close函数,write函数,read函数,API调用时的正规写法
close函数
功能
关闭打开的文件。
close(fd); fd即为文件描述符
就算不主动的调用close函数关闭打开的文件,进程结束时,也会自动关闭进程所打开的所有的文件。但是如果因为某种需求,你需要在进程结束之前关闭文件的话,就主动的调用close函数来实现。
Linux c库的标准io函数fclose,向下调用时,调用就是close系统函数。
close关闭文件时做了什么
①open打开文件时,会在进程的task_struct结构中,创建相应的结构体,以存放打开文件的相关信息。
②open函数会通过调用类似malloc的函数,在内存中开辟相应的结构体空间,如果文件被关闭,存放该文件被打开时信息的结构体空间,就必须被释放
不过malloc和free是给C应用程序调用的库函数,Linux系统内部开辟和释放空间时,用的是自己特有的函数。如果不释放当前进程的内存空间,会被一堆的垃圾信息所占用,随后会导致进程崩溃,甚至是Linux系统的崩溃
这就好比一个挺大的仓库,每次废弃的物品都不及时清理,最后整个空间全被垃圾塞满,仓库还是那个仓库,但是仓库瘫痪了,无法被正常使用。
因此close文件时,会做一件非常重要的事情,释放存放文件打开信息的结构体空间。
task_stuct结构体
这个结构体用于存放进程在运行的过程中,所涉及到的各种信息,其中就包括进程所打开文件的相关信息。进程(程序)开始运行时,由Linux系统调用自己的系统函数,在内存中开辟的,代码定义个各种变量(int a、数组、结构体、对象等),开辟这些空间时,这些空间都是来自于内存。每一个进程都有一个自己的task_stuct结构体,用于记录自己的所有相关信息。
这就好比每一个人,在公安局都有一份属于自己的档案信息,task_stuct结构体记录的就是,进程在活着时的一切档案信息。
进程运行结束了,Linux系统会调用自己的系统函数,释放这个结构体空间,如果不释放的话,每运行一个进程就开辟一个,但是进程结束后都不释放,最后会导致Linux系统自己的内存空间不足,从而使得整个Linux系统崩溃。
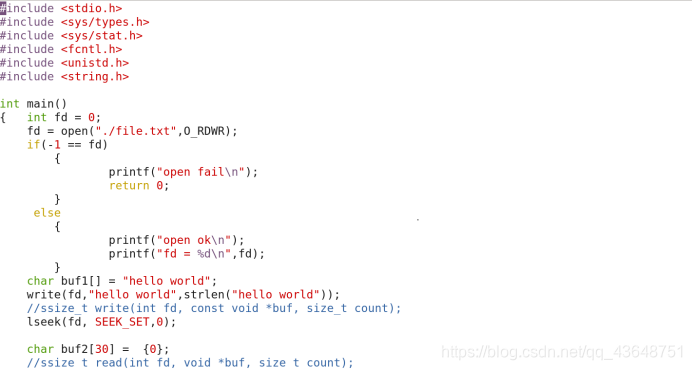
write函数
函数原型
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
功能:向fd所指向的文件写入数据。
参数:
1)fd:指向打开的文件
2)buf:保存数据的缓存空间的起始地址
3)count:从起地址开始算起,把缓存中count个字符,写入fd指向的文件
数据中转的过程:
应用缓存(buf)————>open打开文件时开辟的内核缓存—————>驱动程序的缓存——————>块设备上的文件
返回值:
调用成功:返回所写的字符个数调用失败:返回-1,并给errno自动设置错误号,使用perror这样的函数,就可以自动的将errno中的错误号翻译为文字。
使用write函数
我们之前已经使用过write函数。只不过没有进行详细的说明,在这里我们对于参数,返回值等信息进行说明之后进行如下使用:


执行结果为:
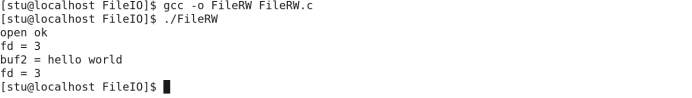
我们上面的代码包括写入文件,文件指针指向文件开头,从文件中读取数据并打印的操作,这个代码我们在之前进行使用过,在这里进行详细说明。写入文件的这个过程是不断从数组缓存中取出来放到文件缓存中。
如果使用write(fd, buf+1, 10),写入时,是一个什么情况?
执行结果为:

指针+1 则从开始位置向后移动一个 及就是 e的位置开始,之所以把大小写成10 并不是说写成11不能读取到,而是因为写成10 避免数组越界。
write(fd, “hello world”, strlen(“hello world”)),直接写字符串,可不可以?
我们修改之后执行结果为:
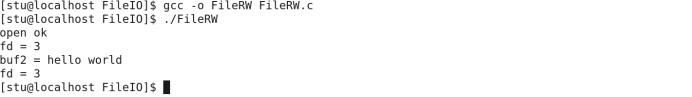
仍然是可以的。
为什么直接写字符串可以?
char buf[] = "hello world";
write(fd, buf, 11));
像这种情况,字符串直接缓存在了应用空间buf中,buf代表的数组第一个元素h所在空间的地址。直接写字符串常量时,字符串常量被保存(缓存)在了常量区,编译器在翻译如下这句话时,write(fd, “hello world”, strlen(“hello world”))会直接将"hello world"翻译为,"hello world"所存放空间的起始地址(也就是h所在字节的地址),换句话说,直接使用使用字符串常量时,字符串常量代表的其实是一个起始地址。
strlen(“hello world”)时,其实就是把起始地址传给了strlen函数。
有关这个内容,实际上是c语言的基本知识,这里只是简单的介绍下,不清楚的同学,可以到C语言分类专栏进行查看。
接下来我们思考:
write(fd, “hello world”+1, 10),写入文件的又是什么样的内容。
执行结果为:
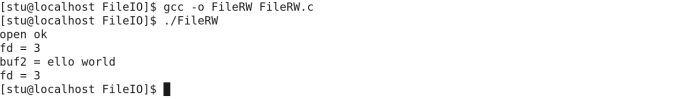
也是没有问题的,"hello world"表示的是第一个字节(h所在字节)的地址,+1就是向后移动一个字节。
read函数
函数原型
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
功能:从fd指向的文件中,将数据读到应用缓存buf中
参数:
1)fd:指向打开的文件
2)buf:读取到数据后,用于存放数据的应用缓存的起始地址
3)count:缓存大小(字节数)
返回值:
1)成功:返回读取到的字符的个数
2)失败:返回-1,并自动将错误号设置给errno。
数据中转的过程:
应用缓存(buf)<————open打开文件时开辟的内核缓存<——————驱动程序的缓存<——————块设备上的文件
使用read函数
代码演示


如果把其中的代码改成
char buf[30];
read(fd, buf+3, 11);
会是什么样的效果?
猜测的话,数据从buf[3]开始存放,一直放到buf[14].
我们进行验证:
执行结果为:

没有读取到,因为从buf[3]开始存放,我们的buf[0]、buf[1]、buf[2]放的都是0,在字符串中就是\0在字符串中就代表的是字符串结束。
那么我们可以使用循环从buf[3]开始打印:

执行结果为:

通过循环读取到没有问题。
API调用时的正规写法
当函数调用失败后,为了能够快速准确的排查错误,原则上来说,应该对所有的函数都进行错误处理(错误打印)。
不过为了后续的方便,除非非常必要,否则在我们写的测试代码中,就不进行错误检测了。
