然气成本实际上花费在交易数据上,而不是用于日志操作本身。
日志操作便宜的原因是因为日志数据并未真正存储在区块链中。 原则上,日志可以根据需要在运行中重新计算。 矿工,特别是可以简单地扔掉日志数据,因为未来的计算无论如何都无法访问过去的日志。
整个网络不承担日志成本。 只有API服务节点需要实际处理,存储和索引日志。
因此,日志成本结构只是防止日志垃圾邮件的最低成本。
固体事件
看到记录原语如何工作,Solidity事件很简单。
我们来看一个带有3个uint256参数(非索引)的Log事件类型:
杂注扎实度0.4.18;
合同记录器{ 事件日志(uint256 a,uint256 b,uint256 c); 函数日志(uint256 a,uint256 b,uint256 c)public { 日志(a,b,c); } }
而不是看汇编代码,让我们看看生成的原始日志。
这是一个调用log(1, 2, 3)的事务:
https://rinkeby.etherscan.io/tx/0x9d3d394867330ae75d7153def724d062b474b0feb1f824fe1ff79e772393d395
日志数据:
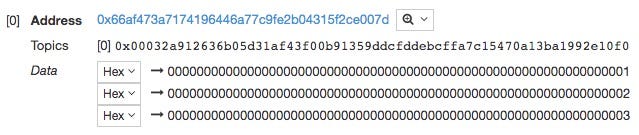
数据是事件参数,ABI编码:
0000000000000000000000000000000000000000000000000000000000000001 0000000000000000000000000000000000000000000000000000000000000002 0000000000000000000000000000000000000000000000000000000000000003
有一个主题,一个神秘的32字节哈希:
0x00032a912636b05d31af43f00b91359ddcfddebcffa7c15470a13ba1992e10f0
这是Event类型签名的SHA3哈希值:
#安装pyethereum #https ://github.com/ethereum/pyethereum/#installation >从ethereum.utils导入sha3 > sha3(“Log(uint256,uint256,uint256)”)。hex() '00032a912636b05d31af43f00b91359ddcfddebcffa7c15470a13ba1992e10f0'
这与方法调用的ABI编码工作非常相似。
由于Solidity事件对事件签名使用一个主题,因此只有3个主题留给索引参数。
带索引参数的固结事件
我们来看一个具有索引uint256参数的事件:
杂注扎实度0.4.18;
合同记录器{ 事件日志(uint256 a,uint256索引b,uint256 c); 函数日志(uint256 a,uint256 b,uint256 c)public { 日志(a,b,c); } }
生成的事件日志:
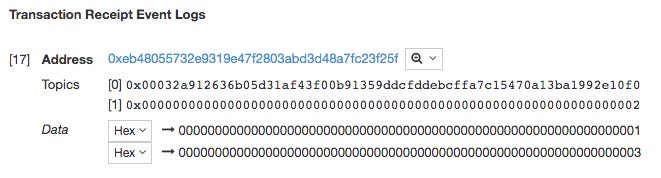
现在有两个主题:
0x00032a912636b05d31af43f00b91359ddcfddebcffa7c15470a13ba1992e10f0 0x0000000000000000000000000000000000000000000000000000000000000002
- 第一个主题是事件类型签名,散列。
- 第二个主题就是索引参数。
数据是ABI编码的事件参数,不包括索引参数:
0000000000000000000000000000000000000000000000000000000000000001 0000000000000000000000000000000000000000000000000000000000000003
字符串/字节事件参数
现在让我们将事件参数更改为字符串:
杂注扎实度0.4.18;
合同记录器{ 事件日志(字符串a,字符串索引b,字符串c); 函数日志(字符串a,字符串b,字符串c)public { 日志(a,b,c); } }
用log("a", "b", "c")生成log("a", "b", "c") 。 交易是:
https://rinkeby.etherscan.io/tx/0x21221c2924bbf1860db9e098ab98b3fd7a5de24dd68bab1ea9ce19ae9c303b56
有两个主题:
0xb857d3ea78d03217f929ae616bf22aea6a354b78e5027773679b7b4a6f66e86b 0xb5553de315e0edf504d9150af82dafa5c4667fa618ed0a6f19c69b41166c5510
- 第一个话题也是方法签名。
- 第二个主题是字符串参数的sha256摘要。
让我们验证“b”的散列与第二个主题相同:
>>> sha3(“b”).hex() 'b5553de315e0edf504d9150af82dafa5c4667fa618ed0a6f19c69b41166c5510'
日志数据是两个非索引字符串“a”和“c”,ABI编码:
0000000000000000000000000000000000000000000000000000000000000040 0000000000000000000000000000000000000000000000000000000000000080 0000000000000000000000000000000000000000000000000000000000000001 6100000000000000000000000000000000000000000000000000000000000000 0000000000000000000000000000000000000000000000000000000000000001 6300000000000000000000000000000000000000000000000000000000000000
不幸的是,没有存储索引字符串参数的原始字符串,所以DApp客户端无法恢复它。
如果您真的需要原始字符串,只需记录两次,包括索引和非索引:
事件日志(字符串a,字符串索引indexedB,字符串b);
日志(“a”,“b”,“b”);
有效查询日志
我们如何找到第一个主题匹配“0x000 ... 001”的所有日志? 天真地说,我们可以从创世区块开始,并重新执行每一个事务,并查看生成的日志是否符合我们的过滤条件。 这不好。
事实证明,块头包含足够的信息,可以让我们快速跳过没有我们想要的日志的块。
块标题包含像父散列,uncles散列库和类似这个块中包含的事务生成的所有日志的布隆筛选器的信息。 看起来像:
类型头结构{
ParentHash common.Hash`json:“parentHash”gencodec:“required”`
UncleHash common.Hash`json:“sha3Uncles”gencodec:“required”`
Coinbase common.Address`json:“miner”gencodec:“required”`
// ...
//布隆过滤器由收集事务列表中每个事务的每个日志条目中包含的可索引信息(记录器地址和日志主题)组成 Bloom Bloom`json:“logsBloom”gencodec:“required”` }
布隆过滤器是固定的256字节数据结构。 它的行为类似于set,你可以问它是否存在一个主题。
所以我们可以像这样优化日志查询过程:
对于链中的块: #检查布隆过滤器以快速过滤出一个块 如果不是block.Bloom.exist(topic): 下一个
#块可能有我们想要的日志,重新执行 对于block.transactions中的tx: 用于登录tx.recalculateLogs(): 如果log.topic [0] .matches(主题) 产量日志
除主题外,发布日志的合同地址也被添加到布隆过滤器。
BloomBitsTrie
以太坊主网在2018年1月拥有大约5,000,000个块,并且遍历所有块仍然可能相当昂贵,因为您需要从磁盘加载块头。
平均块头大约500字节,你总共会加载2.5GB的数据。
FelföldiZsolt在PR# 14970中实施了BloomBitsTrie,使日志过滤更快。 我们的想法是,不是分别查看每个块的布隆过滤器,而是可以设计一个同时查看32768个块的数据结构。
为了理解接下来的内容,至少需要了解bloom过滤器的一点是,将一段数据“散列”到bloom过滤器中的3个随机(但是确定性)位并将它们设置为1.为了检查是否存在,我们检查是否存在这3位被设置为1。
以太坊使用的布隆过滤器为2048位。
假设主题“0xa”将bloom过滤器的第16,632和777位设置为1. BloomBits Trie是2048 x 32768位图。 索引BloomBits结构给我们三个32768位向量:
BloomBits [15] => 32768位矢量(4096字节) BloomBits [631] => 32768位矢量(4096字节) BloomBits [776] => 32768位向量(4096字节)
这些位向量告诉我们哪些块的bloom滤波器的第16,632和777位设置为1。
我们来看看这些向量的前8位,这可能看起来像
10110001 ... 00101101 ... 10101001 ...
- 第1个块的第16和第776位设置为1,但不是第631位。
- 第三块有三个全部位。
- 第8块有三个全部位。
然后,我们可以通过对这些向量应用binary-AND来快速找到匹配所有三位的块:
00100001 ...
最终的位向量告诉我们32768中的哪些块匹配我们的过滤条件。
要匹配多个主题,我们只需为每个主题执行相同的索引,然后将二进制和最终的位向量组合在一起。
请参阅BloomBits Trie了解有关这些工作原理的更多详细信息。
结论
总之,一个EVM日志最多可以有4个主题,任意数量的字节作为数据。 Solidity事件的非索引参数是ABI编码的数据,以及用作日志主题的索引参数。
存储日志数据的天然气成本比正常存储要便宜得多,因此只要您的合同不需要访问数据,您可以将其视为DApp的替代选择。
日志记录设施的两种替代设计选择可能是:
- 允许更多主题,但更多主题会降低用于按主题索引日志的bloom过滤器的有效性。
- 允许主题具有任意数量的字节。 为什么不?
https://blog.qtum.org/how-solidity-events-are-implemented-diving-into-the-ethereum-vm-part-6-30e07b3037b9