0902-用户访问会话统计
需求一: 各个范围会话步长, 访问时长占比统计
- 访问时长:session的最早时间与最晚时间之差。
- 访问步长:session中的action个数。
1.1 需求概述
统计出符合筛选条件的session中,访问时长在1s~ 3s、4s~ 6s、7s~ 9s、10s~ 30s、30s~ 60s、1m~ 3m、3m~ 10m、10m~30m、30m,访问步长在1_3、4_6、…以上各个范围内的各种session的占比。
1.2 简要运行流程

1.3 具体运行流程

1.4 代码实现
1.4.1 按照日期范围获取数据
// 1. 获取原始的动作表数据(获取某个时间范围的数据)
val actionRDD: RDD[UserVisitAction] = getOriActionRDD(sparkSession, taskParam)
def getOriActionRDD(sparkSession: SparkSession, taskParam: JSONObject) = {
val startDate: String = ParamUtils.getParam(taskParam, Constants.PARAM_START_DATE)
val endDate: String = ParamUtils.getParam(taskParam, Constants.PARAM_END_DATE)
val sql = "select * from user_visit_action where date >= '" + startDate + "' and date <= '" + endDate + "'"
import sparkSession.implicits._
//UserVisitAction 是一个Case类
val actionRDD: RDD[UserVisitAction] = sparkSession.sql(sql).as[UserVisitAction].rdd
actionRDD
}
1.4.2 转换为K-V格式,SessionID作为key
// 2. 转换为k-v格式, sessionId 作为Key
val sessionId2ActionRDD: RDD[(String, UserVisitAction)] =
actionRDD.map(action => (action.session_id, action))
1.4.3 按照SessionID进行聚合
// 3. 按照sessionId进行聚合
val sessionId2ActionsRDD: RDD[(String, Iterable[UserVisitAction])] = sessionId2ActionRDD.groupByKey()
// (e37ccd88e5a24edfbdc22092588d52af,CompactBuffer(UserVisitAction(2019-12-22,67,e37ccd88e5a24edfbdc22092588d52af,9,2019-12-22 16:55:11,null,-1,-1,null,null,74,93,1), UserVisitAction(2019-12-22,67,e37ccd88e5a24edfbdc22092588d52af,4,2019-12-22 16:09:26,null,-1,-1,null,null,73,12,7), UserVisitAction(2019-12-22,67,e37ccd88e5a24edfbdc22092588d52af,4,2019-12-22 16:10:12,null,38,32,null,null,null,null,4)))
1.4.4 分别计算当前Session所有访问行为,访问时长和访问步长
// 4. 分别计算当前Session所有访问行为,包括访问时长、访问步长等
val userId2PartAggrInfoRDD: RDD[(Long, String)] = getSessionPartInfoRDD(sparkSession, sessionId2ActionsRDD)
def getSessionPartInfoRDD(sparkSession: SparkSession, sessionId2ActionsRDD: RDD[(String, Iterable[UserVisitAction])]) = {
// Session_Id | Search_KeyWords | Click_category_Id | Visit_Length | Step_Length | Start_Time
val userId2AggrInfoRDD = sessionId2ActionsRDD.map {
case (sessionId, iterableAction) =>
// 初始化字段
var userId = -1L
var startTime: Date = null
var endTime: Date = null
var stepLength = 0
val searchKeyWords = new StringBuffer("")
val clickCategories = new StringBuffer("")
for (action <- iterableAction) {
// 更新字段
if (userId == -1) {
userId = action.user_id
}
val actionTime = DateUtils.parseTime(action.action_time)
if (startTime == null || startTime.after(actionTime)) {
startTime = actionTime
}
if (endTime == null || endTime.before(actionTime)) {
endTime = actionTime
}
val searchKeyWord = action.search_keyword
if (StringUtils.isNotEmpty(searchKeyWord) && !searchKeyWords.toString.contains(searchKeyWord)) {
searchKeyWords.append(searchKeyWord + ",")
}
val clickCategoryId = action.click_category_id
if (clickCategoryId != -1 && !clickCategories.toString.contains(clickCategoryId)) {
clickCategories.append(clickCategoryId + ",")
}
stepLength += 1
}
// 处理字段
val searchKw: String = StringUtils.trimComma(searchKeyWords.toString)
val clickCg: String = StringUtils.trimComma(clickCategories.toString)
val visitLength = (endTime.getTime - startTime.getTime) / 1000
// 拼接字段
val aggrInfo = Constants.FIELD_SESSION_ID + "=" + sessionId + "|" +
Constants.FIELD_SEARCH_KEYWORDS + "=" + searchKw + "|" +
Constants.FIELD_CLICK_CATEGORY_IDS + "=" + clickCg + "|" +
Constants.FIELD_VISIT_LENGTH + "=" + visitLength + "|" +
Constants.FIELD_STEP_LENGTH + "=" + stepLength + "|" +
Constants.FIELD_START_TIME + "=" + DateUtils.formatTime(startTime)
// (29,sessionid=ab100e687ac546d2813f0b723b89e023|searchKeywords=苹果,洗面奶|clickCategoryIds=86,34,76,96,86,10|visitLength=3167|stepLength=19|startTime=2019-12-22 19:34:45)
(userId, aggrInfo)
}
userId2AggrInfoRDD
}
1.4.5 获取用户表并转为K-V格式
// 5. 获取用户表信息并转换为K-V格式
val userId2InfoRDD: RDD[(Long, UserInfo)] = getOriUserInfoRDD(sparkSession)
def getOriUserInfoRDD(sparkSession: SparkSession) = {
val sql = "select * from user_info"
import sparkSession.implicits._
val userId2InfoRDD: RDD[(Long, UserInfo)] = sparkSession.sql(sql).as[UserInfo].rdd.map(item => (item.user_id, item))
userId2InfoRDD
}
1.4.6 用户表和Session表做连接
// 6. 用户表和Session表做连接
val userId2FullInfoRDD: RDD[(Long, (String, UserInfo))] = userId2PartAggrInfoRDD.join(userId2InfoRDD)
1.4.7 将用户的相关信息加入
// 7. 将用户信息相关信息加入
val sessionId2AggrInfoRDD: RDD[(String, String)] = getSessionFullRDD(sparkSession, userId2FullInfoRDD)
def getSessionFullRDD(sparkSession: SparkSession, userId2FullInfo: RDD[(Long, (String, UserInfo))]) = {
val sessionId2FullInfoRDD: RDD[(String, String)] = userId2FullInfo.map {
case (userId, (aggrInfo, userInfo)) =>
val age = userInfo.age
val professional = userInfo.professional
val sex = userInfo.sex
val city = userInfo.city
val fullInfo = aggrInfo + "|" +
Constants.FIELD_AGE + "=" + age + "|" +
Constants.FIELD_PROFESSIONAL + "=" + professional + "|" +
Constants.FIELD_SEX + "=" + sex + "|" +
Constants.FIELD_CITY + "=" + city
val sessionId = StringUtils.getFieldFromConcatString(aggrInfo, "\\|", Constants.FIELD_SESSION_ID)
(sessionId, fullInfo)
}
sessionId2FullInfoRDD
}
1.4.8 根据查询条件,过滤数据集,将符合条件的数据进行累加器的更新,更新Session访问总数、更新Session访问时长范围、更新Session访问步长范围
// 8. 根据查询条件,过滤数据集,将符合条件的数据进行累加器的更新,更新Session访问总数、更新Session访问时长范围、更新Session访问步长范围
val acc = new SessionAccumulator
sparkSession.sparkContext.register(acc)
val filteredSessionId2AggrInfoRDD: RDD[(String, String)] = getSessionFilterRDD(sessionId2AggrInfoRDD, taskParam, acc)
def getSessionFilterRDD(sessionId2AggrInfo: RDD[(String, String)], taskParam: JSONObject, sessionAccumulator: SessionAccumulator) = {
val startAge = ParamUtils.getParam(taskParam, Constants.PARAM_START_AGE)
val endAge = ParamUtils.getParam(taskParam, Constants.PARAM_END_AGE)
val professionals = ParamUtils.getParam(taskParam, Constants.PARAM_PROFESSIONALS)
val cities = ParamUtils.getParam(taskParam, Constants.PARAM_CITIES)
val sex = ParamUtils.getParam(taskParam, Constants.PARAM_SEX)
val keywords = ParamUtils.getParam(taskParam, Constants.PARAM_KEYWORDS)
val categoryIds = ParamUtils.getParam(taskParam, Constants.PARAM_CATEGORY_IDS)
var filterInfo =
(if (startAge != null) Constants.PARAM_START_AGE + "=" + startAge + "|" else "") +
(if (endAge != null) Constants.PARAM_END_AGE + "=" + endAge + "|" else "") +
(if (professionals != null) Constants.PARAM_PROFESSIONALS + "=" + professionals + "|" else "") +
(if (cities != null) Constants.PARAM_CITIES + "=" + cities + "|" else "") +
(if (sex != null) Constants.PARAM_SEX + "=" + sex + "|" else "") +
(if (keywords != null) Constants.PARAM_KEYWORDS + "=" + keywords + "|" else "") +
(if (categoryIds != null) Constants.PARAM_CATEGORY_IDS + "=" + categoryIds else "")
if (filterInfo.endsWith("\\|")) {
filterInfo = filterInfo.substring(0, filterInfo.length - 1)
}
sessionId2AggrInfo.filter {
case (sessionId, fullInfo) =>
var success = true
if (!ValidUtils.between(fullInfo, Constants.FIELD_AGE, filterInfo, Constants.PARAM_START_AGE, Constants.PARAM_END_AGE)) {
success = false
} else if (!ValidUtils.in(fullInfo, Constants.FIELD_PROFESSIONAL, filterInfo, Constants.PARAM_PROFESSIONALS)) {
success = false
} else if (!ValidUtils.in(fullInfo, Constants.FIELD_CITY, filterInfo, Constants.PARAM_CITIES)) {
success = false
} else if (!ValidUtils.equal(fullInfo, Constants.FIELD_SEX, filterInfo, Constants.PARAM_SEX)) {
success = false
} else if (!ValidUtils.in(fullInfo, Constants.FIELD_SEARCH_KEYWORDS, filterInfo, Constants.PARAM_KEYWORDS)) {
success = false
} else if (!ValidUtils.in(fullInfo, Constants.FIELD_CLICK_CATEGORY_IDS, filterInfo, Constants.PARAM_CATEGORY_IDS)) {
success = false
}
if (success) {
// 符合条件的数据, 更新累加器的值
sessionAccumulator.add(Constants.SESSION_COUNT)
val visitLength = StringUtils.getFieldFromConcatString(fullInfo, "\\|", Constants.FIELD_VISIT_LENGTH).toLong
val stepLength = StringUtils.getFieldFromConcatString(fullInfo, "\\|", Constants.FIELD_STEP_LENGTH).toLong
calculateVisitLength(visitLength, sessionAccumulator)
calculateStepLength(stepLength, sessionAccumulator)
}
success
}
}
- 自定义累加器
package com.lz.session
import org.apache.spark.util.AccumulatorV2
import scala.collection.mutable
class SessionAccumulator extends AccumulatorV2[String, mutable.HashMap[String, Int]] {
private val countMap = new mutable.HashMap[String, Int]()
override def isZero: Boolean = {
countMap.isEmpty
}
override def copy(): AccumulatorV2[String, mutable.HashMap[String, Int]] = {
val acc = new SessionAccumulator
// ++= 集合合并 改变左值
acc.countMap ++= this.countMap
acc
}
override def reset(): Unit = {
countMap.clear()
}
override def add(v: String): Unit = {
if (!this.countMap.contains(v)) {
this.countMap += (v -> 0)
}
this.countMap.update(v, countMap(v) + 1)
}
override def merge(other: AccumulatorV2[String, mutable.HashMap[String, Int]]): Unit = {
other match {
case acc: SessionAccumulator => acc.countMap.foldLeft(this.countMap) {
case (map, (k, v)) => map += (k -> (map.getOrElse(k, 0) + v))
}
}
}
override def value: mutable.HashMap[String, Int] = {
this.countMap
}
}
1.4.9 获取累加器中的数据,并计算最终结果
// 需要一个行动算子,触发
filteredSessionId2AggrInfoRDD.foreach(println(_))
// 9. (需求一)获取累加器中的数据,并计算最终结果,将结果保存到MySQL数据库中
val sessionAggrStatRDD: RDD[SessionAggrStat] = getSessionRationRDD(sparkSession, taskUUID, filteredSessionId2AggrInfoRDD, acc.value)
def getSessionRationRDD(sparkSession: SparkSession, taskUUID: String, filteredSessionId2AggrInfoRDD: RDD[(String, String)], value: mutable.HashMap[String, Int]) = {
val session_count: Double = value.getOrElse(Constants.SESSION_COUNT, 1).toDouble
val visit_length_1s_3s = value.getOrElse(Constants.TIME_PERIOD_1s_3s, 0)
val visit_length_4s_6s = value.getOrElse(Constants.TIME_PERIOD_4s_6s, 0)
val visit_length_7s_9s = value.getOrElse(Constants.TIME_PERIOD_7s_9s, 0)
val visit_length_10s_30s = value.getOrElse(Constants.TIME_PERIOD_10s_30s, 0)
val visit_length_30s_60s = value.getOrElse(Constants.TIME_PERIOD_30s_60s, 0)
val visit_length_1m_3m = value.getOrElse(Constants.TIME_PERIOD_1m_3m, 0)
val visit_length_3m_10m = value.getOrElse(Constants.TIME_PERIOD_3m_10m, 0)
val visit_length_10m_30m = value.getOrElse(Constants.TIME_PERIOD_10m_30m, 0)
val visit_length_30m = value.getOrElse(Constants.TIME_PERIOD_30m, 0)
val step_length_1_3 = value.getOrElse(Constants.STEP_PERIOD_1_3, 0)
val step_length_4_6 = value.getOrElse(Constants.STEP_PERIOD_4_6, 0)
val step_length_7_9 = value.getOrElse(Constants.STEP_PERIOD_7_9, 0)
val step_length_10_30 = value.getOrElse(Constants.STEP_PERIOD_10_30, 0)
val step_length_30_60 = value.getOrElse(Constants.STEP_PERIOD_30_60, 0)
val step_length_60 = value.getOrElse(Constants.STEP_PERIOD_60, 0)
val visit_length_1s_3s_ratio = NumberUtils.formatDouble(visit_length_1s_3s / session_count, 2)
val visit_length_4s_6s_ratio = NumberUtils.formatDouble(visit_length_4s_6s / session_count, 2)
val visit_length_7s_9s_ratio = NumberUtils.formatDouble(visit_length_7s_9s / session_count, 2)
val visit_length_10s_30s_ratio = NumberUtils.formatDouble(visit_length_10s_30s / session_count, 2)
val visit_length_30s_60s_ratio = NumberUtils.formatDouble(visit_length_30s_60s / session_count, 2)
val visit_length_1m_3m_ratio = NumberUtils.formatDouble(visit_length_1m_3m / session_count, 2)
val visit_length_3m_10m_ratio = NumberUtils.formatDouble(visit_length_3m_10m / session_count, 2)
val visit_length_10m_30m_ratio = NumberUtils.formatDouble(visit_length_10m_30m / session_count, 2)
val visit_length_30m_ratio = NumberUtils.formatDouble(visit_length_30m / session_count, 2)
val step_length_1_3_ratio = NumberUtils.formatDouble(step_length_1_3 / session_count, 2)
val step_length_4_6_ratio = NumberUtils.formatDouble(step_length_4_6 / session_count, 2)
val step_length_7_9_ratio = NumberUtils.formatDouble(step_length_7_9 / session_count, 2)
val step_length_10_30_ratio = NumberUtils.formatDouble(step_length_10_30 / session_count, 2)
val step_length_30_60_ratio = NumberUtils.formatDouble(step_length_30_60 / session_count, 2)
val step_length_60_ratio = NumberUtils.formatDouble(step_length_60 / session_count, 2)
val stat = SessionAggrStat(taskUUID, session_count.toInt, visit_length_1s_3s_ratio, visit_length_4s_6s_ratio, visit_length_7s_9s_ratio,
visit_length_10s_30s_ratio, visit_length_30s_60s_ratio, visit_length_1m_3m_ratio,
visit_length_3m_10m_ratio, visit_length_10m_30m_ratio, visit_length_30m_ratio,
step_length_1_3_ratio, step_length_4_6_ratio, step_length_7_9_ratio,
step_length_10_30_ratio, step_length_30_60_ratio, step_length_60_ratio
)
val sessionAggrStat: RDD[SessionAggrStat] = sparkSession.sparkContext.makeRDD(Array(stat))
sessionAggrStat
}
1.4.10 数据写入数据库
// 10. 数据写入数据库
writeRDD2Mysql(sparkSession, sessionAggrStatRDD)
def writeRDD2Mysql(sparkSession: SparkSession, sessionAggrStatRDD: RDD[SessionAggrStat]): Unit = {
import sparkSession.implicits._
sessionAggrStatRDD.toDF()
.write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.option("dbtable", "session_stat_ratio")
.mode(SaveMode.Append)
.save()
}
需求二: 随机抽取会话
2.1 需求概述
在符合过滤条件的session中,按照时间比例随机抽取100个session。当存在若干天的数据时,100个session抽取指标在天之间平均分配,在一天之中,根据某个小时的session数量在一天中总session数量中的占比决定这个小时抽取多少个session。
明确一共要抽取多少session
明确每天要抽取多少session
明确每天有多少session
明确每小时有多少session
明确每小时抽取多少session
根据每小时抽取数量生成随机索引
按照随机索引抽取实际的一个小时中的session
需要解决两个问题:
- 每小时抽多少
- 怎么抽
一个小时要抽取的session数量 = (这个小时的session数量/这一天的session数量) * 这一天要抽取的session数量
明确一个小时抽取多少session后(假设为N个),根据数量产生N个随机数,这N个随机数组成的列表就是要抽取的session的索引列表,我们假设按照hour聚合后的session数据可以从0开始编号,如果session对应的索引存在于列表中,那么就抽取此session,否则不抽取。
2.2 简要运行流程
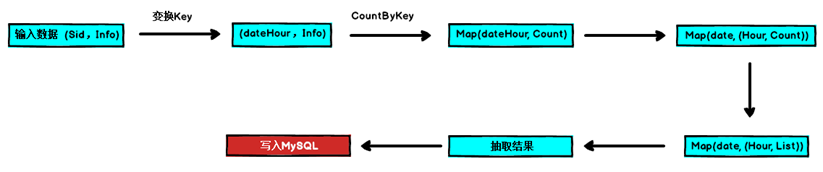
2.3 具体运行流程

2.4 代码实现
2.4.1 转换格式, 以dateHour作为key
// 1. 转换格式, 以dateHour作为key
val dateHour2FullInfoRDD: RDD[(String, String)] = filteredSessionId2AggrInfoRDD.map {
case (sessionId, fullInfo) =>
val startTime: String = StringUtils.getFieldFromConcatString(fullInfo, "\\|", Constants.FIELD_START_TIME)
val dateHour: String = DateUtils.getDateHour(startTime)
(dateHour, fullInfo)
}
2.4.2 计算每小时的Session总数

// 2. 计算每小时的Session总数
val dateHour2Count: collection.Map[String, Long] = dateHour2FullInfoRDD.countByKey()
2.4.3 转换格式, date做key, < hour, count >做value

// 3. 转换格式, date做key, <hour, count>做value
val date2HourCount = new mutable.HashMap[String, mutable.HashMap[String, Long]]()
for ((dateHour, count) <- dateHour2Count) {
val date: String = dateHour.split("_")(0)
val hour: String = dateHour.split("_")(1)
date2HourCount.get(date) match {
case None =>
date2HourCount(date) = new mutable.HashMap[String, Long]()
date2HourCount(date) += (hour -> count)
case Some(x) =>
date2HourCount(date) += (hour -> count)
}
}
2.4.4 产生随机索引

// 4. 产生随机索引
// 4.1 每天抽取的数量, date2HourCount.size 是总的天数
val extractPerDay = 100 / date2HourCount.size
// 4.2 创建索引Map
val date2HourRandomIndex = new mutable.HashMap[String, mutable.HashMap[String, ListBuffer[Int]]]()
for ((date, hour2count) <- date2HourCount) {
// 4.3 计算每天的索引总数
val dateCount = hour2count.values.sum
date2HourRandomIndex.get(date) match {
case None =>
date2HourRandomIndex(date) = new mutable.HashMap[String, ListBuffer[Int]]()
generateRandomIndex(extractPerDay, dateCount, hour2count, date2HourRandomIndex(date))
case Some(x) =>
generateRandomIndex(extractPerDay, dateCount, hour2count, date2HourRandomIndex(date))
}
}
// 产生随机索引
/*
extractPerDay : 一天抽取的session数
dateCount : 一天的session总数
hour2count : <hour, count> 每小时的session数量
hour2Index : <hour, index[Arraybuffer]>
*/
def generateRandomIndex(extractPerDay: Int, dateCount: Long, hour2count: mutable.HashMap[String, Long], hour2Index: mutable.HashMap[String, ListBuffer[Int]]) = {
val random = new Random()
//一个小时要抽取的session数量 = (这个小时的session数量/这一天的session数量) * 这一天要抽取的session数量
for ((hour, count) <- hour2count) {
var hourExtractSessionCount = ((count / dateCount.toDouble) * extractPerDay).toInt
if (hourExtractSessionCount > count.toInt) {
hourExtractSessionCount = count.toInt
}
hour2Index.get(hour) match {
case None =>
hour2Index(hour) = new ListBuffer[Int]
for (i <- 0 until hourExtractSessionCount) {
var index = random.nextInt(count.toInt)
while (hour2Index(hour).contains(index)) {
index = random.nextInt(count.toInt)
}
hour2Index(hour) += index
}
case Some(x) =>
for (i <- 0 until hourExtractSessionCount) {
var index = random.nextInt(count.toInt)
while (hour2Index(hour).contains(index)) {
index = random.nextInt(count.toInt)
}
hour2Index(hour) += index
}
}
}
}
2.4.5 广播大变量
// 5. 广播大变量
val dateHourExtractIndexListBd = sparkSession.sparkContext.broadcast(date2HourRandomIndex)
2.4.6 将每小时的session访问数据进行聚合
// 6. 将每小时的session访问数据进行聚合
val dateHour2FullInfosRDD: RDD[(String, Iterable[String])] = dateHour2FullInfoRDD.groupByKey()
2.4.7 根据广播变量, 对数据进行抽取
// 7. 根据广播变量, 对数据进行抽取
val extractSessionRDD: RDD[SessionRandomExtractModel] = dateHour2FullInfosRDD.flatMap {
case (dateHour, fullInfos) =>
val date = dateHour.split("_")(0)
val hour = dateHour.split("_")(1)
// 7.1 获取广播变量的值
val extractList: ListBuffer[Int] = dateHourExtractIndexListBd.value.get(date).get(hour)
val extractSessionArrayBuffer = new ArrayBuffer[SessionRandomExtractModel]()
var index = 0
for (fullInfo <- fullInfos) {
if (extractList.contains(index)) {
val sessionId = StringUtils.getFieldFromConcatString(fullInfo, "\\|", Constants.FIELD_SESSION_ID)
val startTime = StringUtils.getFieldFromConcatString(fullInfo, "\\|", Constants.FIELD_START_TIME)
val searchKeywords = StringUtils.getFieldFromConcatString(fullInfo, "\\|", Constants.FIELD_SEARCH_KEYWORDS)
val clickCategories = StringUtils.getFieldFromConcatString(fullInfo, "\\|", Constants.FIELD_CLICK_CATEGORY_IDS)
val extractSession = SessionRandomExtractModel(taskUUID, sessionId, startTime, searchKeywords, clickCategories)
extractSessionArrayBuffer += extractSession
}
index += 1
}
extractSessionArrayBuffer
}
2.4.8 写入数据库
// 8. 写入数据库
import sparkSession.implicits._
extractSessionRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.option("dbtable", "session_extract")
.mode(SaveMode.Append)
.save()
dateHour2FullInfosRDD.foreach(println(_))
需求三: 获取Top10 热门品类
3.1 需求概述
在符合条件的用户行为数据中,获取点击、下单和支付数量排名前10的品类。在Top10的排序中,按照点击数量、下单数量、支付数量的次序进行排序,即优先考虑点击数量。
3.2 简要运行流程

3.3 具体运行流程

3.4 代码实现
3.4.1 获取所有发生过点击, 付款, 订单的品类

// 1. 获取所有发生过点击/下单/付款的品类
val categoryIdRDD: RDD[(Long, Long)] = sessionId2DetailRDD.flatMap {
case (sessionId, userVisitAction) =>
val categoryBuffer = new ArrayBuffer[(Long, Long)]()
if (userVisitAction.click_category_id != -1) {
categoryBuffer += ((userVisitAction.click_category_id, userVisitAction.click_category_id))
} else if (userVisitAction.order_category_ids != null) {
val category_ids = userVisitAction.order_category_ids
val categories: Array[String] = category_ids.split(",")
for (category <- categories) {
categoryBuffer += ((category.toLong, category.toLong))
}
} else if (userVisitAction.pay_category_ids != null) {
val category_ids = userVisitAction.pay_category_ids
val categories: Array[String] = category_ids.split(",")
for (category <- categories) {
categoryBuffer += ((category.toLong, category.toLong))
}
}
categoryBuffer
}
3.4.2 去重
// 2. 去重
val distinctCategoryIdByOptRDD: RDD[(Long, Long)] = categoryIdRDD.distinct()
3.4.3 计算各个品类的点击次数, 加入订单次数, 付款次数

// 3. 计算各个品类的点击次数, 加入订单次数, 付款次数
val clickCategoryId2Count: RDD[(Long, Long)] = getClickCategoryId2CountRDD(sessionId2DetailRDD)
val orderCategoryId2Count: RDD[(Long, Long)] = getOrderCategoryId2CountRDD(sessionId2DetailRDD)
val payCategoryId2Count: RDD[(Long, Long)] = getPayCategoryId2CountRDD(sessionId2ActionRDD)
def getClickCategoryId2CountRDD(sessionId2DetailRDD: RDD[(String, UserVisitAction)]) = {
val clickCategoryRDD: RDD[(String, UserVisitAction)] = sessionId2DetailRDD.filter(item => item._2.click_category_id != -1L)
val categoryIdAndOne: RDD[(Long, Long)] = clickCategoryRDD.map {
case (sessionId, userVisitAction) =>
(userVisitAction.click_category_id, 1L)
}
val clickCategoryId2Count: RDD[(Long, Long)] = categoryIdAndOne.reduceByKey(_ + _)
clickCategoryId2Count
}
def getOrderCategoryId2CountRDD(sessionId2DetailRDD: RDD[(String, UserVisitAction)]) = {
val orderCategoryRDD = sessionId2DetailRDD.filter(item => item._2.order_category_ids != null)
val categoryIdAndOne: RDD[(Long, Long)] = orderCategoryRDD.flatMap {
case (sessionId, userVisitAction) =>
userVisitAction.order_category_ids.split(",").map(category => (category.toLong, 1L))
}
val orderCategoryId2Count: RDD[(Long, Long)] = categoryIdAndOne.reduceByKey(_ + _)
orderCategoryId2Count
}
def getPayCategoryId2CountRDD(sessionId2DetailRDD: RDD[(String, UserVisitAction)]) = {
val payCategoryRDD = sessionId2DetailRDD.filter(item => item._2.pay_category_ids != null)
val categoryIdAndOne: RDD[(Long, Long)] = payCategoryRDD.flatMap {
case (sessionId, userVisitAction) =>
userVisitAction.pay_category_ids.split(",").map(category => (category.toLong, 1L))
}
val payCategroyId2Count: RDD[(Long, Long)] = categoryIdAndOne.reduceByKey(_ + _)
payCategroyId2Count
}
3.4.4 leftJoin

// 4. leftJoin
val cid2FullCountRDD: RDD[(Long, String)] = getFullCount(distinctCategoryIdByOptRDD, clickCategoryId2Count, orderCategoryId2Count, payCategoryId2Count)
def getFullCount(distinctCategoryIdByOptRDD: RDD[(Long, Long)]
, clickCategoryId2Count: RDD[(Long, Long)]
, orderCategoryId2Count: RDD[(Long, Long)]
, payCategoryId2Count: RDD[(Long, Long)]) = {
val cid2ClickInfoRDD: RDD[(Long, String)] = distinctCategoryIdByOptRDD.leftOuterJoin(clickCategoryId2Count).map {
case (cid, (categoryId, option)) =>
val clickCount = if (option.isDefined) option.get else 0
val clickInfo = Constants.FIELD_CATEGORY_ID + "=" + categoryId + "|" + Constants.FIELD_CLICK_COUNT + "=" + clickCount
(cid, clickInfo)
}
val cid2OrderInfoRDD: RDD[(Long, String)] = cid2ClickInfoRDD.leftOuterJoin(orderCategoryId2Count).map {
case (cid, (clickInfo, option)) =>
val orderCount = if (option.isDefined) option.get else 0
val orderInfo = clickInfo + "|" + Constants.FIELD_ORDER_COUNT + "=" + orderCount
(cid, orderInfo)
}
val cid2PayInfoRDD: RDD[(Long, String)] = cid2OrderInfoRDD.leftOuterJoin(payCategoryId2Count).map {
case (cid, (orderInfo, option)) =>
val payCount = if (option.isDefined) option.get else 0
val payInfo = orderInfo + "|" + Constants.FIELD_PAY_COUNT + "=" + payCount
(cid, payInfo)
}
cid2PayInfoRDD
// (11,categoryid=11|clickCount=64|orderCount=70|payCount=120)
// (35,categoryid=35|clickCount=63|orderCount=82|payCount=140)
// (27,categoryid=27|clickCount=50|orderCount=54|payCount=133)
// (75,categoryid=75|clickCount=65|orderCount=50|payCount=135)
// (51,categoryid=51|clickCount=44|orderCount=55|payCount=148)
}
3.4.5 转换格式

// 5. 转换格式 使用封装类的方式实现自定义排序, 将需要排序的字段封装到一个case类中, 并继承 Order 实现Compare方法
val sortKey2CountInfoRDD: RDD[(SortKey, String)] = cid2FullCountRDD.map {
case (cid, countInfo) =>
val clickCount = StringUtils.getFieldFromConcatString(countInfo, "\\|", Constants.FIELD_CLICK_COUNT).toLong
val orderCount = StringUtils.getFieldFromConcatString(countInfo, "\\|", Constants.FIELD_ORDER_COUNT).toLong
val payCount = StringUtils.getFieldFromConcatString(countInfo, "\\|", Constants.FIELD_PAY_COUNT).toLong
val sortKey = SortKey(clickCount, orderCount, payCount)
(sortKey, countInfo)
}
- 自定义排序
package com.lz.session
case class SortKey(clickCount: Long, orderCount: Long, payCount: Long) extends Ordered[SortKey ]{
override def compare(that: SortKey): Int = {
if (this.clickCount - that.clickCount !=0) {
return (this.clickCount - that.clickCount) .toInt
}else if(this.orderCount - that.orderCount !=0) {
return (this.orderCount - that.clickCount).toInt
}else{
return (this.payCount - that.payCount).toInt
}
}
}
3.4.6 sortByKey 取前10
// 6. sortByKey 取前10
val top10CategoryList: Array[(SortKey, String)] = sortKey2CountInfoRDD
.sortByKey(false) // 调用key类型的compare方法
.take(10)
3.4.7 装换为RDD[Top10Category]
// 7. 装换为RDD, 且将每条数据转换为 case class -Top10Category类型
val top10CategoryRDD: RDD[Top10Category] = sparkSession.sparkContext.makeRDD(top10CategoryList).map {
case (sortkey, countInfo) =>
val cid = StringUtils.getFieldFromConcatString(countInfo, "\\|", Constants.FIELD_CATEGORY_ID).toLong
val clickCount = sortkey.clickCount
val orderCount = sortkey.orderCount
val payCount = sortkey.payCount
Top10Category(taskUUID, cid, clickCount, orderCount, payCount)
}
3.4.8 写入数据库
// 8. 写入数据库
import sparkSession.implicits._
top10CategoryRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.option("dbtable", "top10_category")
.mode(SaveMode.Append)
.save()
第四章 Top10热门品类的Top10活跃Session统计
4.1 需求概述
统计需求三中得到的Top10热门品类中的Top10活跃Session,对Top10热门品类中的每个品类都取Top10活跃Session,评判活跃Session的指标是一个Session对一个品类的点击次数。
4.2 简要运行流程

4.3 具体运行流程

4.4 代码实现
4.4.1 将top10的品类ID放入一个Array中
val cidArray: Array[Long] = top10CategoryList.map {
case (sortKey, countInfo) =>
val cid = StringUtils.getFieldFromConcatString(countInfo, "\\|", Constants.FIELD_CATEGORY_ID).toLong
cid
}
4.4.2 筛选得到点击过Top10品类的用户行为
val sessionId2Top10CatActionRDD: RDD[(String, UserVisitAction)] = sessionId2DetailRDD.filter {
case (sessionId, action) =>
cidArray.contains(action.click_category_id)
}
4.4.3 按照sessionID聚合
// 按照sessionID进行聚合
val sessionId2Top10CatActionsRDD: RDD[(String, Iterable[UserVisitAction])] = sessionId2Top10CatActionRDD.groupByKey()
4.4.4 统计每个品类中的session的点击次数

val cid2SessionIdAndCount:RDD[Long,String] = sessionId2Top10CatActionsRDD.flatMap {
case (sessionId, actions) =>
val categoryCountMap = new mutable.HashMap[Long, Long]()
for (action <- actions) {
val cid = action.click_category_id
if (!categoryCountMap.contains(cid)) {
categoryCountMap += (cid -> 0)
}
categoryCountMap.update(cid, categoryCountMap(cid) + 1)
}
for ((cid, count) <- categoryCountMap)
yield (cid, sessionId + "=" + count)
}
4.4.5 按照cid聚合

val cid2SessionIdAndCounts: RDD[(Long, Iterable[String])] = cid2SessionIdAndCount.groupByKey()
4.4.6 排序 取前十并转换格式
// 排序
val top10SessionRDD: RDD[Top10Session] = cid2SessionIdAndCounts.flatMap {
case (cid, actions) =>
// 排序
val sortList: List[String] = actions.toList.sortWith(
// true: item1放在前面
// flase: item2放在前面
(item1, item2) =>
item1.split("=")(1).toLong > item2.split("=")(1).toLong
).take(10)
// 转换格式
val top10Session: List[Top10Session] = sortList.map {
case item =>
val sessionId = item.split("=")(0)
val count = item.split("=")(1).toLong
Top10Session(taskUUID, cid, sessionId, count)
}
top10Session
}
4.4.7 入库
import sparkSession.implicits._
top10SessionRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.option("dbtable", "top10_session")
.mode(SaveMode.Append)
.save()
小结
- 关于RDD的操作, 可以看成是在操作一个本地集合, 该集合中可以存放任意类型(基本类型, 自定义类型)的数据
- 将RDD中存放的数据指定为case class
// 其中stat是SessionAggrStat这个case class的一个实例
val sessionAggrStat: RDD[SessionAggrStat] =
sparkSession.sparkContext.makeRDD(Array(stat))
//UserVisitAction 是一个Case类
val actionRDD: RDD[UserVisitAction] = sparkSession.sql(sql).as[UserVisitAction].rdd
// 转换格式
val top10Session: List[Top10Session] = sortList.map {
case item =>
val sessionId = item.split("=")(0)
val count = item.split("=")(1).toLong
Top10Session(taskUUID, cid, sessionId, count)
}
- map.get(key)中经常使用模式匹配
date2HourCount.get(date) match {
case None =>
date2HourCount(date) = new mutable.HashMap[String, Long]()
date2HourCount(date) += (hour -> count)
case Some(x) =>
date2HourCount(date) += (hour -> count)
}
- 关于集合的操作
if (!this.countMap.contains(v)) {
this.countMap += (v -> 0)
}
this.countMap.update(v, countMap(v) + 1)
hour2Index(hour) = new ListBuffer[Int]
for (i <- 0 until hourExtractSessionCount) {
var index = random.nextInt(count.toInt)
while (hour2Index(hour).contains(index)) {
index = random.nextInt(count.toInt)
}
hour2Index(hour) += index
}
- map和flatMap
// map 只能进行一对一的对象转换,而不能将对象转换成对象数组。
// map 一般用于一对一,而 flatmap 一般用于一对多或者多对多。
def getClickCategoryId2CountRDD(sessionId2DetailRDD: RDD[(String, UserVisitAction)]) = {
val clickCategoryRDD: RDD[(String, UserVisitAction)] = sessionId2DetailRDD.filter(item => item._2.click_category_id != -1L)
val categoryIdAndOne: RDD[(Long, Long)] = clickCategoryRDD.map {
case (sessionId, userVisitAction) =>
(userVisitAction.click_category_id, 1L)
}
val clickCategoryId2Count: RDD[(Long, Long)] = categoryIdAndOne.reduceByKey(_ + _)
clickCategoryId2Count
}
def getOrderCategoryId2CountRDD(sessionId2DetailRDD: RDD[(String, UserVisitAction)]) = {
val orderCategoryRDD = sessionId2DetailRDD.filter(item => item._2.order_category_ids != null)
val categoryIdAndOne: RDD[(Long, Long)] = orderCategoryRDD.flatMap {
case (sessionId, userVisitAction) =>
userVisitAction.order_category_ids.split(",").map(category => (category.toLong, 1L))
}
val orderCategoryId2Count: RDD[(Long, Long)] = categoryIdAndOne.reduceByKey(_ + _)
orderCategoryId2Count
}
- 自定义排序
让进行排序的字段, extends Ordered[caseClass], 并实现compare方法, 在compare中定义排序规则
- 单value RDD:
val sorted: RDD[caseClass] = grdd2.sortBy(s => s)- key - value RDD(排序字段做key)
sortByKey(false| true)
// 5. 转换格式 使用封装类的方式实现自定义排序, 将需要排序的字段封装到一个case类中, 并继承 Order 实现Compare方法
val sortKey2CountInfoRDD: RDD[(SortKey, String)] = cid2FullCountRDD.map {
case (cid, countInfo) =>
val clickCount = StringUtils.getFieldFromConcatString(countInfo, "\\|", Constants.FIELD_CLICK_COUNT).toLong
val orderCount = StringUtils.getFieldFromConcatString(countInfo, "\\|", Constants.FIELD_ORDER_COUNT).toLong
val payCount = StringUtils.getFieldFromConcatString(countInfo, "\\|", Constants.FIELD_PAY_COUNT).toLong
val sortKey = SortKey(clickCount, orderCount, payCount)
(sortKey, countInfo)
}
// 6. sortByKey 取前10
val top10CategoryList: Array[(SortKey, String)] = sortKey2CountInfoRDD
.sortByKey(false) // 调用key类型的compare方法
.take(10)
package com.lz.session
case class SortKey(clickCount: Long, orderCount: Long, payCount: Long) extends Ordered[SortKey ]{
override def compare(that: SortKey): Int = {
if (this.clickCount - that.clickCount !=0) {
return (this.clickCount - that.clickCount) .toInt
}else if(this.orderCount - that.orderCount !=0) {
return (this.orderCount - that.clickCount).toInt
}else{
return (this.payCount - that.payCount).toInt
}
}
}
- Join操作的转换
// 过滤出所有点击过Top10类别的action
// 1: join
// 1 Top类别ID
val cid2CountInfoRDD: RDD[(Long, String)] = sparkSession.sparkContext.makeRDD(top10CategoryList).map {
case (sortKey, countInfo) =>
val cid = StringUtils.getFieldFromConcatString(countInfo, "\\|", Constants.FIELD_CATEGORY_ID).toLong
(cid, countInfo)
}
// 2 所有用户访问信息,以Cid做为Key
val cid2ActionRDD:RDD[(Long,UserVisitAction)] = sessionId2DetailRDD.map {
case (sessionId, action) =>
val cid = action.click_category_id
(cid, action)
}
// 3 Join
val sessionId2ActionRDD:RDD[(String,UserVisitAction)] = cid2CountInfoRDD.join(cid2ActionRDD).map {
case (cid, (countInfo, action)) =>
val sid = action.session_id
(sid, action)
}
- 优化方式 : Filter
//2:
val cidArray: Array[Long] = top10CategoryList.map {
case (sortKey, countInfo) =>
val cid = StringUtils.getFieldFromConcatString(countInfo, "\\|", Constants.FIELD_CATEGORY_ID).toLong
cid
}
val sessionId2Top10CatActionRDD: RDD[(String, UserVisitAction)] = sessionId2DetailRDD.filter {
case (sessionId, action) =>
cidArray.contains(action.click_category_id)
}
- 广播变量
// 5. 广播大变量
val dateHourExtractIndexListBd: Broadcast[mutable.HashMap[String, mutable.HashMap[String, ListBuffer[Int]]]] = sparkSession.sparkContext.broadcast(date2HourRandomIndex)
// 7.1 获取广播变量的值
val extractList: ListBuffer[Int] = dateHourExtractIndexListBd.value.get(date).get(hour)
- countByKey()与reduceByKey()
countByKey()属于action,而reduceByKey()属于transformation
countByKey()得到的类型为map(是在driver端的最终结果),而reduceByKey()得到的类型是RDD
data.countByKey()相当于data.reduceByKey(+).collectAsMap()
