首先我们要理清master启动要干哪些事儿。
- 首先master得按照nMap的数量进行文件分割
- 得创建master的RPC服务并发布
- master还得监听worker状态
- 给合适的worker分发任务,指定每个worker处理哪些文件
1. master数据结构
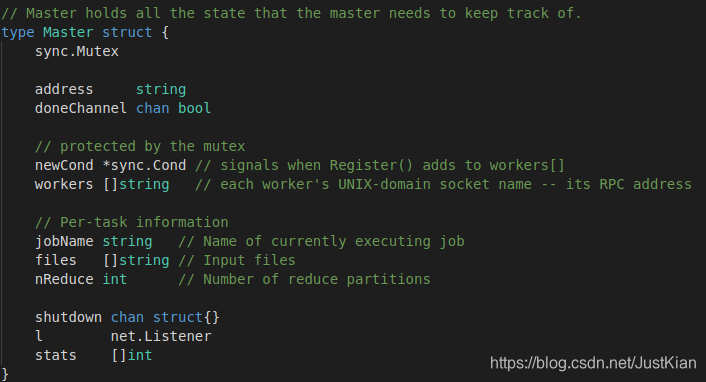
- address:master的rpc地址,当然也是socket地址(文件描述符fd)
- doneChannel:任务完成的信号通知通道
- newCond:当worker注册添加到workers时的条件信号
- workers:存储每个注册后的worker的socket地址,也可以说是rpc地址,rpc是对socket的又一层包装
- shutdown:关闭worker的信号通知通道
- l:监听worker的连接器
- status:每个worker的当前状态
2. master创建
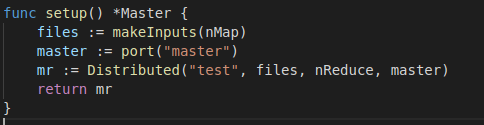
- makeInputs(nMap):按照nMap的数量进行文件分割
- master := port(“master”):声明master端口名
- mr := Distributed(“test”, files, nReduce, master):master进行分发调度的总控
2.1 Distributed详解
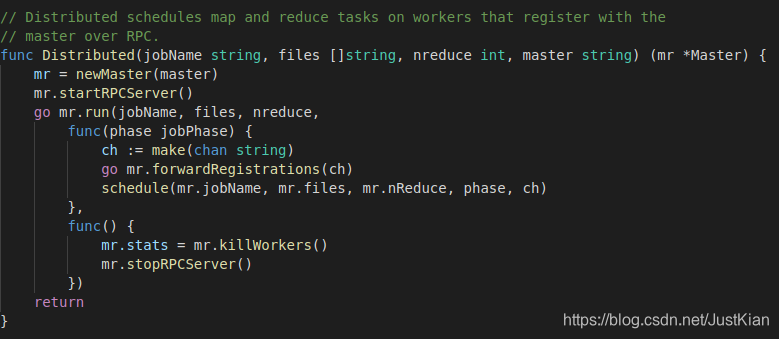
- mr = newMaster(master):用于创建master的数据结构
2.2 开启master的RPC服务
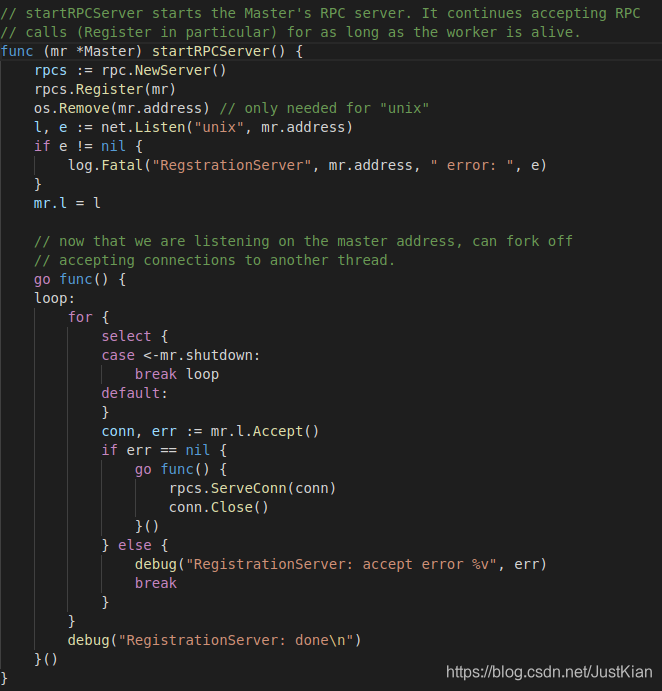
关于go的RPC,这里不做过多叙述,后面会写一篇文章专门讲一下go的rpc源码及过程分析。首先对于server端,这里主要就是master对象:
- rpcs := rpc.NewServer(): 创建一个server端的rpc对象
- rpcs.Register(mr):发布server对象(这里就是master)的调用方法,即暴露server的api供client调用
- os.Remove(mr.address) // only needed for “unix”
- l, e := net.Listen(“unix”, mr.address):创建并返回一个监听unix域(本地通信,前面socket谈到过)的socket队列的listener
- mr.l = l:将listener绑定到master上
接下来便是不断accept连接,并响应请求。 - 其中mr.l.Accept()会从socket队列中获取一个fd(即socket),然后根据fd生成一个对应file的读写流()-coon并返回。如果socket队列中没有client连接fd,则其会一直处于阻塞状态,直到等到下一个连接的到来,由于前面函数使用了go关键字,此协程遇到阻塞则会切换到其它任务上去。
所以后面可以从coon里面读取client的数据,或者向里面写入到客户端的数据,这正是我们前面socket讲的——accept返回的是客户端socket在server端分配的一个新的文件描述符fd,相当于server端是通过和这个新fd来与client通信。于是后面要传入到client的数据可以使用相应的I/O函数进行写入。
- 请求响应:conn中包含了client传递过来的一些参数,比如请求的方法名,方法参数,数据等等,rpcs.ServerConn()可以解析出对应的参数,并调用server端相应的方法去处理请求,并返回响应结果给Client,处理完毕就关闭连接。
go func() { rpcs.ServeConn(conn) conn.Close() }()
3. master如何了解worker的状态
前面mapReduce中介绍过,master必须要了解所有worker的状态信息才行,然后schedule调度器才能够通过这些worker信息(比如Worker的RPC地址,存活状态等)进行任务分配。
那这里引出了几个问题:
- 一是master如何知晓worker,并给其分发任务。—— worker注册事件
- 二是master如何获取工作中的worker信息。—— 心跳检测
- 三是何传递worker信息给schedule。—— 同步通道channel
- 四是worker如何知晓master的RPC地址。—— zookeeper
3.1 worker注册事件Register
一是master如何知晓worker,并给其分发任务。首先是master通过RPC方式暴露本地服务,然后网络中的其它woker可以通过调用master的远程服务即register,注册到master的workers数据结构中(前面说过,专门用来存储worker的RPC地址的),那接下来思考一下具体实现细节。
我们仔细思考一下,其实让master知晓已新注册的worker,可以通过设置一个newWorker数组,然后可以分为两部分程序:
-
必然其中一部分线程主要是负责监听连接,响应Register事件。我们可查看前面提到过的开启RPC那部分代码,实际上go的net.Listen()函数返回的是一个实现了netFD接口的监听器listener,在linux上Go语言写的网络服务器也是采用的epoll作为最底层的数据收发驱动,listener一方面可以一直监听socketFd队列,也可以开启另一个线程accept连接(可以看到前面代码中的loop Accept部分)就是通过一个go关键字开启了另一个无限循环的accept协程, 不断accept连接,一旦监听到某个netFD数据准备完毕,就响应处理。这里主要就是响应客户端发起的Register功能,然后在Register中可以将worker的rpc地址记录到newWorker数组中。
-
然后另外一个线程,比如schedule()可以一直轮询newWorker,查看是否有新注册的worker,有的话就给它分配任务,并从newWorker[]中移除,加入到正在工作中的doingWorker[]中。
扫描二维码关注公众号,回复: 9059040 查看本文章
-
但是我们可以想一下,如果schedule()一直轮询,会十分浪费cpu资源,更好的做法便是通过事件驱动方式来完成,只有当Register完成后,触发一个信号,才唤醒schedule()线程,其它时间schedule()都处于阻塞态,这样就不会造成schedule()一直轮询占用cpu资源,所以这自然而然的就想到了通过条件变量来实现这种事件触发功能。
-
再进一步思考一下,我们是让条件变量直接触发schedule()然后对newWorker[]进行任务分配吗?如果说在某一时刻的并发度过高,比如有很多worker发起了注册请求,那必然要使用go schedule()方式,使之成为协程,才能处理多个事件驱动响应,但是这就带了共享变量newWorker[]的同步问题,由于多个协程都要使用newWorker[],这就有可能造成某些已分配的worker还没来得及在其他协程中更新newWorker[]的状态,所以得对newWorker[]进行加锁操作,那这样虽然解决了同步问题,但是导致Register也无法及时地操作newWorker[],导致并发度大大地降低了。那我们想一下还有没有更好的方式呢?
-
那自然是有的,那就是通过channel而非共享变量newWorker[],条件变量并不直接触发schedule(),而是开启另外的协程forwardRegistrations(ch)负责将已注册的worker发送到这个channel中,然后schedule从channel中读取worker信息,这样就避免了schedule()和Register()的速度、并发度差异带来的同步问题,相当于中间通过一个channel完成了解耦,这样Register还是可以不断地signal,然后forwardRegistrations()不断地传递worker地址到channel中,schedule()不断地从channel中读取worker信息并分配任务。
-
下面就是代码实现部分:
// Distributed schedules map and reduce tasks on workers that register with the // master over RPC. func Distributed(jobName string, files []string, nreduce int, master string) (mr *Master) { mr = newMaster(master) mr.startRPCServer() go mr.run(jobName, files, nreduce, func(phase jobPhase) { ch := make(chan string) go mr.forwardRegistrations(ch) schedule(mr.jobName, mr.files, mr.nReduce, phase, ch) }, func() { mr.stats = mr.killWorkers() mr.stopRPCServer() }) return }// helper function that sends information about all existing // and newly registered workers to channel ch. schedule() // reads ch to learn about workers. func (mr *Master) forwardRegistrations(ch chan string) { i := 0 for { mr.Lock() if len(mr.workers) > i { // there's a worker that we haven't told schedule() about. w := mr.workers[i] go func() { ch <- w }() // send without holding the lock. i = i + 1 } else { // wait for Register() to add an entry to workers[] // in response to an RPC from a new worker. mr.newCond.Wait() } mr.Unlock() } }
一是master如何获取工作中的worker信息,MapReduce是采用心跳方式(一个定时轮询任务),每隔一段时间,master都会向worker发送一个心跳,查看他们的状态,worker收到之后马上返回自己当前的状态。
二是如何传递worker信息,因为要同时给很多worker分发任务,而有些worker的状态还没来得更新,这时如果schedule直接从workers[]中获取worker的话势必会造成同步问题,为了解决这个同步问题,于是采用了channel通道方式,每次有新的闲置worker都会发送到这个channel(registerChan)中,然后schedule从这个channel中去获取worker,这样就不会产生同步问题了。
go mr.run(jobName, files, nreduce,
func(phase jobPhase) {
//创建一个ch通道,专门用来传输已注册的worker的信息
ch := make(chan string)
//传输已注册的workers信息到ch中
go mr.forwardRegistrations(ch)
//具体的任务调度方式
schedule(mr.jobName, mr.files, mr.nReduce, phase, ch)
},
func() {
mr.stats = mr.killWorkers()
mr.stopRPCServer()
})
return
