ES的索引的建立过程通常是先建立索引,然后添加mapping关系,最后进行POST,PUT,GET等操作。那么filebeat以及logstash和ES交互的时候mapping关系是怎么定义呢?
先说说filebeat,之前提到过,这个东西是个采集器,虽然也有output功能,但是由于没有拆分字段的能力(module功能是否可以拆分还有待确定, 暂时没也打算去用这个功能),因此采集到的日志一行就是一个message, 实际上也就不存在字段mapping概念。但是问题是,偏偏filebeat需要mapping模板,这个地方我理解不了,我思考了很久,ES本身支持动态插入,根本无需mapping, filebeat把一行直接插入到ES即可,字段默认就用message, 额外的字段,比如@timestamp 插入也行,不插入也无所谓,想怎么处理filebeat定义好就行了。因为这个原因,我也不会打算去用filebeat的output功能。
logstash的mapping有3种方法,1. 动态插入,通过grok拆分字段,然后定义字段名称,插入的时候根据定义的字段名字插入到ES中,由于没有事先定义mapping, 因此字段类型由ES自己判断,很显然这个地方会有很大误差,比如IP地址有可能为TEXT, 或者int类型也为text。 2. 定义模板,并在output的时候通过template来指定模板。3. 自己建立索引,并设置 mapping关系,logstash配置中不使用任何模板。
我个人比较倾向使用第3种方法,因为定义模板的时间,我已经更新了索引的mapping, 又何必去用模板? 接下来演示一下2者区别,我先自己定义mapping关系来采集,然后再测试动态插入。
1. 自己定义mapping关系,为了便于区分,关注start_time字段即可,我这里定义为date,这样在做展示的时候,可以通过这个时间来排序
{
"mappings" : {
"doc" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"appid" : {
"type" : "long"
},
"beat" : {
"properties" : {
"hostname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"db" : {
"type" : "keyword"
},
"host" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"last_insert_id" : {
"type" : "long"
},
"lock_time" : {
"type" : "text"
},
"message" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"offset" : {
"type" : "long"
},
"prospector" : {
"properties" : {
"type" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"query_time" : {
"type" : "text"
},
"rows_examined" : {
"type" : "long"
},
"rows_sent" : {
"type" : "long"
},
"server_id" : {
"type" : "long"
},
"source" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"sql_text" : {
"type" : "text"
},
"start_time" : {
"type" : "date",
"format" : "yyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"time" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"type" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"user_host" : {
"type" : "text"
}
}
}
}
}
通过plugin-head工具添加索引,再更新mapping.
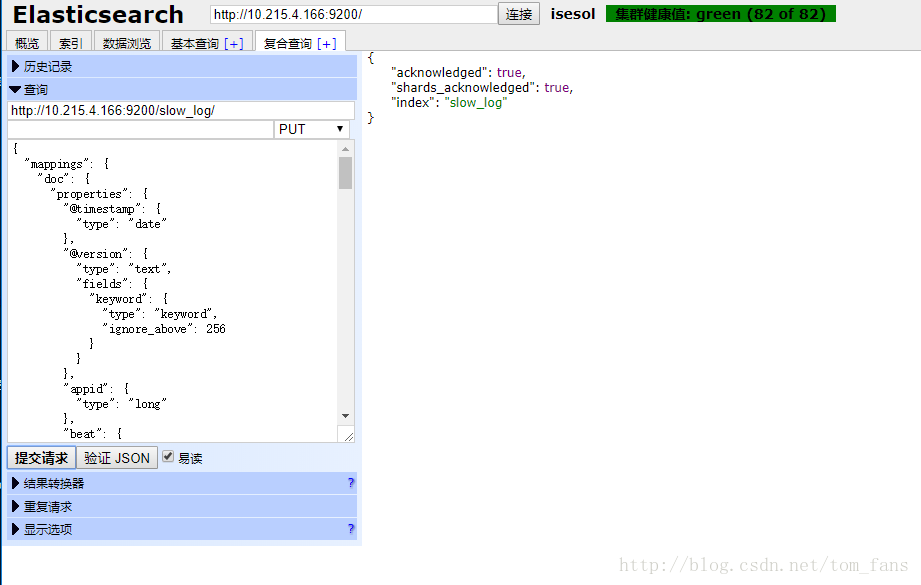
然后开始启动filebeat, logstash 来采集数据。logstash配置如下:
input {
beats {
type => "slowlog"
port => "5044"
}
beats {
type => "nginx"
port => "5045"
}
}
filter {
if [type] == "slowlog" {
grok {
match => {
"message" => "\"(?<start_time>%{YEAR}[./-]%{MONTHNUM}[./-]%{MONTHDAY}[- ]%{TIME}).(?<time>.*)\",\"(?<user_host>.*)\",\"(?<query_time>.*)\",\"(?<lock_time>.*)\",%{INT:rows_sent},%{INT:rows_examined},\"(?<db>.*)\",%{INT:last_insert_id},%{INT:insert_id},%{INT:server_id},\"(?<sql_text>.*)\",%{INT:thread_id}"
}
}
mutate {
remove_field => "thread_id"
}
mutate {
remove_field => "insert_id"
}
date {
match => ["start_time", "YYYY-MM-DD HH:mm:ss"]
}
} else {
grok {
match => {
"message" => "\"(?<start_time>%{YEAR}[./-]%{MONTHNUM}[./-]%{MONTHDAY}[- ]%{TIME}).(?<time>.*)\",\"(?<user_host>.*)\",\"(?<query_time>.*)\",\"(?<lock_time>.*)\",%{INT:rows_sent},%{INT:rows_examined},\"(?<db>.*)\",%{INT:last_insert_id},%{INT:insert_id},%{INT:server_id},\"(?<sql_text>.*)\",%{INT:thread_id}"
}
}
}
}
output {
if [type] == "slowlog" {
elasticsearch {
hosts => ["10.215.4.166:9200", "10.215.4.167:9200"]
index => "slow_log"
}
} else {
elasticsearch {
hosts => ["10.215.4.166:9200", "10.215.4.167:9200"]
index => "slowlog"
}
}
}
数据已经进入:
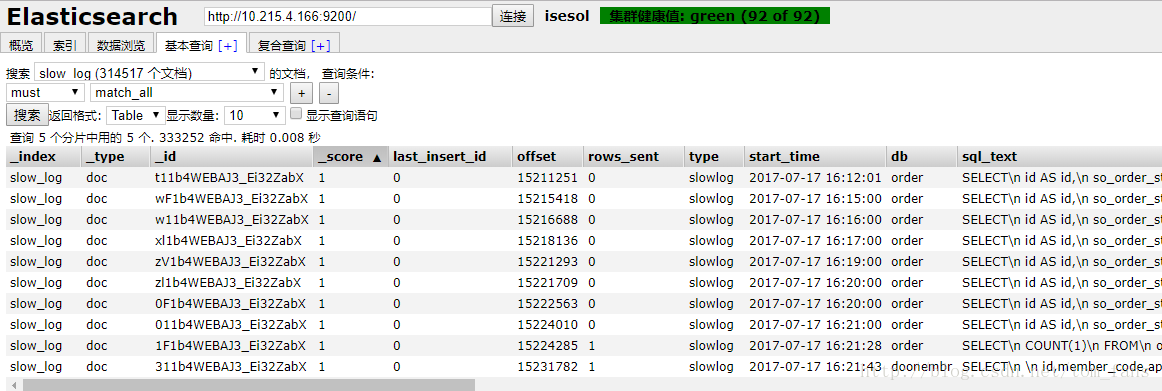
2. 测试动态插入,我什么也不干,索引不建立,mapping 不设置,模板也不提供,看看动态插入结果如何。
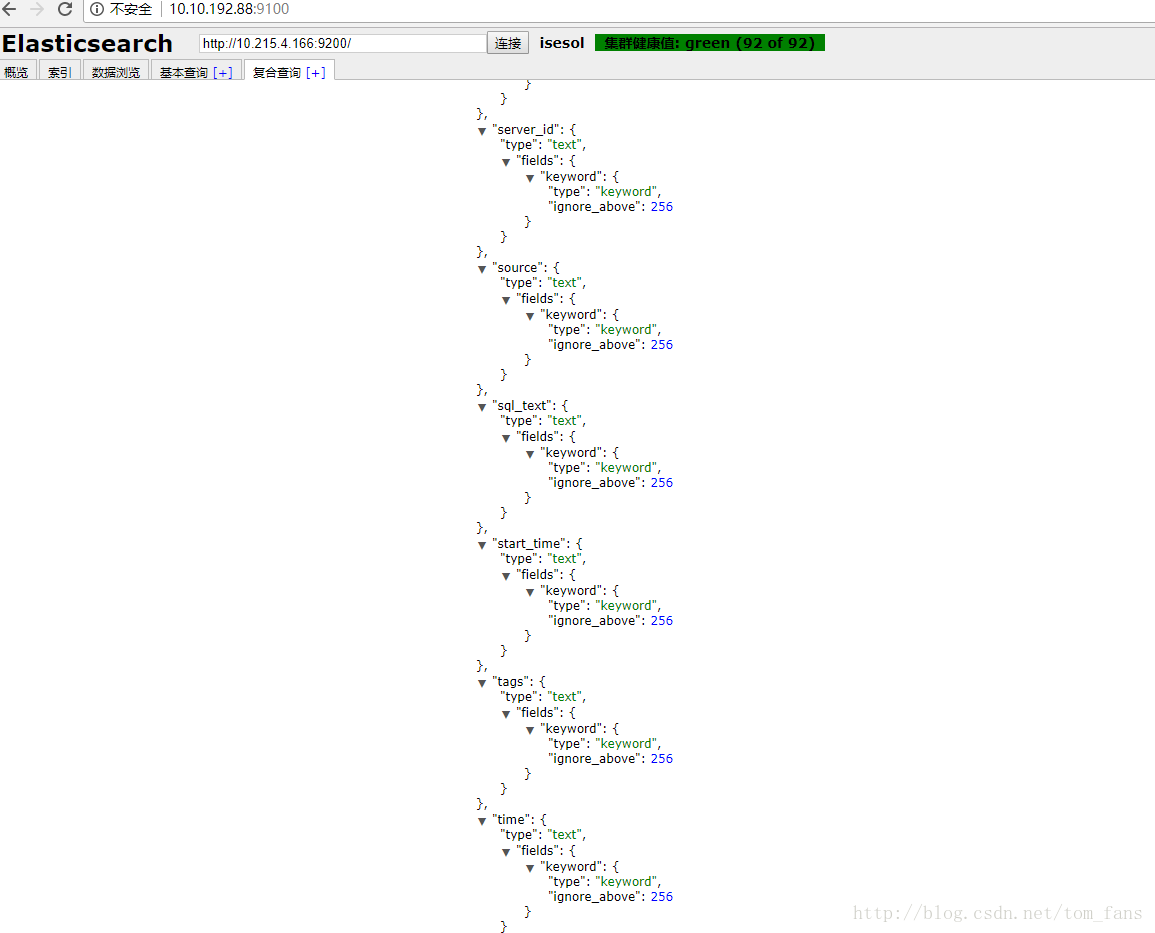
上面动态插入的start_time是text,不属于date了,就连server_id这种明显是int类型的也定义为text了。关于模板方式就不测试了,我觉得模板毫无意义。