(请观看本人博文——《详解 内存操作流》)
字节内存操作流:
首先,本人来讲解下 输出流(ByteArrayOutputStream 类):
ByteArrayOutputStream:
(输出流)
概述:
此类实现了一个输出流,其中的数据被写入一个 byte 数组。
缓冲区会随着数据的不断写入而自动增长。
可使用 toByteArray() 和 toString() 获取数据。
关闭 ByteArrayOutputStream 无效。
此类中的方法在关闭此流后仍可被调用,而不会产生任何 IOException。
那么,本人来展示下这个类的构造方法:
构造方法:
- ByteArrayOutputStream()
创建一个新的 byte 数组输出流- ByteArrayOutputStream(int size)
创建一个新的 byte 数组输出流,它具有指定大小的缓冲区容量(以字节为单位)
现在,本人来展示下这个类的常用API:
常用API:
- void close()
关闭 ByteArrayOutputStream 无效- void reset()
将此 byte 数组输出流的 count 字段重置为零,从而丢弃输出流中目前已累积的所有输出- int size()
返回缓冲区的当前大小- byte[] toByteArray()
创建一个新分配的 byte 数组- String toString()
使用平台默认的字符集,通过解码字节将缓冲区内容转换为字符串- String toString(String charsetName)
使用指定的 charsetName,通过解码字节将缓冲区内容转换为字符串- void write(byte[] b, int off, int len)
将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此 byte 数组输出流- void write(int b)
将指定的字节写入此 byte 数组输出流- void writeTo(OutputStream out)
将此 byte 数组输出流的全部内容写入到指定的输出流参数中,这与使用 out.write(buf, 0, count) 调用该输出流的 write 方法效果一样- public void flush()
刷新此输出流并强制写出所有缓冲的输出字节String toString(int hibyte)
已过时。 此方法无法将字节正确转换为字符。从 JDK 1.1 开始,完成该转换的首选方法是通过 toString(String enc) 方法(使用一个编码名称参数),或 toString() 方法(使用平台的默认字符编码)
那么,现在,本人再来展示下此流的 输入流(ByteArrayInputStream 类):
ByteArrayInputStream 类:
(输入流)
概述:
ByteArrayInputStream 包含一个内部缓冲区,该缓冲区包含从流中读取的字节。
内部计数器跟踪 read 方法要提供的下一个字节。
关闭 ByteArrayInputStream 无效。
此类中的方法在关闭此流后仍可被调用,而不会产生任何 IOException。
那么,现在,本人来展示下这个类的 构造方法:
构造方法:
- ByteArrayInputStream(byte[] buf)
创建一个 ByteArrayInputStream,使用 buf 作为其缓冲区数组。- ByteArrayInputStream(byte[] buf, int offset, int length)
创建 ByteArrayInputStream,使用 buf 作为其缓冲区数组
现在,本人来展示下这个类的常用API:
常用API:
- int available()
返回可从此输入流读取(或跳过)的剩余字节数。- void close()
关闭 ByteArrayInputStream 无效。- void mark(int readAheadLimit)
设置流中的当前标记位置。- boolean markSupported()
测试此 InputStream 是否支持 mark/reset。- int read()
从此输入流中读取下一个数据字节。- int read(byte[] b, int off, int len)
将最多 len 个数据字节从此输入流读入 byte 数组。- void reset()
将缓冲区的位置重置为标记位置。- long skip(long n)
从此输入流中跳过 n 个输入字节
那么,现在,本人就通过一个例子,来展示下这个流的使用:
例:右转哥有一天在网上下载了一部电影,这部电影分为 上、下 两部,但是他朋友也想看,就叫右转哥把两部电影剪辑成一部电影发给他。但是对右转哥来说,根本不会剪辑电影。之后,右转哥想到了字节内存操作流的知识点,他灵机一动,有了解决方案。请编程实现两部电影的合并。
要求:将两个.mp4文件合并成一个.mp4文件。
本人现在来展示下代码:
package edu.youzg.about_io.about_file.core.Test;
import java.io.*;
import java.util.ArrayList;
public class Test {
public static void main(String[] args) throws IOException {
FileInputStream in1 = new FileInputStream("妇联 上.mp4");
FileInputStream in2 = new FileInputStream("妇联 下.mp4");
FileOutputStream out = new FileOutputStream("妇联 玩整版.mp4");
ByteArrayOutputStream byteOut = new ByteArrayOutputStream();
//创建一个集合
ArrayList<FileInputStream> list = new ArrayList<>();
list.add(in1);
list.add(in2);
int len=0;
byte[] bytes = new byte[1024 * 8];
for (FileInputStream in : list) {
while ((len=in.read(bytes))!=-1){
byteOut.write(bytes,0,len);
byteOut.flush();
}
in.close();
}
//取出两部电影的字节数据
byte[] allBytes = byteOut.toByteArray();
//将两部电影的字节数据,写到硬盘上
ByteArrayInputStream byteIn = new ByteArrayInputStream(allBytes);
int len2 = 0;
byte[] bytes2 = new byte[1024 * 8];
while ((len2 = byteIn.read(bytes)) != -1) {
out.write(bytes, 0, len2);
out.flush();
}
//释放资源
out.close();
}
}
现在,本人来展示下源文件信息:
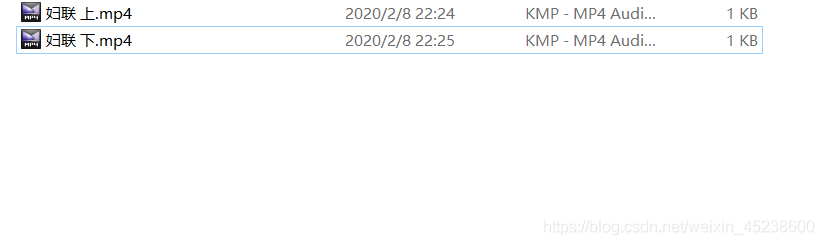
现在,本人再来展示下生成文件的信息:
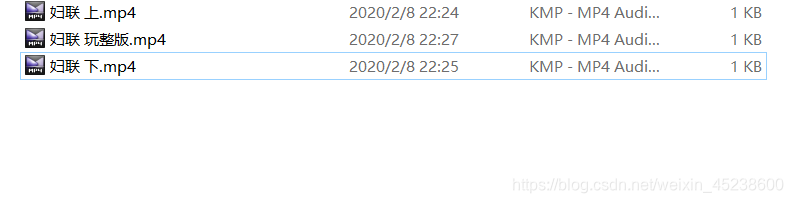
那么,可以看到,两个.mp4文件完成了合并的操作。
那么,有关 字节内存操作流 的所有知识点就讲解完了。
(本人《详解 内存操作流》博文链接:https://blog.csdn.net/weixin_45238600/article/details/104228655)
(本人《详解 字节流》博文链接:https://blog.csdn.net/weixin_45238600/article/details/104170259)
(本人“I/O流”总集篇博文链接:https://blog.csdn.net/weixin_45238600/article/details/104153031)
