(1)hdfs客户端的位置
/home/hadoop/apps/hadoop-2.6.4/bin/hadoop(2)启动hdfs查看根目录
[hadoop@mini01 hadoop-2.6.4]$ hadoop fs -ls /(3)上传文件到根目录(此根目录不是Linux的根目录,是hdfs的根目录)
#先创建wenjian.txt文件,并写入内容
[hadoop@mini04 ~]$ echo "今天天气真好啊" > wenjian.txt
#上传该文件
[hadoop@mini04 ~]$ hadoop fs -put wenjian.txt /上传文件大小
hdfs最大存储文件的大小为128兆一块,因此如果上传的文件为129兆时,文件会被切成2块上传文件存储的位置
#文件存储位置
[hadoop@mini04 subdir0]$ pwd
/home/hadoop/hdpdata/dfs/data/current/BP-844605729-192.168.253.21-1524503128838/current/finalized/subdir0/subdir0
[hadoop@mini04 subdir0]$ ll
total 8
-rw-rw-r--. 1 hadoop hadoop 22 Apr 24 11:33 blk_1073741825
-rw-rw-r--. 1 hadoop hadoop 11 Apr 24 11:33 blk_1073741825_1001.meta
#blk_1073741825是刚刚上传的文件
#blk_1073741825_1001.meta是刚刚上传文件的描述信息- 查看是否上传成功:
a、命令查看
[hadoop@mini04 ~]$ hadoop fs -ls /
Found 1 items
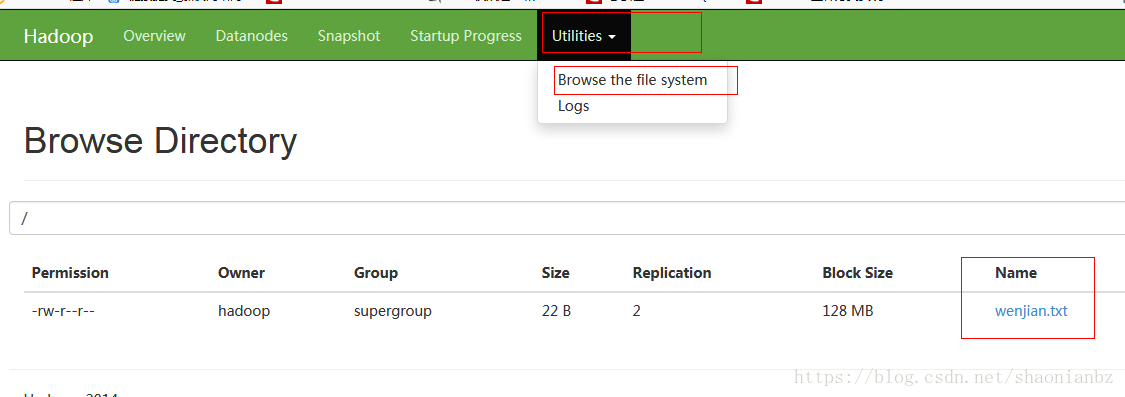
-rw-r--r-- 2 hadoop supergroup 22 2018-04-24 11:33 /wenjian.txtb、网站查看:客户端网站:http://mini01:50070
(4)文件下载
#下载文件
[hadoop@mini01 ~]$ hadoop fs -get /cenos-6.5-hadoop-2.6.4.tar.gz(5)创建文件夹
#创建wordcount文件夹
[hadoop@mini01 ~]$ hadoop fs -mkdir /wordcount
#在wordcount文件夹下创建input文件夹(没有wordcount时,加-p)
[hadoop@mini01 ~]$ hadoop fs -mkdir -p /wordcount/input(6)查看文件内容
[hadoop@mini04 ~]$ hadoop fs -cat /wenjian.txt(9)查看所有命令(查看帮助)
[hadoop@mini01 ~]$ hadoop fs(10)查看集群状态
扫描二维码关注公众号,回复:
905977 查看本文章

[hadoop@mini01 ~]$ hdfs dfsadmin -report(11)从本地剪切粘贴到hdfs
#把本地的aa.txt文件剪切到hdfs的根目录
[hadoop@mini01 ~]$ hadoop fs -moveFromLocal /home/hadoop/aa.txt /(12)对文件所属权限-chgrp, -chmod,-chown
[hadoop@mini01 ~]$ hadoop fs -chmod 777 /aa.txt(13)从本地文件系统中拷贝文件到hdfs路径去
[hadoop@mini01 ~]$ hadoop fs -copyFromLocal /home/hadoop/bb.txt /(14)从hdfs拷贝到本地
[hadoop@mini01 ~]$ hadoop fs -copyToLocal /aa.txt(15)从hdfs的一个路径拷贝hdfs的另一个路径
[hadoop@mini01 temp]$ hadoop fs -cp /aa.txt /wordcount/(16)在hdfs目录中移动文件
#把aa.txt文件移动到/temp文件夹中
[hadoop@mini01 temp]$ hadoop fs -mv /aa.txt /temp(17)删除文件或文件夹
[hadoop@mini01 temp]$ hadoop fs -rm /bb.txt(18)删除空目录
[hadoop@mini01 temp]$ hadoop fs -rmdir /kong(19)合并下载多个文件
#示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,...
[hadoop@mini01 ~]hadoop fs -getmerge /aaa/log.* ./log.sum(20)统计文件夹的大小信息
#-du命令
[hadoop@mini01 temp]$ hadoop fs -du -s /temp(21)统计一个指定目录下的文件节点数量
#-count
[hadoop@mini01 temp]$ hadoop fs -count /wordcount(22)设置hdfs中文件的副本数量
#-setrep,这里设置的副本数只是记录在namenode的元数据中,
#是否真的会有这么多副本,还得看datanode的数量
[hadoop@mini01 temp]$ hadoop fs -setrep 5 /temp
Replication 5 set: /temp/aa.txt