| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | 作业链接 |
| 这个作业的目标 | 写一个小项目 |
| 作业正文 | |
| 其他参考文献 |
Github
https://github.com/Mauue/InfectStatistic-main
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | |
| - Estimate | 估计这个任务需要多少时间 | 10 | |
| Development | 开发 | 310 | |
| - Analysis | 需求分析 (包括学习新技术) | 30 | |
| - Design Spec | 生成设计文档 | 10 | |
| - Design Review | 设计复审 | 5 | |
| - Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 5 | |
| - Design | 具体设计 | 10 | |
| - Coding | 具体编码 | 120 | |
| - Code Review | 代码复审 | 10 | |
| - Test | 测试(自我测试,修改代码,提交修改) | 120 | |
| Reporting | 报告 | 45 | |
| - Test Repor | 测试报告 | 30 | |
| - Size Measurement | 计算工作量 | 5 | |
| - Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | |
| 合计 | 365 |
解题思路
本项目使用Python3.7
由于需求文档足够清晰,看完之后我就把整体结构构思完了,把项目分成以下三个部分
1.解析命令行参数
该项因为之前没写过,所以单独列出来。刚开始查阅资料后,找到了个看似可以的模块 getopt模块。但是仔细阅读需求文档发现,需求是解析list子命令,getopt好像不能解析子命令,查阅了官方文档也没看见。不过官方文档里给出了另一条路:
The getopt module is a parser for command line options whose API is designed to be familiar to users of the C getopt() function. Users who are unfamiliar with the C getopt() function or who would like to write less code and get better help and error messages should consider using the argparse module instead.
于是就采用了argparse模块
之后对着文档操作了一波,能顺利执行下去,此部分暂告一段落。
2.解析日志文件
对txt日志文件进行解析
该日志中出现以下几种情况:
1、 <省> 新增 感染患者 n人
2、 <省> 新增 疑似患者 n人
3、 <省1> 感染患者 流入 <省2> n人
4、 <省1> 疑似患者 流入 <省2> n人
5、 <省> 死亡 n人
6、 <省> 治愈 n人
7、 <省> 疑似患者 确诊感染 n人
8、 <省> 排除 疑似患者 n人
看的这段话后第一反应就是用正则,想了想应该是可行的,此部分就先这样。
3.计算并输出具体数据
将上一部分的解析结果存储起来,按照要求输出出去,似乎没什么复杂的地方。
设计实现过程
按照上一部分的内容,设计出以下逻辑图

代码说明
程序的关键是对日志进行处理。
首先设计数据结构
def _new_province(self, province):
self.data.update({province: {"ip": 0, "sp": 0, "cure": 0, "dead": 0}})数据按照省份的四项数据进行存储
之后是数据处理函数
def _add_people(self, province, num, _type, _sub=False):
num = -int(num) if _sub else int(num)
if province not in self.data:
self._new_province(province)
self.data[province][_type] += num操作的最小步骤为某一省份的某一数据增加或减少一定数量,所以设计了以上函数来处理。
解析日志的函数如下
def _parse_line(self, line):
if line.startswith('//'):
return
_patterns = [
('(.*?) 新增 感染患者 ([0-9]+)人', (((1, 2), 'ip', False),)),
('(.*?) 新增 疑似患者 ([0-9]+)人', (((1, 2), 'sp', False),)),
('(.*?) 感染患者 流入 (.*?) ([0-9]+)人', (((1, 3), 'ip', True), ((2, 3), 'ip', False))),
('(.*?) 疑似患者 流入 (.*?) ([0-9]+)人', (((1, 3), 'sp', True), ((2, 3), 'sp', False))),
('(.*?) 死亡 ([0-9]+)人', (((1, 2), 'dead', False), ((1, 2), 'ip', True))),
('(.*?) 治愈 ([0-9]+)人', (((1, 2), 'cure', False), ((1, 2), 'ip', True))),
('(.*?) 疑似患者 确诊感染 ([0-9]+)人', (((1, 2), 'sp', True), ((1, 2), 'ip', False))),
('(.*?) 排除 疑似患者 ([0-9]+)人', (((1, 2), 'sp', True),)),
]
for _pattern, _args_list in _patterns:
result = re.match(_pattern, line)
if result:
for _args in _args_list:
index, _type, _sub = _args
province, num = result.group(*index)
self._add_people(province, num, _type, _sub)
return通过匹配正则表达式来解析日志的数据,若之后出现其他的日志格式也可以直接在这添加一行语句,无需额外操作。
以上就是程序解析日志的部分,也是关键部分。
其他部分个人认为较为简单,不再列出
单元测试
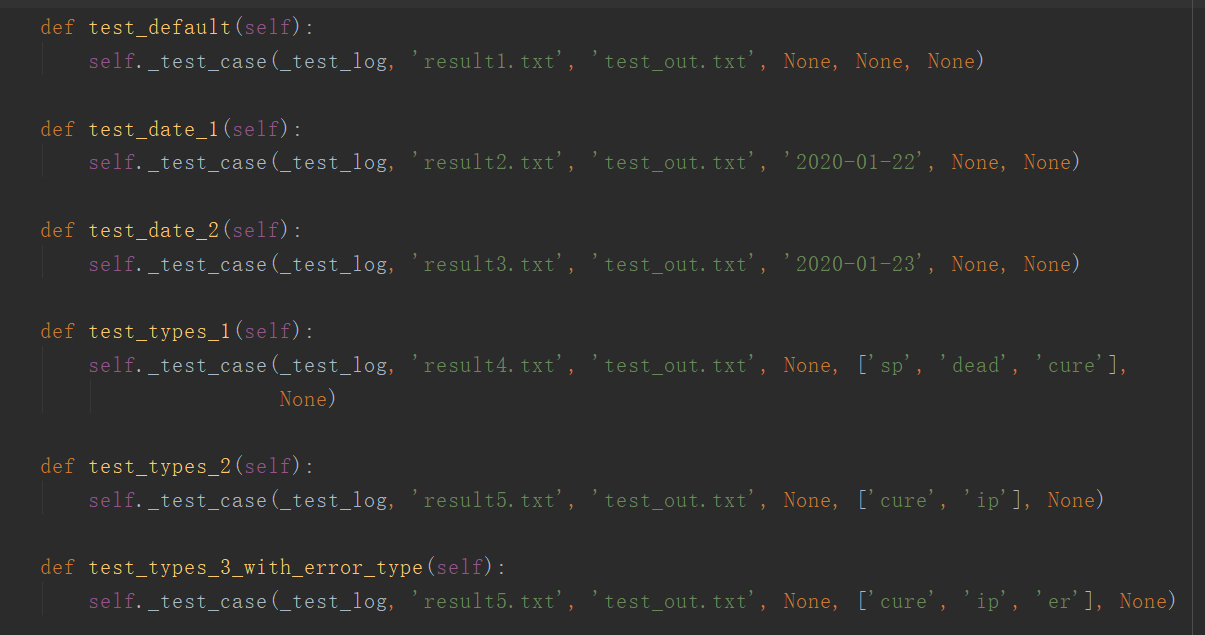
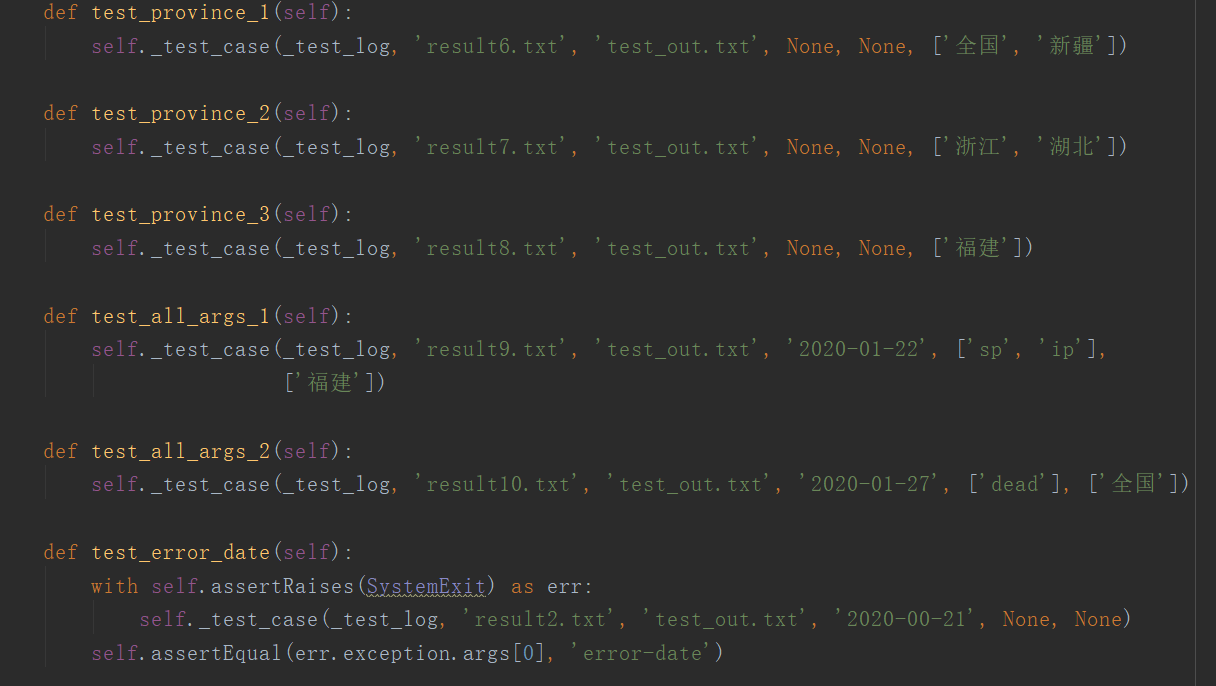
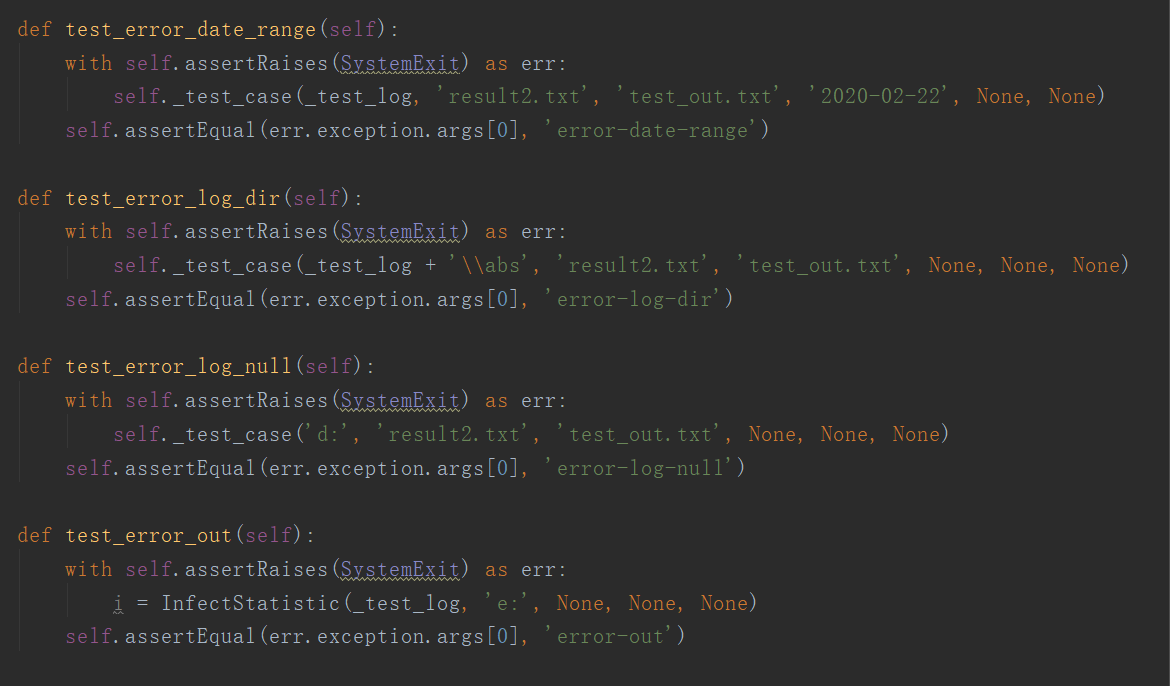
我设计了16种测试用例来测试代码,测试通过逐行比较输出文件来检测结果的正确性。
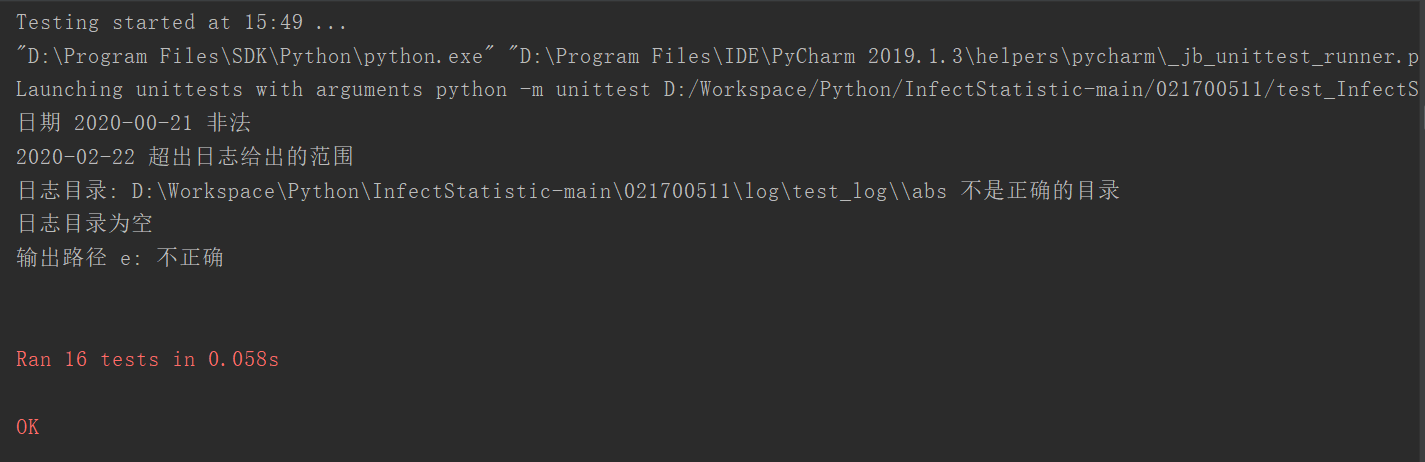
测试结果如下,:
覆盖率和性能测试
覆盖率
除主程序入口和解析参数外 其余代码全部覆盖。

性能测试
- 按时间排序

耗时较长的基本都是文件io和正则匹配。
- 按次数排序

次数最多的是读字典,除掉有异常时的测试用例,平均每个用例调用了500-600次,因为主数据的存储方式就是字典,我也不知道这个数字是不是正常的,感觉上是多了
于是我选择了测试用例一(也就是默认读取所有log 输出所有数据的用例),分别在单元测试和主程序直接运行对比了下
单元测试:

主程序直接运行:

显然,在单元测试下会与实际运行在某些函数会产生极大的误差。抓到内鬼了。98次的读取那绝对是正常的水平。
但我紧接着又发现一个问题,无论是哪种运行方式,调用次数最多的都是<method 'append' of 'list' objects>(主程序直接运行那张图没截全),分别是1279和1777次,单独看好像问题不大,但是回头看看16个测试用例总的调用此函数的次数是1859次。这就问题大了,