今天自己上网爬取了关于新型肺炎的疫情
程序为:
import requests
import re
import json
import time
import csv
import datetime
import os
time1 = datetime.datetime.now().strftime('%Y-%m-%d %H.%M.%S')
# print(time1) 记录爬取数据时电脑的时间
def mkdir(path):
# 引入模块
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
os.makedirs(path)
path + ' 创建成功'
return True
else:
# 如果目录存在则不创建,并提示目录已存在
path + ' 目录已存在'
return False
time1 = datetime.datetime.now().strftime('%Y-%m-%d %H.%M.%S')
# 定义要创建的目录
mkpath = "C:\\Users\赵\\Desktop\\pachong\\"+time1+""
# 调用函数
mkdir(mkpath)
mkpath=mkpath+"\\"
url = 'https://service-f9fjwngp-1252021671.bj.apigw.tencentcs.com/release/pneumonia'
html = requests.get(url).text
unicodestr=json.loads(html) #将string转化为dict
dat = unicodestr["data"].get("statistics")["modifyTime"] #获取data中的内容,取出的内容为str
timeArray = time.localtime(dat/1000)
formatTime = time.strftime("%Y-%m-%d %H:%M", timeArray)
new_list = unicodestr.get("data").get("listByArea") #获取data中的内容,取出的内容为str
j = 0
print("###############"
"& 数据来源:丁香医生 "
"###############")
while j < len(new_list):
a = new_list[j]["cities"]
s = new_list[j]["provinceName"]
header = ['时间', '城市', '确诊人数', '疑似病例', '死亡人数', '治愈人数' ]
with open('./'+s+'.csv', encoding='utf-8-sig', mode='w',newline='') as f:
#编码utf-8后加-sig可解决csv中文写入乱码问题
f_csv = csv.writer(f)
f_csv.writerow(header)
f.close()
def save_data(data):
with open(mkpath+s+'.csv', encoding='UTF-8', mode='a+',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(data)
f.close()
b = len(a)
i = 0
while i<b:
data = (formatTime)
confirm = (a[i]['confirmed'])
city = (a[i]['cityName'])
suspect = (a[i]['suspected'])
dead = (a[i]['dead'])
heal = (a[i]['cured'])
i+=1
tap = (data, city, confirm, suspect, dead, heal)
save_data(tap)
j += 1
print(s+"下载结束!")
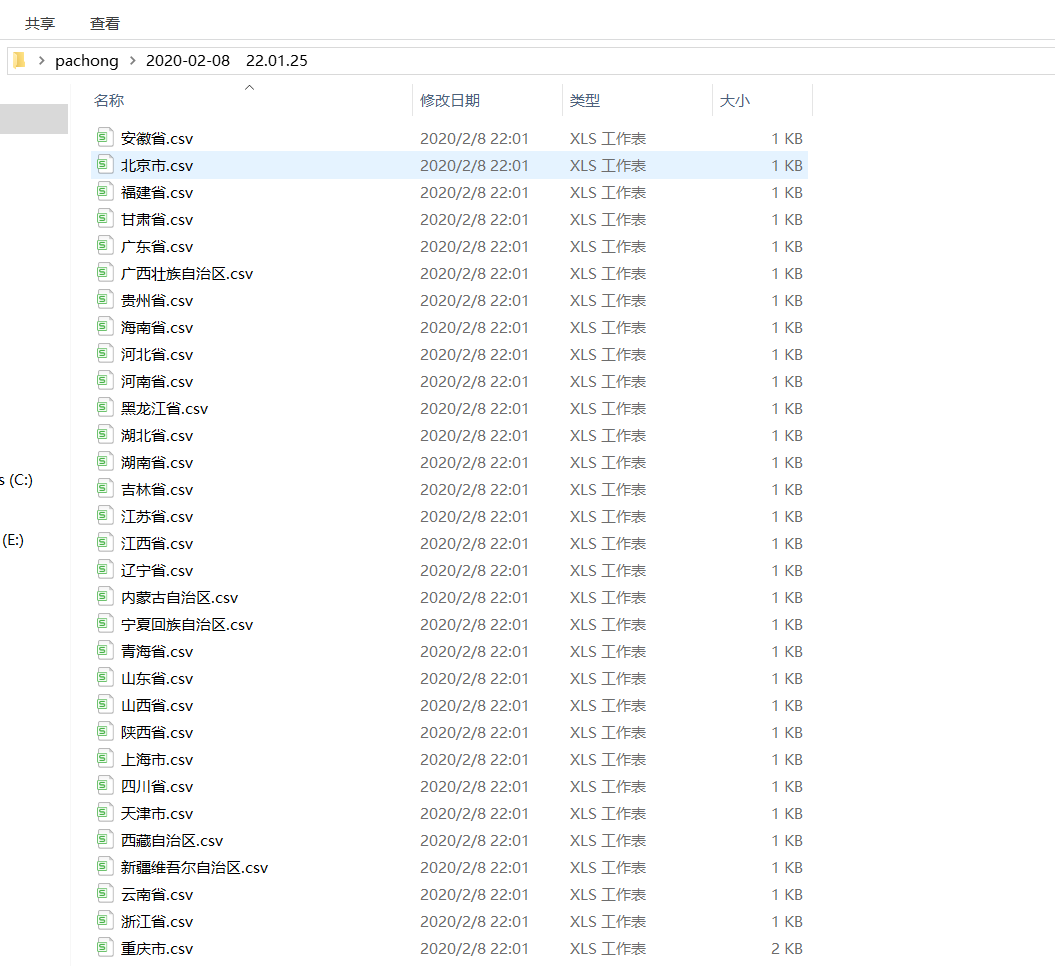
结果为:
每一个文件夹下都有对应的csv文件: